Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
NS
Uploaded by
Noritsugu Suzuki
25,883 views
はじめての検索エンジン&Solr 第13回Solr勉強会
第13回Solr勉強会資料 「はじめての検索エンジン&Solr」 検索エンジンの概要~Solrの活用まで (発表時の未公開スライドあり)
Business
◦
Read more
50
Save
Share
Embed
Embed presentation
Download
Downloaded 168 times
1
/ 41
2
/ 41
3
/ 41
4
/ 41
5
/ 41
6
/ 41
7
/ 41
8
/ 41
9
/ 41
10
/ 41
11
/ 41
12
/ 41
13
/ 41
14
/ 41
15
/ 41
16
/ 41
17
/ 41
18
/ 41
Most read
19
/ 41
Most read
20
/ 41
21
/ 41
Most read
22
/ 41
23
/ 41
24
/ 41
25
/ 41
26
/ 41
27
/ 41
28
/ 41
29
/ 41
30
/ 41
31
/ 41
32
/ 41
33
/ 41
34
/ 41
35
/ 41
36
/ 41
37
/ 41
38
/ 41
39
/ 41
40
/ 41
41
/ 41
More Related Content
PDF
SolrとElasticsearchを比べてみよう
by
Shinsuke Sugaya
PDF
第16回Lucene/Solr勉強会 – ランキングチューニングと定量評価 #SolrJP
by
Yahoo!デベロッパーネットワーク
PPTX
Apache Solr 入門
by
順平 西本
PPTX
Field collapsing/Result groupingについて
by
Jun Ohtani
PDF
Apache Solr 検索エンジン入門
by
Yahoo!デベロッパーネットワーク
PDF
40歳過ぎてもエンジニアでいるためにやっていること
by
onozaty
PDF
「いい検索」を考える
by
Shuryo Uchida
PPTX
solr勉強会資料
by
Atsushi Takayasu
SolrとElasticsearchを比べてみよう
by
Shinsuke Sugaya
第16回Lucene/Solr勉強会 – ランキングチューニングと定量評価 #SolrJP
by
Yahoo!デベロッパーネットワーク
Apache Solr 入門
by
順平 西本
Field collapsing/Result groupingについて
by
Jun Ohtani
Apache Solr 検索エンジン入門
by
Yahoo!デベロッパーネットワーク
40歳過ぎてもエンジニアでいるためにやっていること
by
onozaty
「いい検索」を考える
by
Shuryo Uchida
solr勉強会資料
by
Atsushi Takayasu
What's hot
PPTX
PySparkによるジョブを、より速く、よりスケーラブルに実行するための最善の方法 ※講演は翻訳資料にて行います。 - Getting the Best...
by
Holden Karau
PDF
第17回Lucene/Solr勉強会 #SolrJP – Apache Lucene Solrによる形態素解析の課題とN-bestの提案
by
Yahoo!デベロッパーネットワーク
PDF
PlaySQLAlchemy: SQLAlchemy入門
by
泰 増田
PDF
AWS Black Belt Online Seminar 2016 AWS CloudFormation
by
Amazon Web Services Japan
PDF
社内ドキュメント検索システム構築のノウハウ
by
Shinsuke Sugaya
PPTX
ネットストーカー御用達OSINTツールBlackBirdを触ってみた.pptx
by
Shota Shinogi
PDF
Where狙いのキー、order by狙いのキー
by
yoku0825
PDF
PostgreSQLアンチパターン
by
Soudai Sone
PDF
RESTful Web アプリの設計レビューの話
by
Takuto Wada
PDF
深層学習による自然言語処理入門: word2vecからBERT, GPT-3まで
by
Yahoo!デベロッパーネットワーク
PDF
RDF Semantic Graph「RDF 超入門」
by
オラクルエンジニア通信
PDF
At least onceってぶっちゃけ問題の先送りだったよね #kafkajp
by
Yahoo!デベロッパーネットワーク
PDF
Elasticsearch の検索精度のチューニング 〜テストを作って高速かつ安全に〜
by
Takahiko Ito
PDF
導入から 10 年、PHP の trait は滅びるべきなのか その適切な使いどころと弱点、将来について
by
shinjiigarashi
PPTX
はじめてのElasticsearchクラスタ
by
Satoyuki Tsukano
PDF
「GraphDB徹底入門」〜構造や仕組み理解から使いどころ・種々のGraphDBの比較まで幅広く〜
by
Takahiro Inoue
PDF
Vespa 機能紹介 #yjmu
by
Yahoo!デベロッパーネットワーク
PDF
Kinesis + Elasticsearchでつくるさいきょうのログ分析基盤
by
Amazon Web Services Japan
PPTX
DockerコンテナでGitを使う
by
Kazuhiro Suga
PDF
Javaのログ出力: 道具と考え方
by
Taku Miyakawa
PySparkによるジョブを、より速く、よりスケーラブルに実行するための最善の方法 ※講演は翻訳資料にて行います。 - Getting the Best...
by
Holden Karau
第17回Lucene/Solr勉強会 #SolrJP – Apache Lucene Solrによる形態素解析の課題とN-bestの提案
by
Yahoo!デベロッパーネットワーク
PlaySQLAlchemy: SQLAlchemy入門
by
泰 増田
AWS Black Belt Online Seminar 2016 AWS CloudFormation
by
Amazon Web Services Japan
社内ドキュメント検索システム構築のノウハウ
by
Shinsuke Sugaya
ネットストーカー御用達OSINTツールBlackBirdを触ってみた.pptx
by
Shota Shinogi
Where狙いのキー、order by狙いのキー
by
yoku0825
PostgreSQLアンチパターン
by
Soudai Sone
RESTful Web アプリの設計レビューの話
by
Takuto Wada
深層学習による自然言語処理入門: word2vecからBERT, GPT-3まで
by
Yahoo!デベロッパーネットワーク
RDF Semantic Graph「RDF 超入門」
by
オラクルエンジニア通信
At least onceってぶっちゃけ問題の先送りだったよね #kafkajp
by
Yahoo!デベロッパーネットワーク
Elasticsearch の検索精度のチューニング 〜テストを作って高速かつ安全に〜
by
Takahiko Ito
導入から 10 年、PHP の trait は滅びるべきなのか その適切な使いどころと弱点、将来について
by
shinjiigarashi
はじめてのElasticsearchクラスタ
by
Satoyuki Tsukano
「GraphDB徹底入門」〜構造や仕組み理解から使いどころ・種々のGraphDBの比較まで幅広く〜
by
Takahiro Inoue
Vespa 機能紹介 #yjmu
by
Yahoo!デベロッパーネットワーク
Kinesis + Elasticsearchでつくるさいきょうのログ分析基盤
by
Amazon Web Services Japan
DockerコンテナでGitを使う
by
Kazuhiro Suga
Javaのログ出力: 道具と考え方
by
Taku Miyakawa
Similar to はじめての検索エンジン&Solr 第13回Solr勉強会
ODP
pixiv サイバーエージェント共同勉強会 solr導入記
by
Takahiro Matsumiya
PPTX
技術勉強会(Solr入門編)
by
Atsushi Takayasu
PDF
全文検索入門
by
antibayesian 俺がS式だ
PDF
Solr勉強会第10回
by
Nobutoshi Ogata
PDF
オープンソースソフトウェア検索サーバ Solr入門
by
Open Source Software Association of Japan
PDF
オープンソースソフトウェア検索サーバ Solr入門
by
Jun Ohtani
PPTX
Solr の LTR プラグインの使い方 - 第3回 LTR 勉強会資料 -
by
Issei Nishigata
PDF
第15回Solr勉強会 - Solr at Yahoo! JAPAN #SolrJP
by
Yahoo!デベロッパーネットワーク
PPTX
Lucene/Solr Revolution 2016 参加レポート
by
Shinpei Nakata
PPT
アメーバサーチ 第二回solr勉強会
by
Gaku Tashiro
PPTX
SunspotではじめるSolr入門
by
Takao Baba
PPT
Solr@twitter検索
by
genta kaneyama
PDF
Lucene gosenの紹介 solr勉強会第7回
by
Jun Ohtani
PDF
2018/07/19 第21回Solr勉強会発表資料
by
AnnaOnishi
PDF
Lucene/Solr Revolution2015参加レポート
by
Yahoo!デベロッパーネットワーク
PPTX
CROSS 2015 全文検索群雄割拠
by
Katsushi Yamashita
PDF
検索エンジン開発
by
Yahoo!デベロッパーネットワーク
PDF
eZ Publish勉強会5月「eZ Find」
by
ericsagnes
PPTX
Solr6 の紹介(第18回 Solr勉強会 資料) (2016年6月10日)
by
Issei Nishigata
PDF
20121126 Solr@ニコニコ生放送
by
Yoshimura Soichiro
pixiv サイバーエージェント共同勉強会 solr導入記
by
Takahiro Matsumiya
技術勉強会(Solr入門編)
by
Atsushi Takayasu
全文検索入門
by
antibayesian 俺がS式だ
Solr勉強会第10回
by
Nobutoshi Ogata
オープンソースソフトウェア検索サーバ Solr入門
by
Open Source Software Association of Japan
オープンソースソフトウェア検索サーバ Solr入門
by
Jun Ohtani
Solr の LTR プラグインの使い方 - 第3回 LTR 勉強会資料 -
by
Issei Nishigata
第15回Solr勉強会 - Solr at Yahoo! JAPAN #SolrJP
by
Yahoo!デベロッパーネットワーク
Lucene/Solr Revolution 2016 参加レポート
by
Shinpei Nakata
アメーバサーチ 第二回solr勉強会
by
Gaku Tashiro
SunspotではじめるSolr入門
by
Takao Baba
Solr@twitter検索
by
genta kaneyama
Lucene gosenの紹介 solr勉強会第7回
by
Jun Ohtani
2018/07/19 第21回Solr勉強会発表資料
by
AnnaOnishi
Lucene/Solr Revolution2015参加レポート
by
Yahoo!デベロッパーネットワーク
CROSS 2015 全文検索群雄割拠
by
Katsushi Yamashita
検索エンジン開発
by
Yahoo!デベロッパーネットワーク
eZ Publish勉強会5月「eZ Find」
by
ericsagnes
Solr6 の紹介(第18回 Solr勉強会 資料) (2016年6月10日)
by
Issei Nishigata
20121126 Solr@ニコニコ生放送
by
Yoshimura Soichiro
Recently uploaded
PPTX
株式会社できるくんHP_CV最大化サイト監査レポート_主要ページ分析と改善提案
by
kotatajiri
PDF
#42_10.OWASPTop10_2025:An Overview and How Security Risks Have Evolved Since ...
by
OWASP Nagoya
PDF
【プロマネ仕事術】コミュニケーションスキル② - "報告" の5つのルール ~戦略を最大化する「戦略的報告」の技術~
by
Shunnosuke Ebina
PDF
合同会社エンジニアリングマネージメント会社説明資料_2026-02 Engineering Management LLC
by
Tsuyoshi Hisamatsu
PDF
【採用ピッチ資料】ランド・ジャパンの未来の仲間たちへ 2026年度改訂版.pdf
by
kurehanishio
PPTX
★【dodaキャンパス】27卒向け【交換できるくん】会社紹介説明資料_vol3★
by
ytajima3
株式会社できるくんHP_CV最大化サイト監査レポート_主要ページ分析と改善提案
by
kotatajiri
#42_10.OWASPTop10_2025:An Overview and How Security Risks Have Evolved Since ...
by
OWASP Nagoya
【プロマネ仕事術】コミュニケーションスキル② - "報告" の5つのルール ~戦略を最大化する「戦略的報告」の技術~
by
Shunnosuke Ebina
合同会社エンジニアリングマネージメント会社説明資料_2026-02 Engineering Management LLC
by
Tsuyoshi Hisamatsu
【採用ピッチ資料】ランド・ジャパンの未来の仲間たちへ 2026年度改訂版.pdf
by
kurehanishio
★【dodaキャンパス】27卒向け【交換できるくん】会社紹介説明資料_vol3★
by
ytajima3
はじめての検索エンジン&Solr 第13回Solr勉強会
1.
はじめての 検索エンジン&Solr 検索エンジンの概要~Solrの活用まで 第13回 Solr勉強会(2014/1/29) N.Suzuki
2.
自己紹介 氏名:鈴木 教嗣(スズキ
ノリツグ) 所属:株式会社NTTデータCCS 著書:改訂新版 Apache Solr入門(技術評論社) [著]大谷 純, 阿部 慎一朗, 大須賀 稔, 北野 太郎, 平賀 一昭, 鈴木 教嗣 [監修] 株式会社リクルートテクノロジーズ, 株式会社ロンウイット 好評発売中!! 今回はデジタル版あり!!
3.
検索エンジンの話
4.
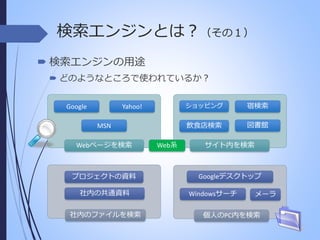
検索エンジンとは?(その1) 検索エンジンの用途 どのようなところで使われているか? Google ショッピング MSN Webページを検索 プロジェクトの資料 社内の共通資料 社内のファイルを検索 Web系 宿検索 飲食店検索 Yahoo! 図書館 サイト内を検索 Googleデスクトップ Windowsサーチ メーラ 個人のPC内を検索
5.
検索エンジンとは?(その2) 大量の文書データから特定の文書を探すツール どのように探すか? フリーワードで探す カテゴリーで探す 日付や数値の範囲で探す 並べ替えて探す(安い順など) 検索するための多くの機能を持つ
6.
検索方式の話 主な検索方式 順次検索 データの先頭から文字列が合致するか探す方式 索引検索
索引を作成して、その索引から探す方式 索引:インデックスとも。Solrの場合は転置インデックスとも言う。 Chapter-1
7.
検索方式の話(順次検索) 順次検索 1冊の本で例えるなら… 先頭ページから順に単語を探すイメージ
その単語があるか無いかわからないが、最終ページまで検索 使われているところ テキストエディタやブラウザのページ内検索 Linuxであればgrepコマンド、RDBのLike検索など 特徴 事前準備不要で検索可能 ページ内や小数のファイルなど小規模に向いている
8.
検索方式の話(索引検索) 索引検索 索引・Index 1冊の本で例えるなら… 本の末尾にある索引から単語から目的ページを探すイメージ
仮に…索引にそのワードがなければ、「ヒットなし」となる。 特徴 事前に索引を作成する必要がある 大規模にも対応し、検索速度が速い 多くの検索エンジンがこの方式を採用 Solrも索引を使用する検索方式
9.
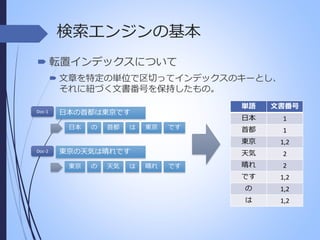
検索エンジンの基本 転置インデックスについて 文章を特定の単位で区切ってインデックスのキーとし、 それに紐づく文書番号を保持したもの。 の 首都 は です 東京の天気は晴れです 東京 の 天気 は 晴れ です 1 首都 1 1,2 天気 東京 文書番号 日本 日本の首都は東京です 日本 Doc-2 単語 東京 Doc-1 2 晴れ 2 です 1,2 の 1,2 は 1,2
10.
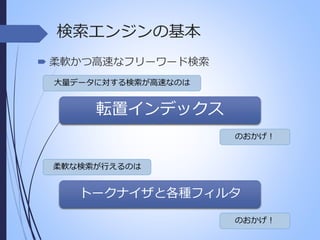
検索エンジンの基本 転置インデックスから探す 転置インデックスを使って「首都」を検索してみる。 単語 文書番号 日本 1 首都 1 東京 1,2 天気 2 晴れ 2 です 1,2 の 1,2 は 1,2 Doc-1 日本の首都は東京です Doc-2 東京の天気は晴れです この方式なら 検索も速そう…。
11.
検索エンジンの基本 柔軟かつ高速なフリーワード検索 大量データに対する検索が高速なのは 転置インデックス のおかげ!
12.
Apache Solrの話
13.
Apache Solrとは Solr
= ソーラーと読む 全文検索エンジンサーバアプリケーション JettyやTomcatなどで動作 2007.1 Apache projectのトップレベルプロジェクトに 現在はApache Lucene(ルシーン)のサブプロジェクト Lucene=検索エンジンライブラリ (Solrのコアライブラリであり、elasticsearchも使用) Solr(Lucene)のコミュニティ コミュニティが活発であり、不具合への対応も早い 新機能への取り組みも盛ん Chapter-1
14.
Solrの特徴 Full Javaで書かれているオープンソース
無償で利用可能であり、ソースも公開されている 容易に検索サーバが構築可能 数コマンドで検索サーバを利用できる 小規模から大規模まで対応 更に複数のスケールする機能・手法が利用できる 豊富な検索機能のサポート 高速化を可能にするキャッシュ機構 日本語にも対応したトークナイザやフィルタ Chapter-1
15.
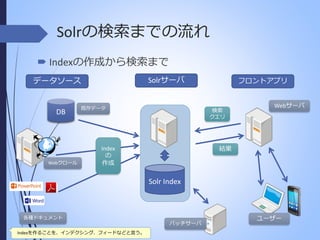
Solrの検索までの流れ Indexの作成から検索まで データソース DB Webクロール フロントアプリ Solrサーバ 既存データ 検索 クエリ Webサーバ 結果 Index の 作成 Solr Index 各種ドキュメント Indexを作ることを、インデクシング、フィードなどと言う。 バッチサーバ ユーザー
16.
Solrの機能紹介 検索 検索クエリ
スコアによるソート スコアリングについて 多言語に対応した柔軟な検索 ファセット検索(Facet)/ 緯度経度検索(Spatial) ハイライト機能 / グルーピング機能 スケールアウト インデックスの複製:replication 分散横断検索:distributed 分散検索:Solr Cloud Chapter-4,7,8
17.
Solrの検索クエリ Solrの検索方法 Solr用の検索式(クエリ)を使用します。 検索条件を
フィールド名 q= sort= rows= ソート条件 : 検索ワード フィールド名 (スペース) の形式で指定 asc / desc 1ページに表示させる件数を整数で指定 例えば…賃貸物件を探す。 説明文(note)に「築浅」を含み、かつ、家賃(price)が8万以下の 物件を延べ床面積(space)が広い順に20件表示 q=note:築浅 AND price:[*TO 80000] &sort=space desc &rows=20 Chapter-4
18.
Solrの機能紹介(スコア) スコアによるソート スコア=検索条件の一致度の指数
検索条件によりマッチしたドキュメントが高スコア Solrのスコアを算出する計算式 デフォルトではLuceneのスコア計算式 tf-idf のベクトルモデル scoreq,d coord q,d queryNormq tf t in d idf t t.getBoost Normt,d 2 t in q 単語ヒット数 出現数 希少度
19.
Solrの機能紹介(スコア) 単語ヒット数(coord) 検索したワードが幾つヒットしたか
例:OR検索した時などに影響 「ジャガイモ OR ベーコン OR タマネギ」で検索 ジャガイモ 「材料:ジャガイモ、ニンジン、豚肉」・・・1個 タマネギ 「材料:ナス、鶏ひき肉、ピーマン、タマネギ」・・・1個 ベーコン タマネギ 「材料:ベーコン、キャベツ、タマネギ」・・・2個 高スコア
20.
Solrの機能紹介(スコア) 出現数(tf) 1フィールドにそのワードが何個あるか
例:「Solr」で検索 Solr 「Solrを使ってみよう」・・・1回 Solr Solr Solr 「SolrのSolrによるSolrのための検索」 ・・・3回 Solr Solr 「Solrって何?~検索エンジンSolr~」 ・・・2回 高スコア
21.
Solrの機能紹介(スコア) 希少度(idf) そのワードがどのくらい稀少か(Solrでは価値がある)
例:「ジャガイモ OR タマネギ」で検索 ジャガイモ 「材料:ジャガイモ、ニンジン、豚肉」 高スコア タマネギ 「材料:ナス、鶏ひき肉、ピーマン、タマネギ」 タマネギ 「材料:ベーコン、キャベツ、タマネギ」 各ワードのドキュメント数を比較 ジャガイモ・・・1ドキュメント タマネギ・・・2ドキュメント ジャガイモの方が希少
22.
Solrの機能紹介(スコア) Solrのスコア 単語のヒット数、出現頻度、希少度の他、 フィールドの長さ(割合)、ブーストなどの要素を加味し てスコアリングを行っている
通常の検索で、ソート条件を指定していないときや、 「sort=score desc」を指定するとスコアでソート可能 fl=*,score とすることで、スコアの表示も可能 OSSなのでスコアの部分も自己流に改造も可能
23.
検索エンジンの基本 柔軟かつ高速なフリーワード検索 大量データに対する検索が高速なのは 転置インデックス のおかげ! 柔軟な検索が行えるのは トークナイザと各種フィルタ のおかげ!
24.
多言語対応と柔軟な検索 トークナイザと言語フィルタの充実 数十か国もの言語をサポート
example内にも多数の定義あり 特に… 日本語用のフィルタも多数あり、Solr3.6より標準で 「形態素解析」が利用できるようになった Kuromojiの辞書も内包 形態素解析:日本語の文章を単語(各品詞)に切り分ける処理。多くは辞書を用いて行う。 Chapter-2
25.
トークナイザとフィルタ トークナイザ 日本語用:JapaneseTokenizerFactory
ホワイトスペース用:WhitespaceTokenizerFactory N-Gram:NGramTokenizerFactory フィルタ 文字フィルタ:MappingCharFilterFactory 品詞フィルタ:JapanesePartOfSpeechStopFilterFactory 禁止ワード:StopFilterFactory 大文字小文字:LowerCaseFilterFactory Chapter-2
26.
フィルタ紹介 文字フィルタ:MappingCharFilterFactory トークナイズする前に文字を置き替えるフィルタ 「タ
゙」(半角は濁点も1文字) 「タ ゙」を「ダ」と置き替えることが可能 例:「斎」「齊」「齋」を「斉」の に、「髙」を「高」に置き換える。 「斎藤さん」を「斉藤さん」でも探せる 「髙橋さん」を「高橋さん」でも探せる 例: 意外と便利です
27.
検索機能紹介 ファセット(facet) ドリルダウン検索を実現するための機能 検索フォーム 検索 商品A+説明 衣料(84) DIY(20) ギフト(12) 家電(8) ゲーム(4) その他(2) 商品B+説明 商品C+説明 商品D+説明 コレ 文書をカテゴリで絞り込むのに有効 カテゴリはジャンル、地域、金額など様々 Chapter-4
28.
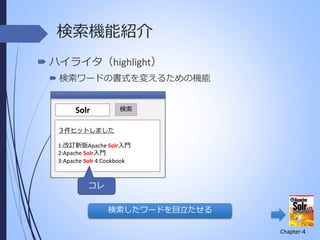
検索機能紹介 ハイライタ(highlight) 検索ワードの書式を変えるための機能 検索 Solr 3件ヒットしました 1:改訂新版Apache
Solr入門 2:Apache Solr入門 3:Apache Solr 4 Cookbook コレ 検索したワードを目立たせる Chapter-4
29.
Solrの運用・スケールについて
30.
Solrのスケール 検索システムを構築する際に規模の見積りは重要 運用中のSolrが直面する課題…
利用するユーザー数が増えた(QPSの増加) 検索対象となるドキュメントが増えた 検索クエリが複雑になった クエリのレスポンスが遅くなるなど 検索性能の低下 QPS:Query par Secondの略。1秒間に何クエリ処理できるかという性能指数のひとつ
31.
検索性能低下の対策 クエリ改善 クエリチューニングが可能か調査する
スケールアップ 単純にSolrサーバを高性能化 CPUパワーアップ、メモリ増設、HDD高速化など アプリの改修を行うことなく性能向上 スケールアウト Solrはスケールアウトするための複数の機能を持つ replication:インデックスの複製機能 distributed/Solr Cloud:分散検索機能 Chapter-8,9
32.
Solrの活用・導入について
33.
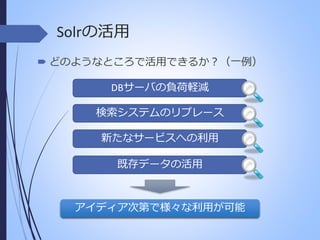
Solrの活用 どのようなところで活用できるか?(一例) DBサーバの負荷軽減 検索システムのリプレース 新たなサービスへの利用 既存データの活用 アイディア次第で様々な利用が可能
34.
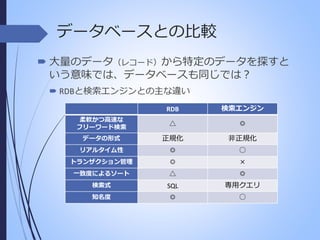
データベースとの比較 大量のデータ(レコード)から特定のデータを探すと いう意味では、データベースも同じでは? RDBと検索エンジンとの主な違い RDB 検索エンジン 柔軟かつ高速な フリーワード検索 △ ◎ データの形式 正規化 非正規化 リアルタイム性 ◎ ○ トランザクション管理 ◎ × 一致度によるソート △ ◎ 検索式 SQL 専用クエリ 知名度 ◎ ○
35.
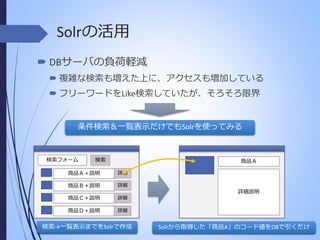
Solrの活用 DBサーバの負荷軽減 複雑な検索も増えた上に、アクセスも増加している
フリーワードをLike検索していたが、そろそろ限界 条件検索&一覧表示だけでもSolrを使ってみる 検索フォーム 検索 商品A 商品A+説明 詳細 商品B+説明 詳細 商品C+説明 詳細 商品D+説明 詳細 詳細説明 検索→一覧表示までをSolrで作成 Solrから取得した「商品A」のコード値をDBで引くだけ
36.
Solrの活用 DBサーバの補助機能として使う場合の注意 Solrはトランザクション管理ができない
在庫管理・・・× 複数のユーザが更新する・・・× リアルタイム性が低い 索引を作成→検索可能 となるため、タイムラグが発生する 要件次第でラグを最小にすることは可能だが、RDBのような使 い方は不得意 データベースとのデータの整合性や お互いの機能の利点を活かす使い方が重要 検索エンジン特有の知識が必要
37.
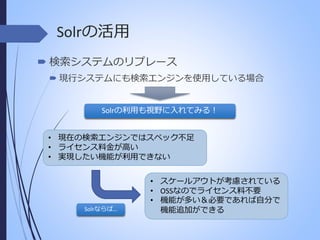
Solrの活用 検索システムのリプレース 現行システムにも検索エンジンを使用している場合 Solrの利用も視野に入れてみる! •
現在の検索エンジンではスペック不足 • ライセンス料金が高い • 実現したい機能が利用できない Solrならば… • スケールアウトが考慮されている • OSSなのでライセンス料不要 • 機能が多い&必要であれば自分で 機能追加ができる
38.
Solrの活用 新たなサービスへの利用 現行のサイトにフリーワードの検索機能が無い
検索機能を付与してみる。 顧客満足度が向上 現行システムの検索を強化する DBを使った社内システムだが、キーワードにマッチせず、検索 結果がゼロ件になることが多々あった。 検索エンジンの導入により、柔軟なフリーワードを実現 電話対応用のシステムだが、過去事例の検索に10秒くらい時間 がかかっていた。 検索エンジン導入により、レスポンスが1秒以下に! 業務効率の向上&顧客満足度も向上
39.
Solrの活用 既存データの活用 分析ツールとして活用してみる
強力な形態素解析機を活用して、データを集計 捨てていたログを検索機能を使って分析してみる 「検索エンジン」を使うことで 新たな気付きがあるかも知れない
40.
ひとこと Apache Project
なのでOSSの中でも信頼性が高く、国 内外で実績も多くあります。 顧客がOSSを心配することもあるかもしれませんが… コミュニティが活発なのは強み! Solrは検索エンジンが初めての人でも導入しやすい 改訂新版 Apache Solr入門 もあります! 身近にサポートしてくれる人も??(勉強会も開催) これを機に、またSolrを盛り上げましょう!!
41.
ご清聴ありがとうございました こちらもよろしく お願いいたします!
Download


![自己紹介
氏名:鈴木 教嗣(スズキ ノリツグ)
所属:株式会社NTTデータCCS
著書:改訂新版 Apache Solr入門(技術評論社)
[著]大谷 純, 阿部 慎一朗, 大須賀 稔, 北野 太郎, 平賀 一昭, 鈴木 教嗣
[監修] 株式会社リクルートテクノロジーズ, 株式会社ロンウイット
好評発売中!!
今回はデジタル版あり!!](https://image.slidesharecdn.com/solr12-140202233025-phpapp02/85/Solr-13-Solr-2-320.jpg)











![Solrの検索クエリ
Solrの検索方法
Solr用の検索式(クエリ)を使用します。
検索条件を フィールド名
q=
sort=
rows=
ソート条件
:
検索ワード
フィールド名
(スペース)
の形式で指定
asc / desc
1ページに表示させる件数を整数で指定
例えば…賃貸物件を探す。
説明文(note)に「築浅」を含み、かつ、家賃(price)が8万以下の
物件を延べ床面積(space)が広い順に20件表示
q=note:築浅 AND price:[*TO 80000]
&sort=space desc
&rows=20
Chapter-4](https://image.slidesharecdn.com/solr12-140202233025-phpapp02/85/Solr-13-Solr-17-320.jpg)