Downloaded 59 times




























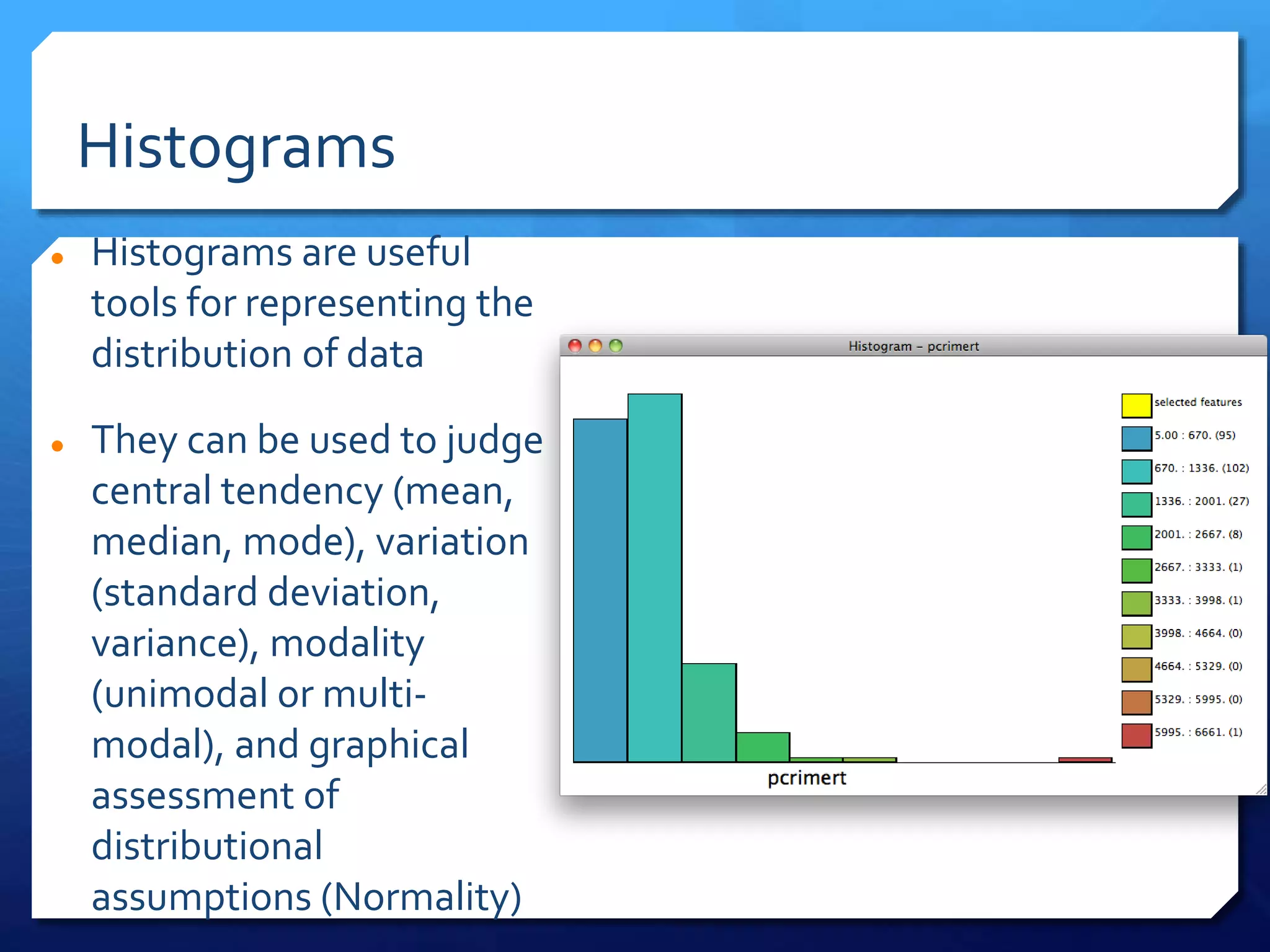

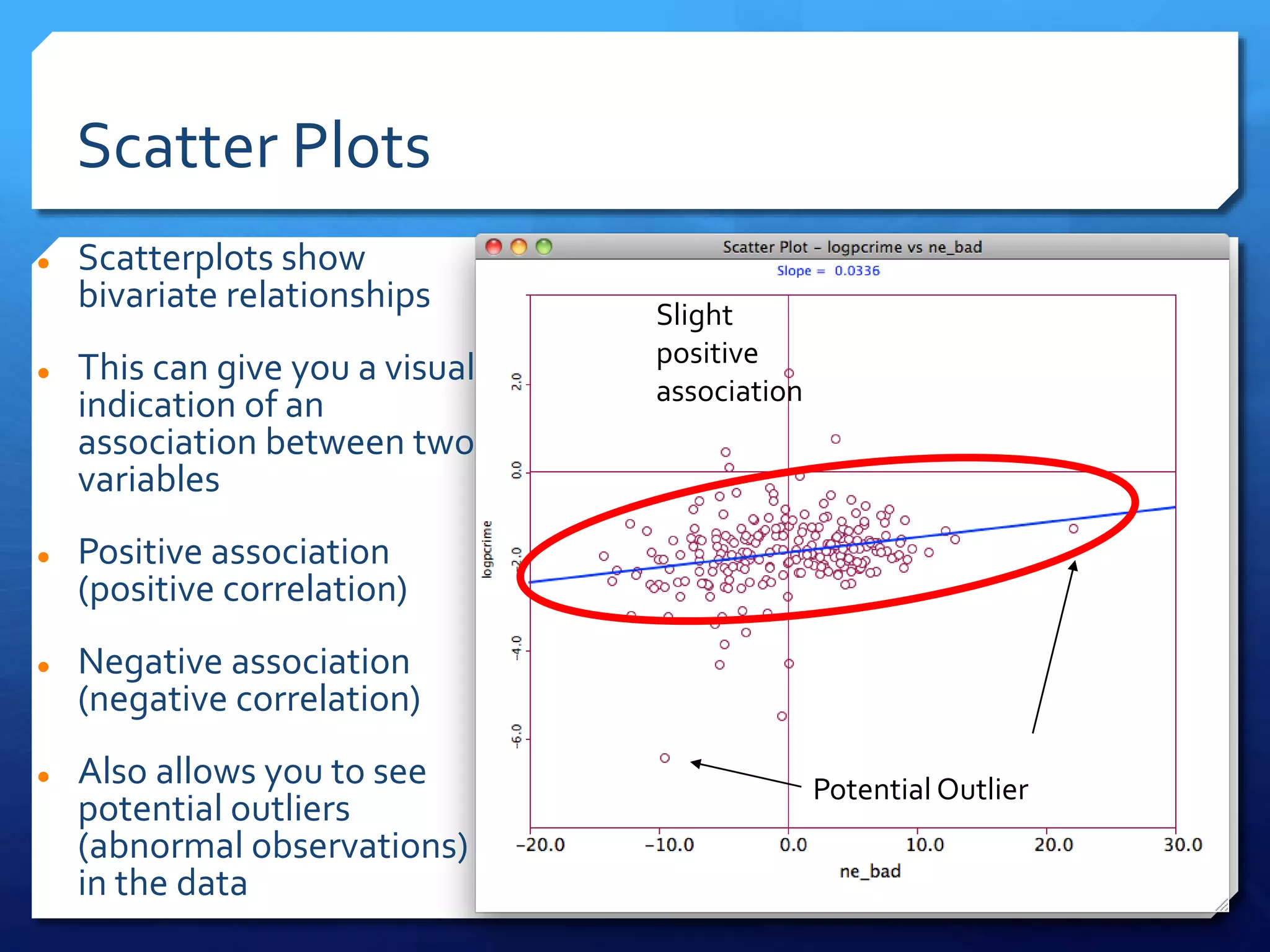

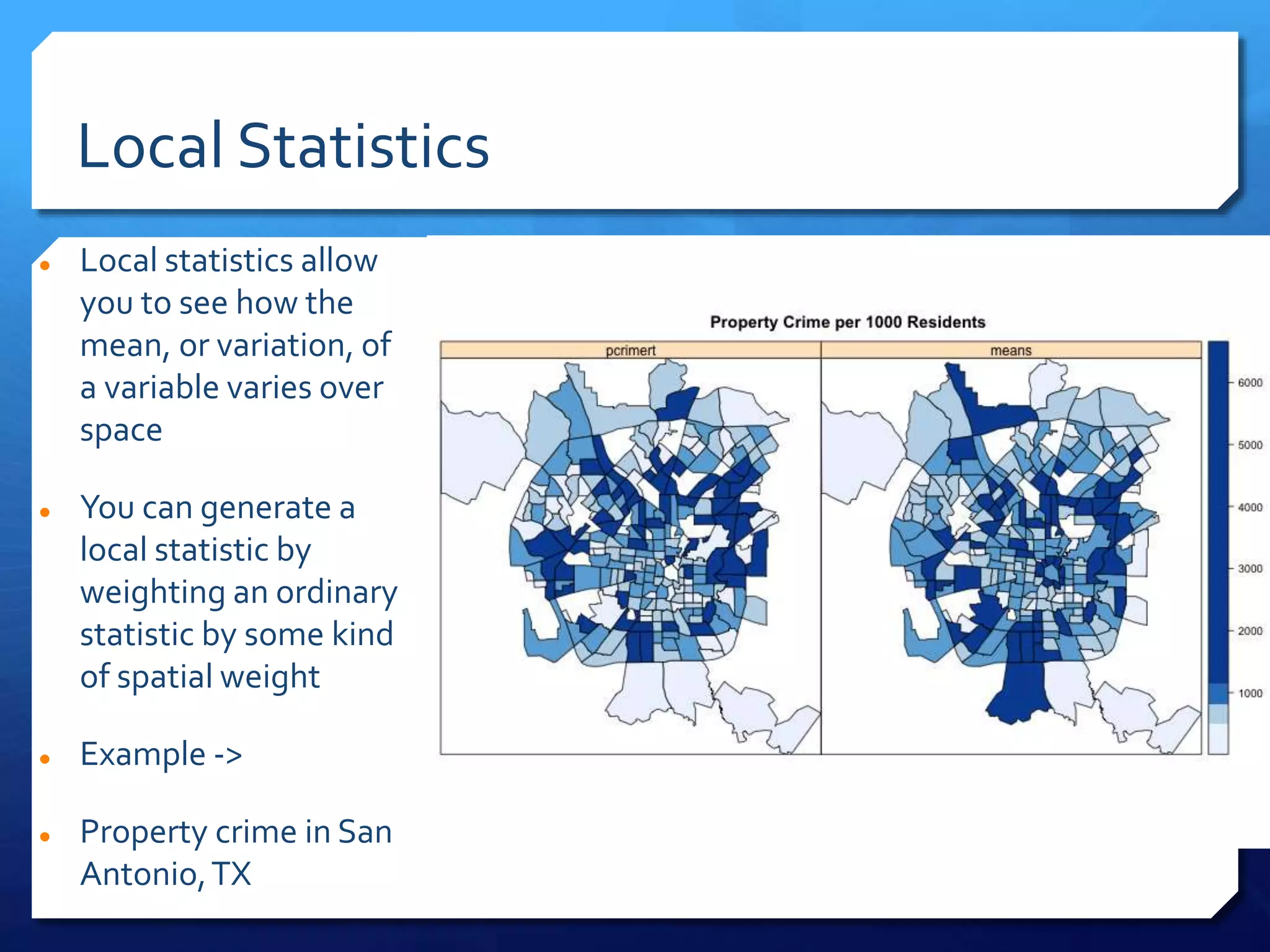



















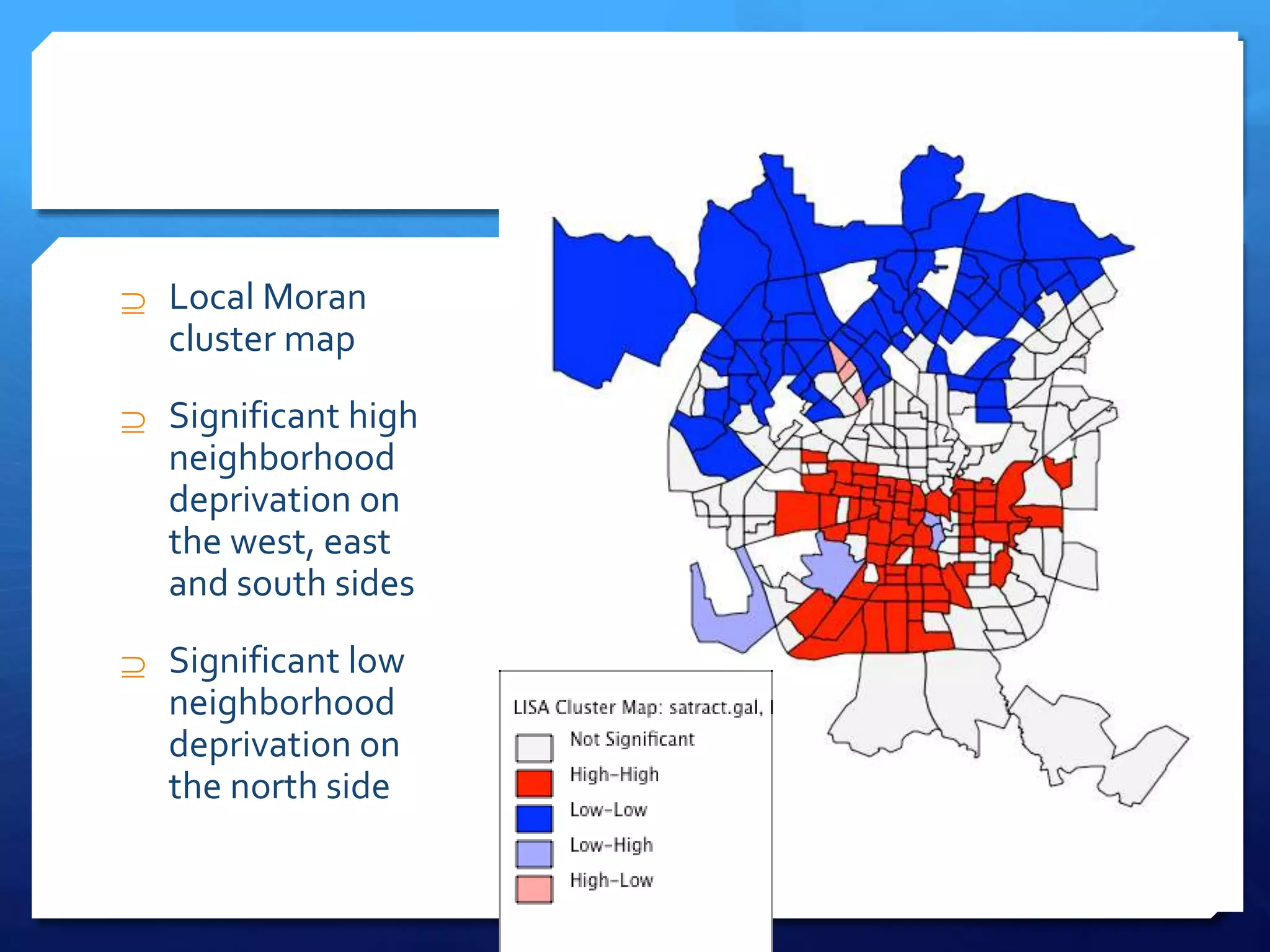



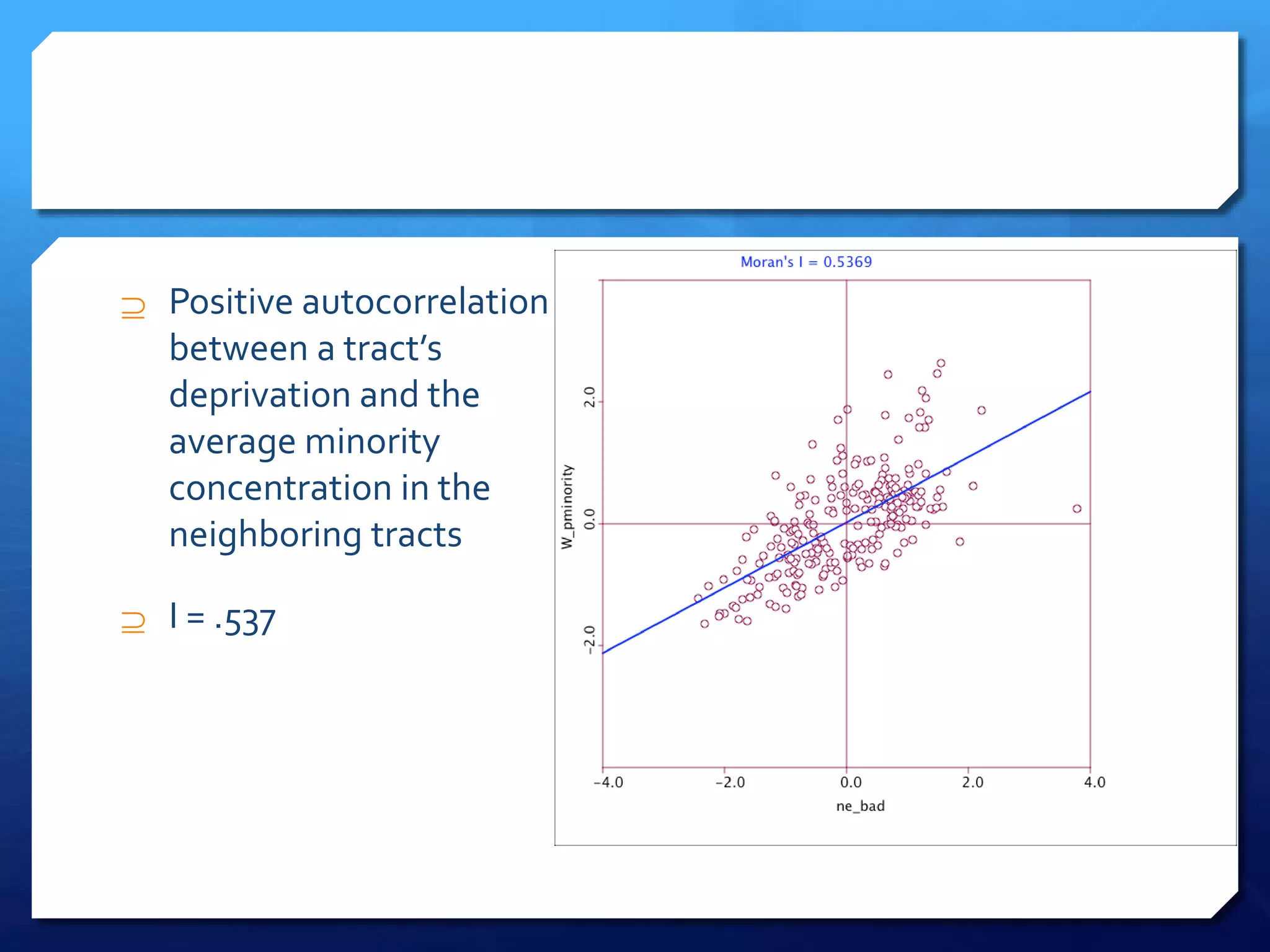





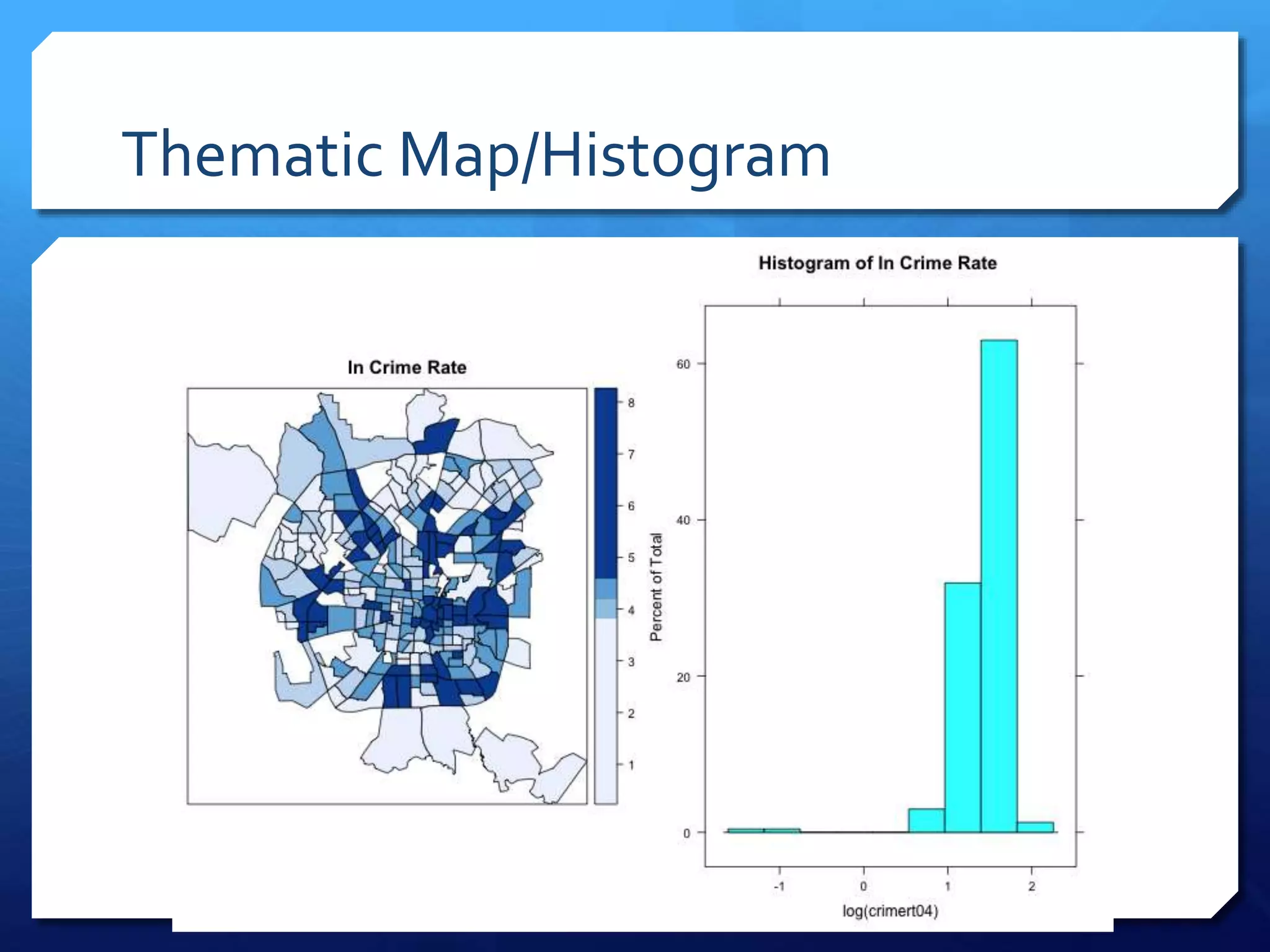
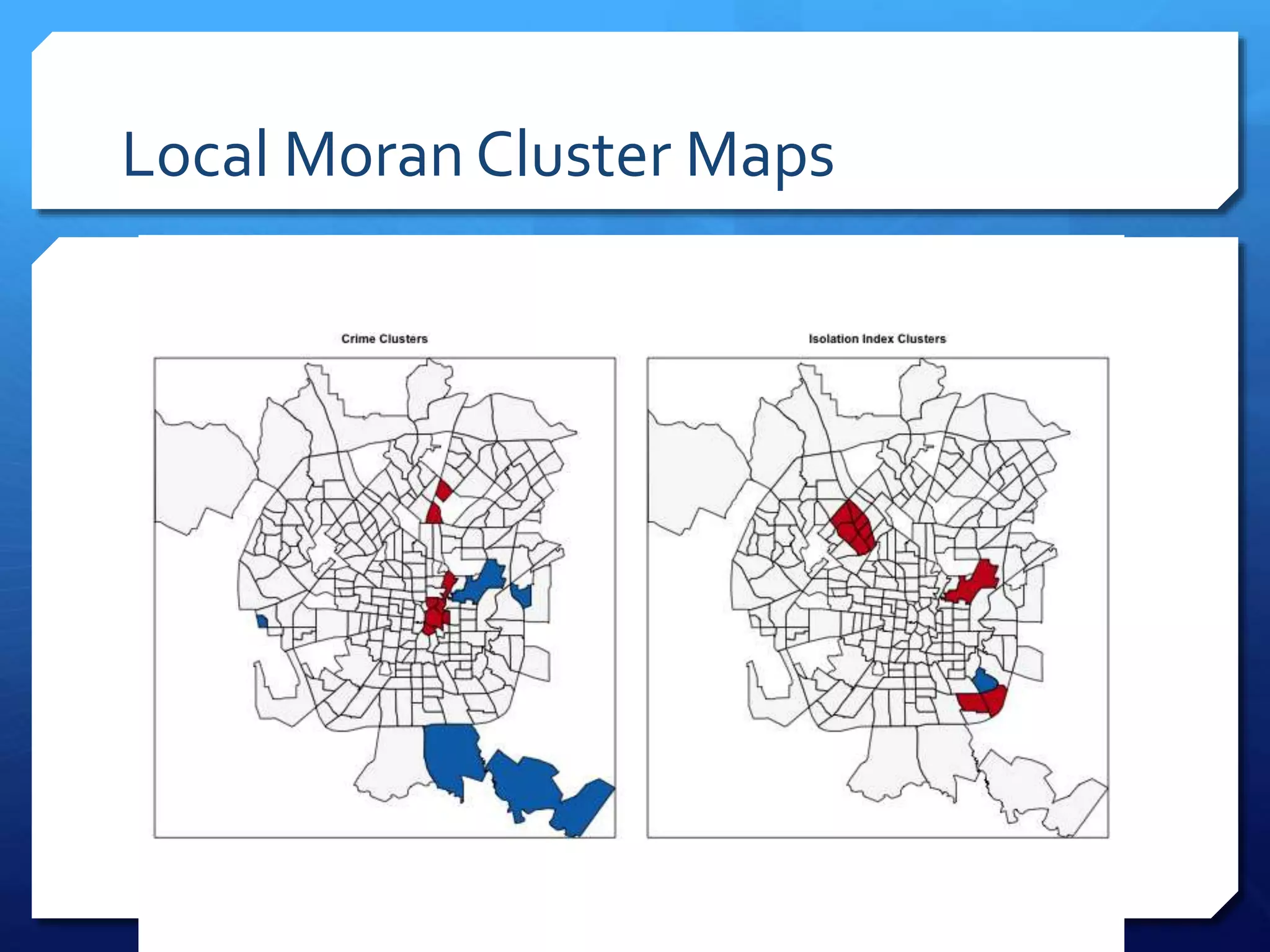


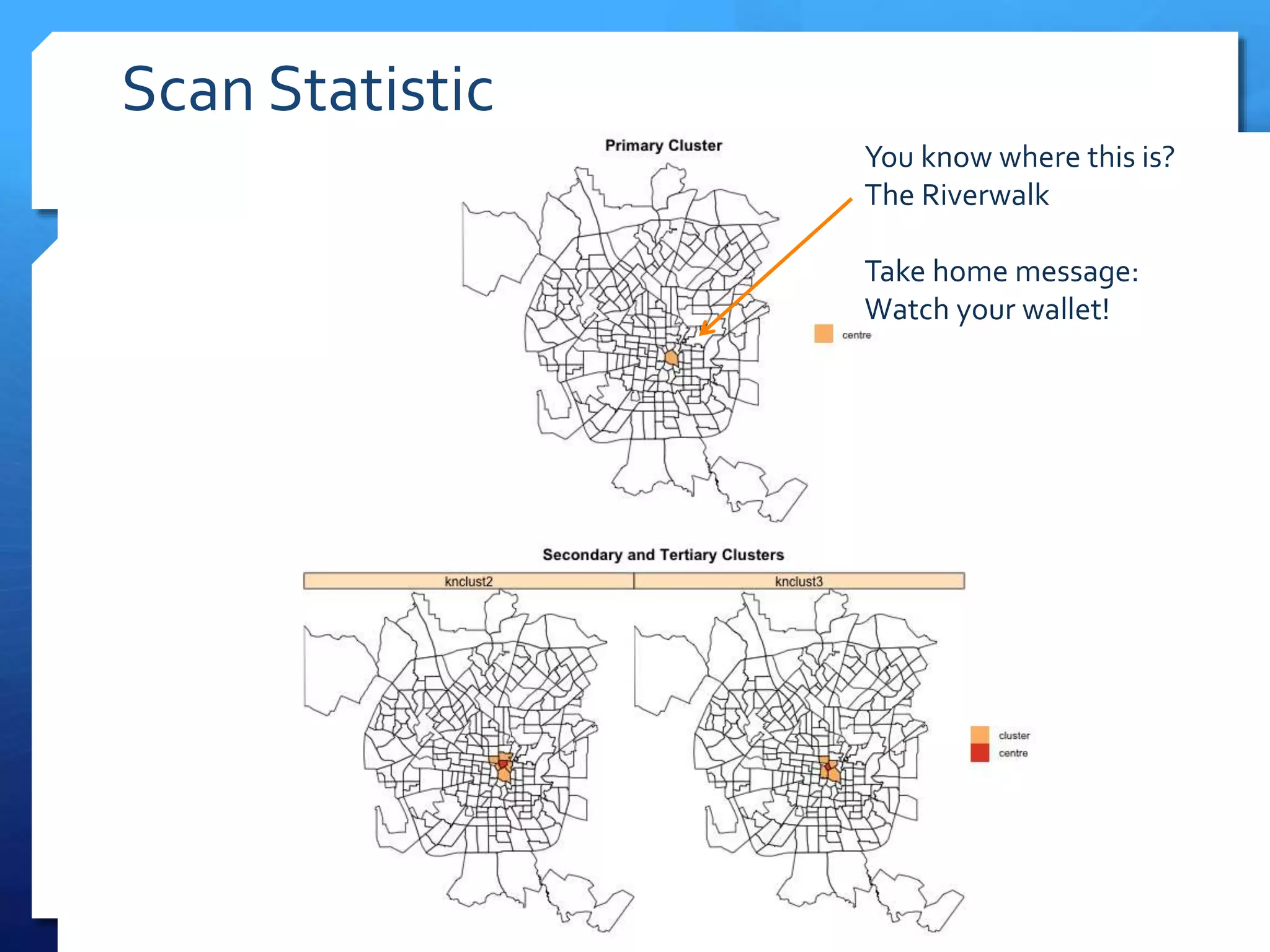












The document discusses spatial analysis in socio-economic and health research, emphasizing the importance of spatial data and its unique characteristics. It covers concepts such as spatial structure, the ecological fallacy, and modes of thinking about spatial analysis, including macro and micro perspectives. Additionally, it introduces exploratory spatial data analysis (ESDA) methods and highlights the significance of visualization in understanding spatial patterns and relationships.



















































































