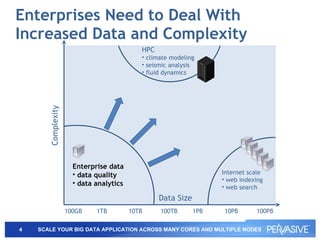
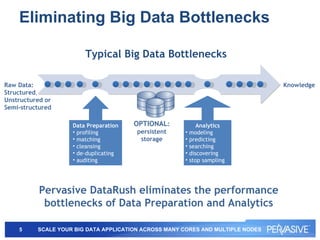
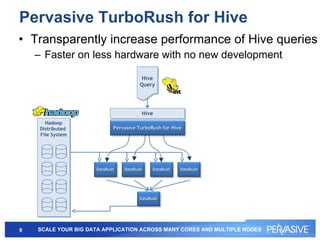
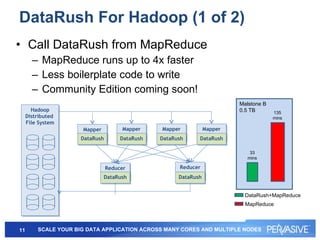
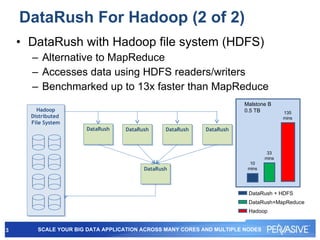
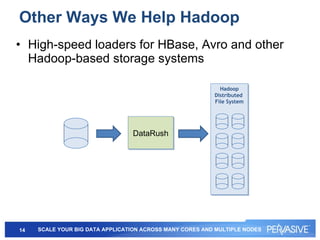
This document summarizes Pervasive DataRush, a software platform that can eliminate performance bottlenecks in data-intensive applications. It processes data in parallel to provide high throughput and scale performance on commodity hardware. DataRush integrates with Apache Hadoop and can increase Hadoop performance, processing data up to 13x faster than MapReduce. It is used across industries for tasks like genomic analysis, fraud detection, cybersecurity, and more.










![For More Information or to Download an Evaluation Copy http://www.pervasivedatarush.com [email_address] Follow us on Twitter: @ datarush Call +1 866 980 RUSH (7874) +1 512 231 6000](https://image.slidesharecdn.com/pervasive-110804064835-phpapp02/85/Pervasive-DataRush-17-320.jpg)




















































































