Downloaded 13 times


















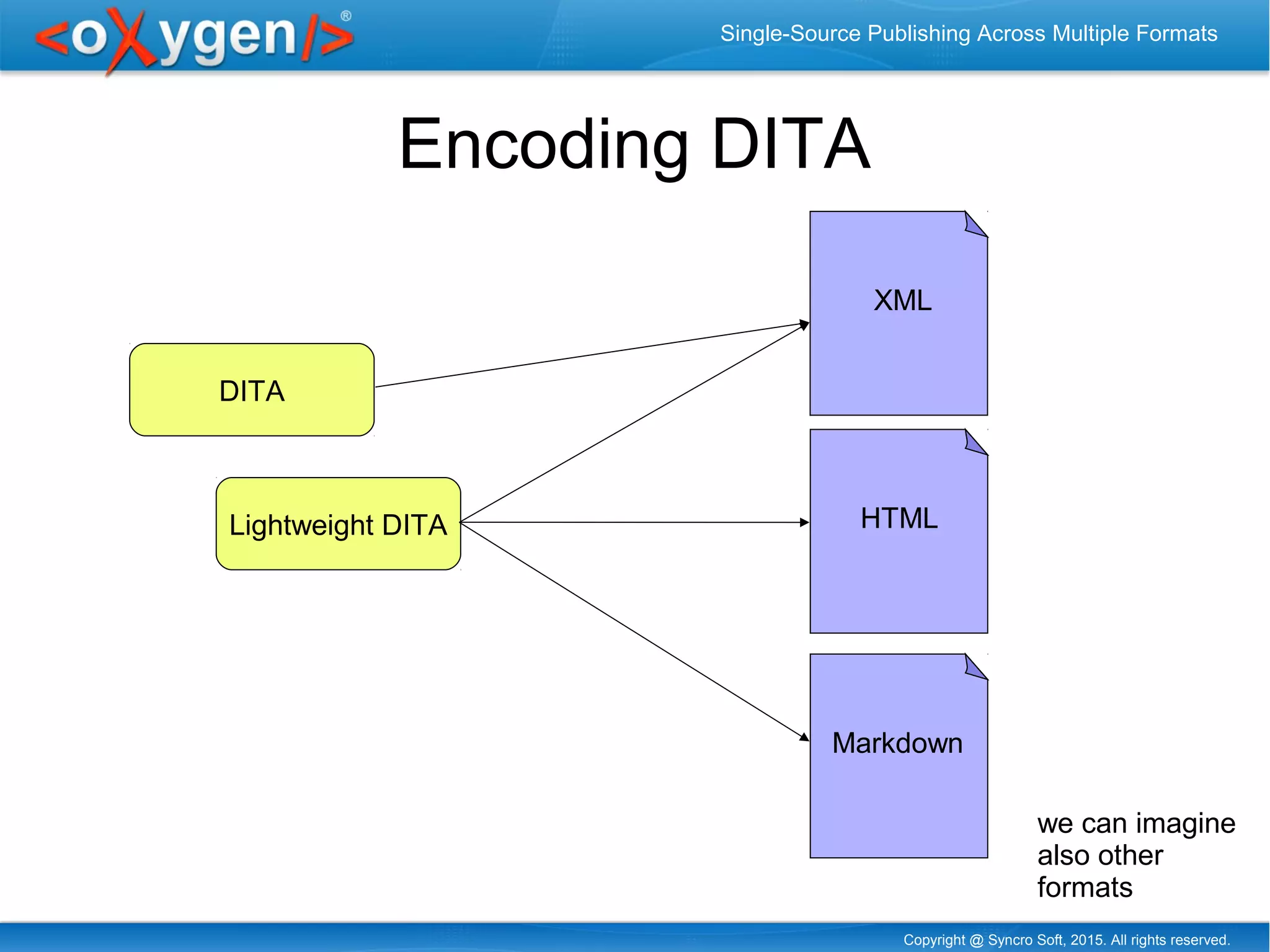









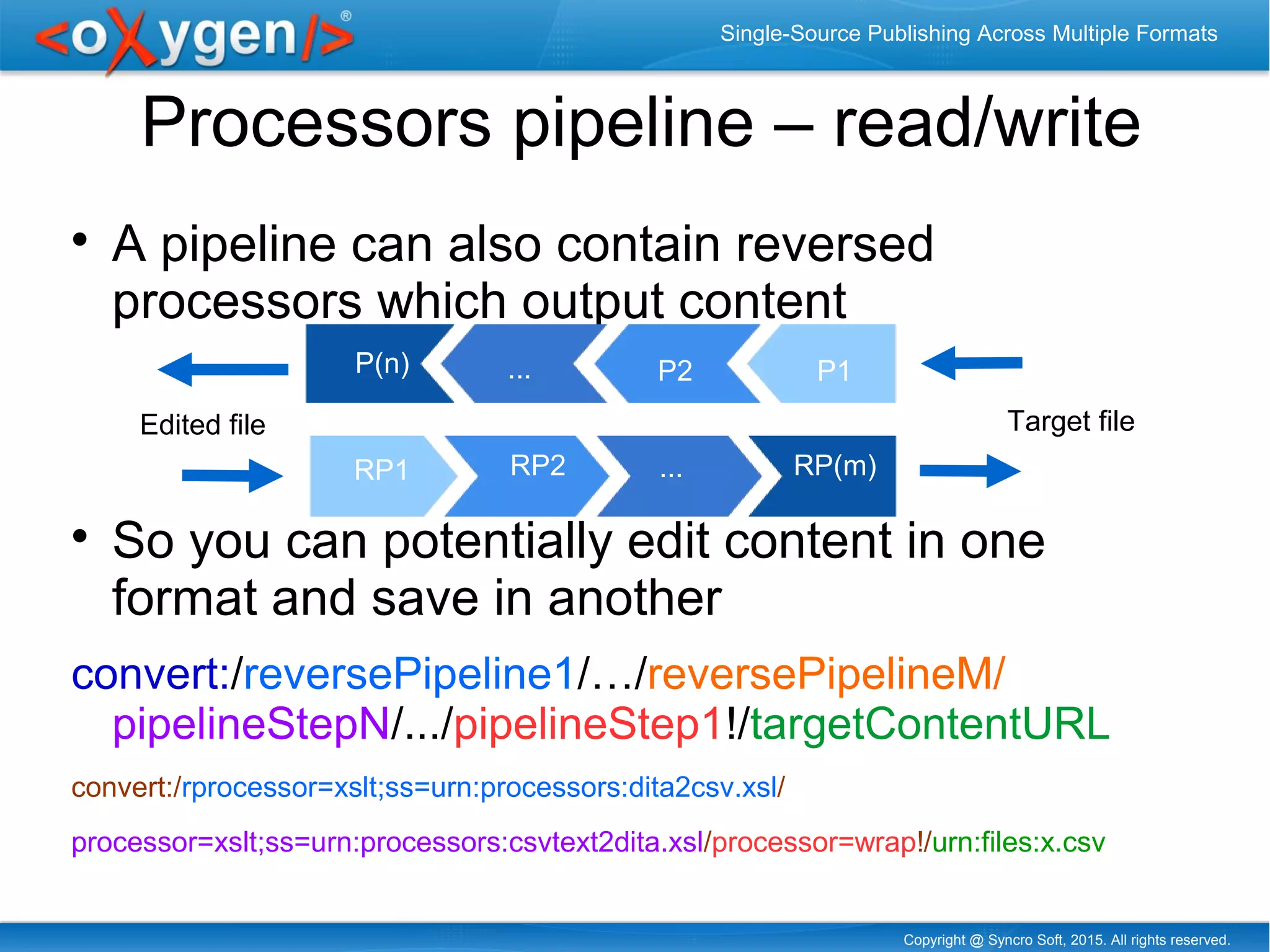

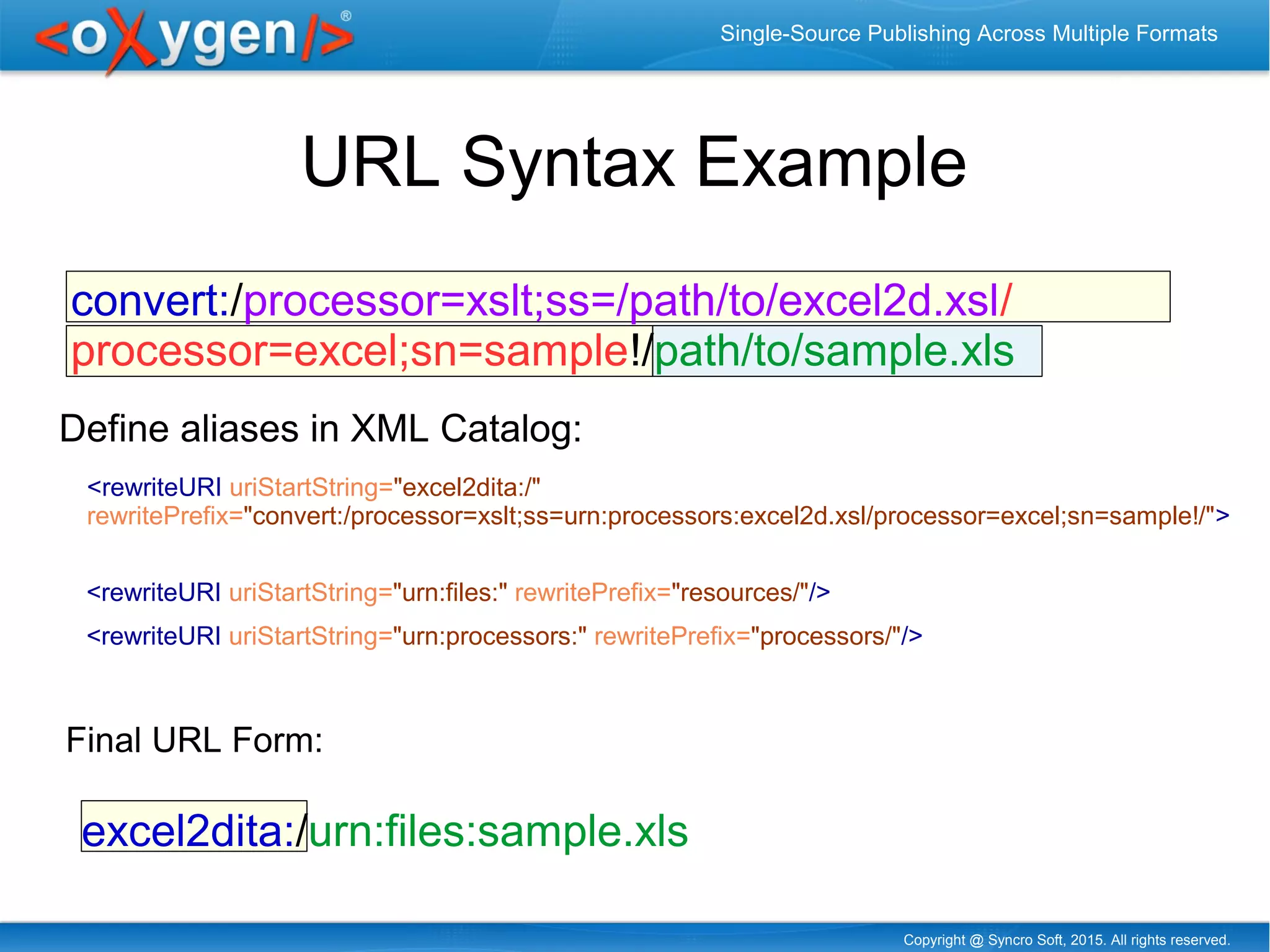





















The document discusses single-source publishing across multiple formats, emphasizing the importance of structured content for efficient processing and conversion. It details various encoding methods, usability of existing structured formats, and exemplifies cross-format publishing between formats like DITA, XML, HTML, and Excel. The conclusions highlight the potential of integrating different formats into a single DITA publication through URLs, presenting a powerful and flexible approach to document publishing.


















































![[Workshop Part 1-3] Modernizing Your Technical Resource Center - Assessing th...](https://cdn.slidesharecdn.com/ss_thumbnails/2018-1127-1415-03reginaslidesfinalcopy-190104165630-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Workshop Part 1-4] Modernizing Your Technical Resource Center - Assessing th...](https://cdn.slidesharecdn.com/ss_thumbnails/2018-1127-1415-04idw-2018-day-1-systems-190104165209-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Panel] Convincing Your Company to Improve Your Technical Resource Center](https://cdn.slidesharecdn.com/ss_thumbnails/2018-1127-1630paulpaneldiscussionfinal-190104164121-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Case Study] Adopting an Agile Content Development Process with Debra Brinson...](https://cdn.slidesharecdn.com/ss_thumbnails/2018-1128-0930debrabrinsonfinal-190104162339-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Case Study] Content User Experience - Quality versus Quantity with Eeshita G...](https://cdn.slidesharecdn.com/ss_thumbnails/2018-1128-1030eeshitagroverfinal-190104162137-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Workshop Part 2-4] Driving Toward the Future State with Joe Gelb of Zoomin S...](https://cdn.slidesharecdn.com/ss_thumbnails/2018-1128-1415-04joegelbworkshopfinal-190103222900-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Case Study] Harnessing Engaging Content for a Richer Customer Experience wit...](https://cdn.slidesharecdn.com/ss_thumbnails/2018-1129-1130sannayoderfinal-190103220352-thumbnail.jpg?width=640&height=640&fit=bounds)























