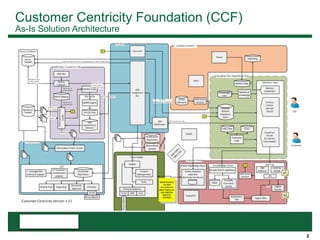
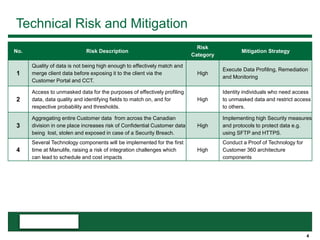
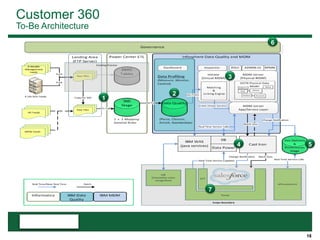
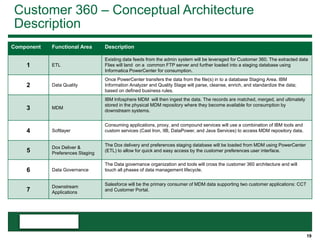
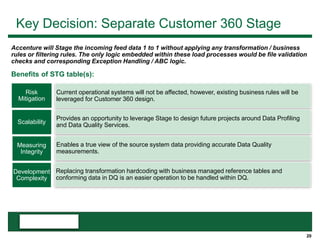
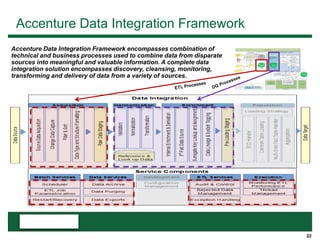
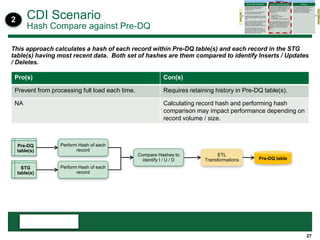
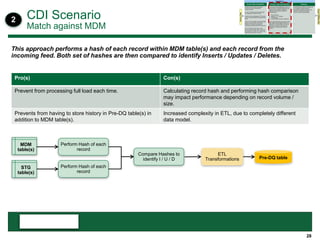
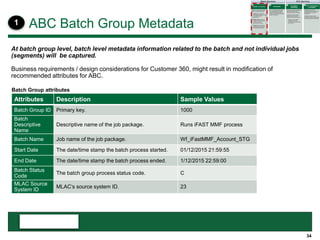
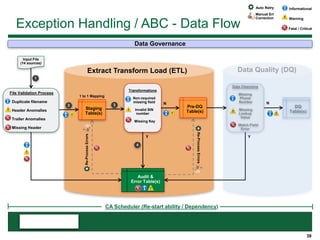
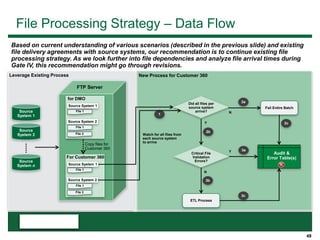
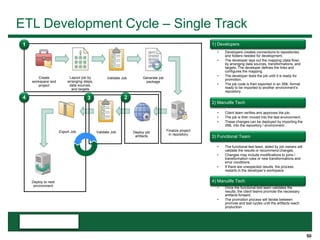
This document provides an overview of the conceptual data flow and architecture for a Customer 360 solution. Key components include extracting data from various admin systems, transforming and loading it into a data quality repository, matching and merging records in MDM, propagating updates to downstream systems like Salesforce, and enabling data steward review of matches and merges. The data flows both systematically and in response to user changes in various applications and portals.