This document summarizes Baidu's work on scalable deep learning using Spark. It discusses:
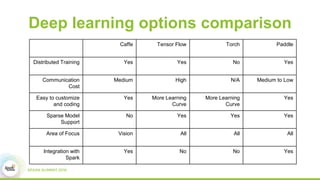
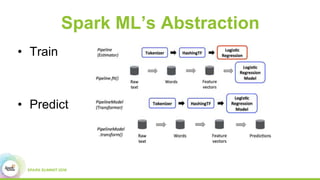
1) Baidu's goals of implementing Spark ML abstractions to train deep learning models at scale while leveraging Paddle's distributed training capabilities.
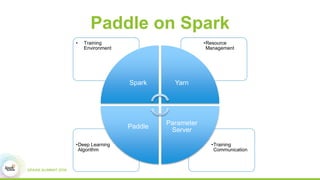
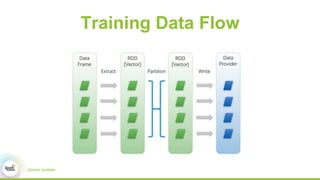
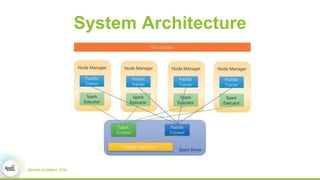
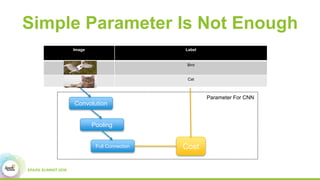
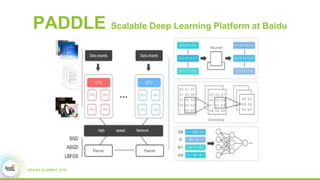
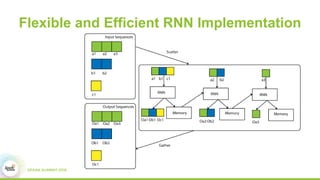
2) How Paddle is integrated with Spark to parallelize training, handle resources, and support both batch and streaming learning workflows.
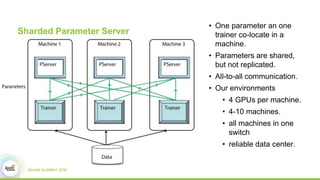
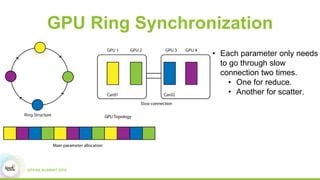
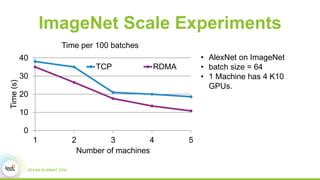
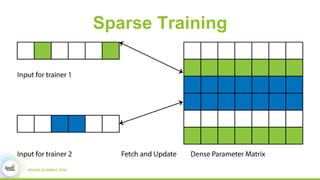
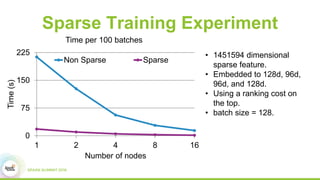
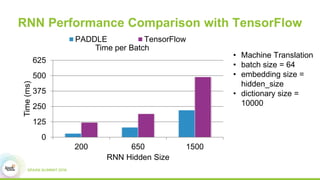
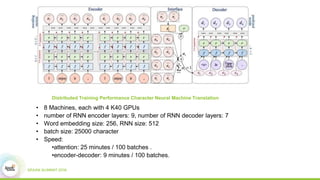
3) Experimental results showing Paddle achieves good scaling for image classification and machine translation using techniques like sharded parameter servers and GPU ring synchronization.