Recommended
PDF
学術コンテンツサービスでの活用事例@Lucene/Solr勉強会(2015.5.13)
PDF
PDF
第16回Lucene/Solr勉強会 – ランキングチューニングと定量評価 #SolrJP
PDF
Lucene/Solr Revolution2015参加レポート
PDF
第17回Lucene/Solr勉強会 #SolrJP – Apache Lucene Solrによる形態素解析の課題とN-bestの提案
PPTX
Solr6 の紹介(第18回 Solr勉強会 資料) (2016年6月10日)
PPTX
NLP4L - 情報検索における性能改善のためのコーパスの活用とランキング学習
PPTX
Lucene/Solr Revolution 2016 参加レポート
PDF
PPT
KEY
Visual Representation & Learning
PPTX
PDF
PDF
Approaching Join Index: Presented by Mikhail Khludnev, Grid Dynamics
PDF
Faceting with Lucene Block Join Query: Presented by Oleg Savrasov, Grid Dynamics
PDF
PPTX
Images of jesus powerpoint
PPTX
PPTX
SolrのAtomicUpdateを50000倍速くした話
PDF
DocValues aka. Column Stride Fields in Lucene 4.0 - By Willnauer Simon
PPTX
PPTX
DOCX
Hukum pembiayaan makalah leasing
PDF
第10回solr勉強会 solr cloudの導入事例
PDF
PDF
Scaling search with SolrCloud
PPTX
Elasticsearch+nodejs+dynamodbで作る全社システム基盤
PDF
実践多クラス分類 Kaggle Ottoから学んだこと
PDF
20221209-ApacheSolrによるはじめてのセマンティックサーチ.pdf
PPTX
Solr から使う OpenNLP の日本語固有表現抽出
More Related Content
PDF
学術コンテンツサービスでの活用事例@Lucene/Solr勉強会(2015.5.13)
PDF
PDF
第16回Lucene/Solr勉強会 – ランキングチューニングと定量評価 #SolrJP
PDF
Lucene/Solr Revolution2015参加レポート
PDF
第17回Lucene/Solr勉強会 #SolrJP – Apache Lucene Solrによる形態素解析の課題とN-bestの提案
PPTX
Solr6 の紹介(第18回 Solr勉強会 資料) (2016年6月10日)
PPTX
NLP4L - 情報検索における性能改善のためのコーパスの活用とランキング学習
PPTX
Lucene/Solr Revolution 2016 参加レポート
Viewers also liked
PDF
PPT
KEY
Visual Representation & Learning
PPTX
PDF
PDF
Approaching Join Index: Presented by Mikhail Khludnev, Grid Dynamics
PDF
Faceting with Lucene Block Join Query: Presented by Oleg Savrasov, Grid Dynamics
PDF
PPTX
Images of jesus powerpoint
PPTX
PPTX
SolrのAtomicUpdateを50000倍速くした話
PDF
DocValues aka. Column Stride Fields in Lucene 4.0 - By Willnauer Simon
PPTX
PPTX
DOCX
Hukum pembiayaan makalah leasing
PDF
第10回solr勉強会 solr cloudの導入事例
PDF
PDF
Scaling search with SolrCloud
PPTX
Elasticsearch+nodejs+dynamodbで作る全社システム基盤
PDF
実践多クラス分類 Kaggle Ottoから学んだこと
More from Koji Sekiguchi
PDF
20221209-ApacheSolrによるはじめてのセマンティックサーチ.pdf
PPTX
Solr から使う OpenNLP の日本語固有表現抽出
PDF
Learning-to-Rank meetup Vol. 1
PPTX
Lucene 6819-good-bye-index-time-boost
PDF
An Introduction to NLP4L (Scala by the Bay / Big Data Scala 2015)
PDF
PDF
コーパス学習による Apache Solr の徹底活用
PDF
PDF
LUCENE-5252 NGramSynonymTokenizer
PDF
PPTX
系列パターンマイニングを用いた単語パターン学習とWikipediaからの組織名抽出
PPTX
Luceneインデックスの共起単語分析とSolrによる共起単語サジェスチョン
PPTX
PPTX
PPTX
Visualize terms network in Lucene index
PPTX
WikipediaからのSolr用類義語辞書の自動生成
PPTX
PPTX
PPTX
OpenNLP - MEM and Perceptron
PPTX
Nlp4 l intro-20150513 1. 2. NLP4Lとは?
Natural Language Processing for Lucene
ScalaベースのOSSプロジェクト
生テキストの代わりにLuceneインデックスのデータを使う
Luceneの強力なAnalyzerが使える
単語カウント、単語N-gramカウント、自由な基準による文書
ベクトルが容易に取得できる
独自MLツール+他MLツールとの連携機能
2
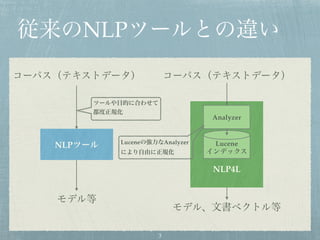
3. 4. 5. Luceneインデックスの基本
単語に分割して整理
カツオ:1, は:1, サザエ:1, の:1, 弟:1
サザエ:2, は:2, ワカメ:2, の:2, 姉:2
ワカメ:3, は:3, カツオ:3, の:3, 妹:3
5
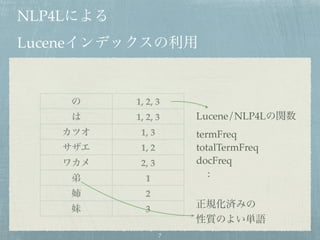
6. 7. 8. アーキテクチャー
Apache Lucene API
Scala Driver for Lucene
(Analyzer, Word-counter, FST dictionary etc.)
Scala High Level API (for convenience in text mining, stats etc.)
Index Schema
Browser
(GUI/CUI)
File based
Mahout/Spark
connector
Lucene Index
Model
RDD for Spark
Index
Interactive
Shell for NLP4L
(REPL)
*2015年5月現在、提供されていない機能も含みます。
8
9. 10. 開発メンバー
Tomoko Uchida
Pure Python FST & Morphological Analyzer developer
Koji Sekiguchi
Apache Lucene/Solr Committer & PMC member
Tommaso Teofili
Apache Lucene/Solr, UIMA, OpenNLP, Hama, etc.
Committer
10
11. 12. 楽しい その2
REPLからLuceneインデックスブラウザが動
くから楽しい!
nlp4l> :? // ヘルプの表示
nlp4l> open(“/tmp/index-ldcc”) // Luceneインデックスのオープン
nlp4l> status // Luceneインデックスの状態表示
nlp4l> browseTerms(“title”) // titleフィールドの単語一覧を取得する宣言
nlp4l> nt // 「次」の単語一覧の表示
nlp4l> nextTerms(500) // 500単語スキップして表示
nlp4l> topTerms(100) // titleフィールドのトップ100単語の表示
12
13. 楽しい その3
LuceneのいろいろなAnalyzerがREPLから使
えるので楽しい!
# StandardAnalyzer を取得
nlp4l> val analyzer1 = Analyzer(new org.apache.lucene.analysis.standard.StandardAnalyzer)
# StandardAnalyzer で英文を解析
nlp4l> analyzer1.tokens(“Lucene is a popular software.”)
# JapaneseAnalyzer を取得
nlp4l> val analyzer2 = Analyzer(new org.apache.lucene.analysis.ja.JapaneseAnalyzer)
# JapaneseAnalyzer で日本語文を解析
nlp4l> analyzer2.tokens(“旅にこだわりたい若者から人気”)
13
14. 楽しい その4
Luceneの処理結果をScalaで加工できるので
楽しい!
# 名詞のみterm要素を表示
nlp4l> analyzer2.tokens(“旅にこだわりたい若者から人気").
filter(_.getOrElse("partOfSpeech",null).startsWith("名詞")).map(_.getOrElse("term",null))
# 簡単ファセット(カテゴリごとの文書数をカウント)
nlp4l> val searcher = ISearcher(“/tmp/index-ldcc”)
nlp4l> searcher.search(rows=10000).map(_.getValue("cat").get(0)).
foldLeft(scala.collection.mutable.Map.empty[String, Int]){(m,c) => m += (c -> (m.getOrElse(c,
0)+1))}.foreach(println(_))
14
15. 16. 17. 18. 19. 20. 21.











![楽しい その4
Luceneの処理結果をScalaで加工できるので
楽しい!
# 名詞のみterm要素を表示
nlp4l> analyzer2.tokens(“旅にこだわりたい若者から人気").
filter(_.getOrElse("partOfSpeech",null).startsWith("名詞")).map(_.getOrElse("term",null))
# 簡単ファセット(カテゴリごとの文書数をカウント)
nlp4l> val searcher = ISearcher(“/tmp/index-ldcc”)
nlp4l> searcher.search(rows=10000).map(_.getValue("cat").get(0)).
foldLeft(scala.collection.mutable.Map.empty[String, Int]){(m,c) => m += (c -> (m.getOrElse(c,
0)+1))}.foreach(println(_))
14](https://image.slidesharecdn.com/nlp4l-intro-20150513-150513214121-lva1-app6892/85/Nlp4-l-intro-20150513-14-320.jpg)




![ShingleFilterを使ったサンプル
隠れマルコフモデル
hmm_postagger.scala
trans_katakana_alpha.scala
連語分析モデル
colloc_analysis_[brown|ldcc].scala
Brownコーパスを学習して
品詞タグを付加するサンプル
カタカナ語・英単語対応データを
学習してカタカナ語から英単語を
推定するサンプル
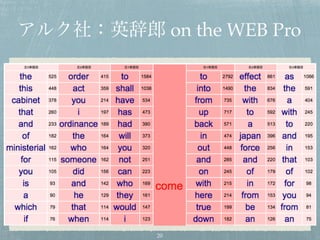
アルク社「英辞郎 on the WEB Pro」の
「頻度集計」ライクな出力をするサンプル
19](https://image.slidesharecdn.com/nlp4l-intro-20150513-150513214121-lva1-app6892/85/Nlp4-l-intro-20150513-19-320.jpg)