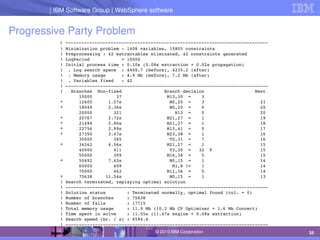
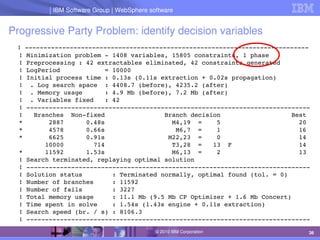
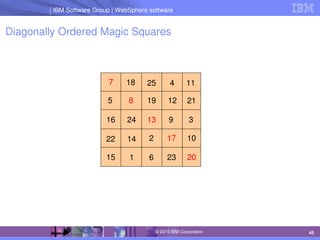
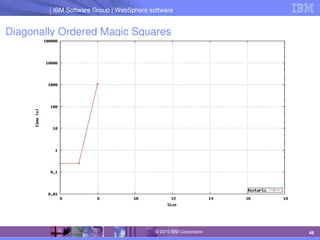
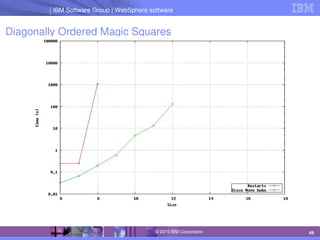
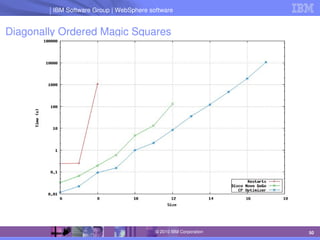
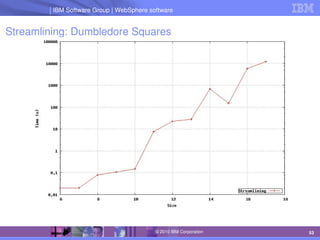
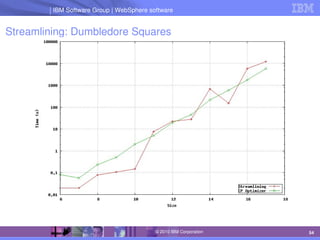
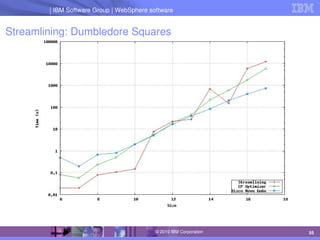
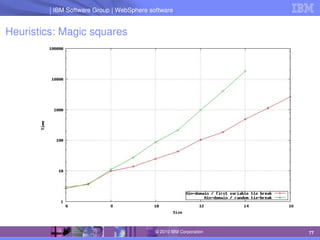
The document discusses IBM's optimization products, particularly focusing on the CPLEX Optimization Studio and CP Optimizer, which are designed for solving combinatorial and scheduling problems. It emphasizes healthy skepticism in research practices, advising against trusting one's initial results without thorough checks and validation against different models. The document also presents a case study on the max-cut problem and a progressive party problem, illustrating the importance of debugging and modeling techniques in optimization tasks.



































![IBM Software Group | Lotus software
IBM Software Group | WebSphere software
74
© 2010 IBM Corporation
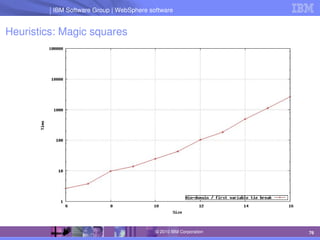
Heuristics
Variable and value ordering heuristics are ubiquitous
Typical implementation of first fail:
best = 1;
bestSize = infinity;
for i in 1..n
if (not fixed(x[i]) and domainsize(x[i]) < bestSize)
best = i
bestSize = domainsize(x[i])
end if
end for](https://image.slidesharecdn.com/cpaior2010-210518151713/85/Some-Do-s-and-Dont-s-of-Benchmarking-74-320.jpg)
![IBM Software Group | Lotus software
IBM Software Group | WebSphere software
75
© 2010 IBM Corporation
Heuristics
Variable and value ordering heuristics are ubiquitous
Typical implementation of first fail:
best = 1;
bestSize = infinity;
for i in 1..n
if (not fixed(x[i]) and domainsize(x[i]) < bestSize)
best = i
bestSize = domainsize(x[i])
end if
end for
– This code contains an implicit tiebreaking rule:
• Lower indexed variables are chosen over higher indexed ones](https://image.slidesharecdn.com/cpaior2010-210518151713/85/Some-Do-s-and-Dont-s-of-Benchmarking-75-320.jpg)







































![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)















