HadoopCompression
•Download as DOCX, PDF•
0 likes•156 views
This document compares different compression options for Hadoop clusters including bzip2, gzip, zlib, LZO, LZ4, and Snappy. It discusses the tradeoffs between compression speed, output file size, ability to split files for parallel decompression, and CPU overhead. The optimal compression choice depends on the phase of the MapReduce job and factors like data transfer overhead and hardware capabilities. Compression can reduce storage usage and network load during shuffling and sorting, while slower algorithms may be preferable for initial mapping to enable parallelism.
Report
Share
Report
Share

Recommended
Archiving in linux tar
The tar command stands for tape achieve, which is the most commonly used tape drive backup command used by the Linux system. It allows to quickly access a collection of files and placed them into a highly compressed archive file commonly called tar, gzip and bzip in Linux.
To visit www.excavatorinfo.com
Linux fundamental - Chap 02 perm
This document discusses Linux file permissions and how they work. It explains the components of a Linux file permission listing using the ls -l command as an example. It then covers the meaning of the different parts of the file permission listing like file type, permission modes for owner/group/other, link count, ownership, size, time stamp, and file name. The document also discusses how to determine permissions, change permission modes using chmod, change ownership with chown/chgrp, special permissions like SUID/SGID, and default file permissions set with umask.
101 apend. backups
This document discusses Linux backup strategies and tools. It covers topics like using tar to backup directories and flatten them into single files, compressing backups with tools like gzip and bzip2, and combining compression with tar to create compressed tarballs. Specific utilities are explained, like tar for archiving, rsync for synchronization, and various compression algorithms like bzip2, gzip, and zip. Factors that influence backup strategies like budget, time, and needs are also mentioned.
Linux commands
The document provides an overview of common Linux commands, including:
- cd to change directories
- ls to list directory contents
- mkdir to create directories
- pwd to print the working directory
- rm to remove files
- rmdir to remove directories
- cp to copy files
- find to locate files
- more and less to view file contents
- vi as a basic text editor
- ps to view running processes
- kill to terminate processes
Linux files
This document provides an overview of Linux file management, including how to perform basic file operations like copying, moving, renaming files, and searching for patterns within files. It also describes how to use the vi text editor, compress files using tar and zip utilities, and create both soft and hard links between files on the Linux system. The outline indicates it will also cover file permissions and directory management in upcoming sections.
CMD Command prompts
1. The document discusses fundamental DOS commands like DIR, FORMAT, COPY, PATH, LABEL, VOL, MD, CD, and DEL. It provides examples of how to use each command.
2. Rules for naming files in DOS are described, including allowed/prohibited characters and reserved words. File extensions help identify file types like .exe, .com, .bat, .bak, .bas, etc.
3. Operating systems like DOS, Windows, Linux, MacOS, and UNIX are introduced. MS-DOS is characterized as a disk-based, single-user, single-task OS with a character-based interface. Ways to access DOS commands from Windows
4.8 apend backups
This document discusses backups in Linux systems. It covers various tools for backing up files and directories like tar, rsync, burning software and tape drives. It explains how to create, view, extract tar archives and compress them using gzip or bzip2 to reduce file sizes. Key areas covered include what to backup, local and remote backup locations, and how backups are different for small and large systems. The document also provides a brief overview of zip files and their role in backups.
Rpm Introduction
This document discusses the Red Hat Package Manager (RPM), including what it can do, who uses it, terminology, database location, common operations like install, uninstall, query, and upgrade, and various options for those operations. RPM is used to install, manage, and uninstall software packages on Red Hat, Fedora, CentOS and other Linux distributions. It allows adding, removing, upgrading and verifying packages and their dependencies.
Recommended
Archiving in linux tar
The tar command stands for tape achieve, which is the most commonly used tape drive backup command used by the Linux system. It allows to quickly access a collection of files and placed them into a highly compressed archive file commonly called tar, gzip and bzip in Linux.
To visit www.excavatorinfo.com
Linux fundamental - Chap 02 perm
This document discusses Linux file permissions and how they work. It explains the components of a Linux file permission listing using the ls -l command as an example. It then covers the meaning of the different parts of the file permission listing like file type, permission modes for owner/group/other, link count, ownership, size, time stamp, and file name. The document also discusses how to determine permissions, change permission modes using chmod, change ownership with chown/chgrp, special permissions like SUID/SGID, and default file permissions set with umask.
101 apend. backups
This document discusses Linux backup strategies and tools. It covers topics like using tar to backup directories and flatten them into single files, compressing backups with tools like gzip and bzip2, and combining compression with tar to create compressed tarballs. Specific utilities are explained, like tar for archiving, rsync for synchronization, and various compression algorithms like bzip2, gzip, and zip. Factors that influence backup strategies like budget, time, and needs are also mentioned.
Linux commands
The document provides an overview of common Linux commands, including:
- cd to change directories
- ls to list directory contents
- mkdir to create directories
- pwd to print the working directory
- rm to remove files
- rmdir to remove directories
- cp to copy files
- find to locate files
- more and less to view file contents
- vi as a basic text editor
- ps to view running processes
- kill to terminate processes
Linux files
This document provides an overview of Linux file management, including how to perform basic file operations like copying, moving, renaming files, and searching for patterns within files. It also describes how to use the vi text editor, compress files using tar and zip utilities, and create both soft and hard links between files on the Linux system. The outline indicates it will also cover file permissions and directory management in upcoming sections.
CMD Command prompts
1. The document discusses fundamental DOS commands like DIR, FORMAT, COPY, PATH, LABEL, VOL, MD, CD, and DEL. It provides examples of how to use each command.
2. Rules for naming files in DOS are described, including allowed/prohibited characters and reserved words. File extensions help identify file types like .exe, .com, .bat, .bak, .bas, etc.
3. Operating systems like DOS, Windows, Linux, MacOS, and UNIX are introduced. MS-DOS is characterized as a disk-based, single-user, single-task OS with a character-based interface. Ways to access DOS commands from Windows
4.8 apend backups
This document discusses backups in Linux systems. It covers various tools for backing up files and directories like tar, rsync, burning software and tape drives. It explains how to create, view, extract tar archives and compress them using gzip or bzip2 to reduce file sizes. Key areas covered include what to backup, local and remote backup locations, and how backups are different for small and large systems. The document also provides a brief overview of zip files and their role in backups.
Rpm Introduction
This document discusses the Red Hat Package Manager (RPM), including what it can do, who uses it, terminology, database location, common operations like install, uninstall, query, and upgrade, and various options for those operations. RPM is used to install, manage, and uninstall software packages on Red Hat, Fedora, CentOS and other Linux distributions. It allows adding, removing, upgrading and verifying packages and their dependencies.
4.1 create partitions and filesystems
This document discusses Linux file systems and creating partitions and filesystems in Linux. It covers the following key points:
1. Linux supports various filesystems like ext2, ext3, xfs, and ReiserFS that can be created using mkfs. Swap spaces are created with mkswap.
2. Partitions and filesystems can be created using tools like fdisk, cfdisk, and gpart. Filesystem types include ext3, xfs, FAT, etc.
3. The Filesystem Hierarchy Standard defines the directory structure and recommended layout of files on Linux systems with directories like /bin, /etc, /home, /usr, /var, etc.
101 4.1 create partitions and filesystems
This document provides information about creating partitions and filesystems in Linux. It discusses various Linux filesystem types like ext2, ext3, xfs, reiserfs v3, and vfat. It covers the commands and tools used to create partitions (fdisk, mkfs), filesystems (mkfs), and swap spaces (mkswap, swapon). It also discusses viewing filesystem information, mounting filesystems, and the Filesystem Hierarchy Standard for directory structure in Linux.
101 4.1 create partitions and filesystems
This document discusses Linux file systems and partitioning. It covers commands used to create partitions like fdisk and mkfs, as well as filesystem types like ext3. It also discusses creating and managing swap spaces. The key points are that Linux uses mkfs to format partitions, fdisk to create partitions, and mkswap to initialize swap spaces which are then activated with swapon.
Linux
Linux is an open-source operating system that can run on various hardware. The document discusses various Linux commands and concepts related to directories, files, permissions, users, groups, text editors like vi and vim, process management, disk partitioning and more. It also covers Linux installation, package management, shell scripting and configuring network and services like SSH, web servers and more. Exercises are included to help understand concepts like mount points, journaling and file attributes.
Linux Commands
The document discusses various Linux commands for shells, files, processes, networking and more. It provides descriptions and examples of commands like bash, ls, cat, grep, cut and vi for navigating directories, viewing files, searching contents and extracting fields. It also covers concepts like pipes, redirection, wildcards and regular expressions.
Basic linux day 5
This document discusses user and group administration in Linux. It covers:
- Users must belong to at least one primary group and can belong to up to 15 secondary groups.
- The /etc/passwd, /etc/shadow, and /etc/group files store user and group information.
- Commands like useradd, usermod, and userdel are used to manage users, and groupadd, groupmod, and groupdel are used to manage groups.
- Cron jobs allow scheduling tasks to run on a defined schedule. Cron job schedules are stored in /var/spool/cron for each user, and cron activity is logged to /var/log/cron.
Part 2
The document discusses several MS-DOS commands: Dir, Copy, MD, CD, Del, and Color. Dir lists files and directories, Copy copies files, MD creates directories, CD changes directories, Del deletes files, and Color sets the text and background colors in the command prompt. Examples of using each command with different parameters or switches are provided.
Basic Linux day 1
This document provides an overview of why GNU/Linux is useful, where it is used, the different distributions, basics of the operating system like shell, directory structure, logging in, and commands. Some key benefits of GNU/Linux mentioned are that software is free, it enables advanced multitasking and networking, is multiuser, and provides access to programming languages and open source projects. Common distributions include Red Hat Linux, Debian, and SUSE. The document then covers basics like shell, directory structure, logging in, and demonstrates many common commands like ls, cat, cp, rm, mv, and their usage.
Basic linux day 3
The document discusses different Linux commands for finding files and directories, including find, locate, and grep. It also covers input/output redirection using pipes (|), redirecting standard output and error (> and 2>) to files, and merging standard output and error streams (2>&1). Specific examples are provided on searching for files by name, date, permissions and size, ignoring case sensitivity, counting matches, and displaying line numbers.
File management
File management in c language , which helps us to handle files and can do much operation like copy ,concate etc by use of ANSI C programming language
Basic Linux day 6
The document provides information on various tools used for backups, compression, decompression, and network troubleshooting in Linux. It discusses gzip, bzip2, zip, and tar for compressing and archiving files. It also covers scp for securely copying files over SSH, cURL and wget for downloading files from the web, and network troubleshooting tools like ping, ifconfig, netstat, and telnet.
101 3.4 use streams, pipes and redirects
This document provides an overview of Linux commands for redirecting standard input, output, and error streams. Some key points covered include:
- Redirecting input (<), output (> and >>), and pipes (|) to send output as input to another command
- Common redirection operators like tee to send output to both a file and stdout, and xargs to expand input to command line arguments
- Redirecting standard error (2>) independently from standard output using 2>, 2>>, 2>&1
- Using command substitution (`command` and $(command)) to capture output and use as arguments
- Chaining commands together in pipelines (|) to filter and transform text streams
- Examples of
Basic linux day 4
The document discusses various text editors and process management in Linux. It covers the vi text editor including starting vi, editing files, saving files, and exiting vi. It also discusses the two modes of vi - insert mode and command mode. For process management, it defines what a process is, provides commands like ps and kill to view and terminate processes, and describes zombie processes and how to remove them.
Basic Linux day 2
The document provides information on basic Linux commands for working with files, permissions, users and running levels. Some key points:
- Commands like ls, du, df, free are used to view disk usage, files, permissions and available memory. chmod, chown, chgrp change file/folder permissions and ownership.
- Permissions are represented by rwx for read, write and execute for the user, group and others. Numerical values like 755 can set complex permission schemes.
- Linux has 7 run levels from 0-6 for different system states like shutdown, single-user mode, multi-user with networking. Services are started via links in run level directories.
- Common commands
101 2.1 design hard disk layout
The document provides information about designing hard disk layouts in Linux systems. It discusses partitioning schemes and the use of extended partitions to allow for more than 4 primary partitions. It also covers creating filesystems and swap spaces on partitions using tools like mkfs, mkswap, and mke2fs. Mount points are explained as directories where partitions can be mounted to make their contents accessible in the file system hierarchy.
101 3.3 perform basic file management
This document provides an overview of basic Linux file management commands like cp, mv, rm, mkdir and touch. It discusses using cp to copy files and directories, mv to move and rename files, rm to remove files and directories, mkdir to create directories and touch to update file timestamps. It also covers using find to search for files based on criteria like name, size, permissions and timestamps.
Operating Systems: File Management
The document discusses how operating systems manage files and memory allocation. It explains that from the computer's perspective, there are no actual files, only blocks of allocated and unallocated memory. The file manager in the operating system creates the illusion of files and folders by tracking file locations, allocating and de-allocating memory blocks, and maintaining file records. Files can be stored contiguously, non-contiguously, or via indexed blocks with pointers. Access permissions are managed via access control matrices or command line tools like cacls and chmod.
Basic unix commands_1
This document provides summaries of 30 common Unix commands. It begins with an introduction explaining the purpose and scope of the document. The commands are then listed alphabetically, with each getting a brief 1-2 sentence description. For some commands, simple examples of usage are also provided. The document aims to give beginners a quick overview of the basic usage of important Unix commands.
Basic C L I
This document provides an overview of basic command line interface (CLI) concepts and commands for navigating directories, managing files and permissions, searching for files, redirection and piping, symbolic links, and getting system information. It discusses CLI commands for listing, copying, moving, and deleting files and directories, as well as commands for viewing files, date/time, manuals, and more. The document also covers wildcards, regular expressions, permissions, and resources for getting additional CLI help and information.
Bozorgmeh os lab
This document provides instructions for various exercises to be completed as part of an Operating Systems lab manual. It includes exercises on system calls like fork, exec, wait; I/O system calls; simulating commands like ls and grep; scheduling algorithms like FCFS, SJF, priority, round robin; inter-process communication using shared memory, pipes, message queues; the producer-consumer problem using semaphores; and memory management schemes including paging, segmentation, and file allocation techniques. Example code is provided for implementing different memory management algorithms using concepts like free space list, allocated space list, and block merging.
Proyecto gerencia industrial iupsmpzo.
Este documento describe la empresa Calzado Fion C.A., incluyendo su historia, estructura organizacional, departamentos y procesos. Explica que Calzado Fion es una empresa familiar dedicada a la fabricación de botas de seguridad desde 1960. Describe los departamentos de producción, ventas, compras, administración y finanzas. También resume los modelos de auditoría interna y externa utilizados para evaluar los sistemas de información y procesos de cada departamento.
Scotland's castles Rafa Garcia
Scotland is known for its many historic castles. The document discusses 7 important castles in Scotland - Edinburgh Castle, Caerlaverock Castle, Edzell Castle, Gwrych Castle, Bothwell Castle, Drum Castle, and Fraser Castle. For each castle, brief details are provided about its location in Scotland and notable features. The capital of Scotland is Edinburgh and the official languages are English, Scottish Gaelic, and Scots. Kilts are a symbol of traditional Scottish dress.
More Related Content
What's hot
4.1 create partitions and filesystems
This document discusses Linux file systems and creating partitions and filesystems in Linux. It covers the following key points:
1. Linux supports various filesystems like ext2, ext3, xfs, and ReiserFS that can be created using mkfs. Swap spaces are created with mkswap.
2. Partitions and filesystems can be created using tools like fdisk, cfdisk, and gpart. Filesystem types include ext3, xfs, FAT, etc.
3. The Filesystem Hierarchy Standard defines the directory structure and recommended layout of files on Linux systems with directories like /bin, /etc, /home, /usr, /var, etc.
101 4.1 create partitions and filesystems
This document provides information about creating partitions and filesystems in Linux. It discusses various Linux filesystem types like ext2, ext3, xfs, reiserfs v3, and vfat. It covers the commands and tools used to create partitions (fdisk, mkfs), filesystems (mkfs), and swap spaces (mkswap, swapon). It also discusses viewing filesystem information, mounting filesystems, and the Filesystem Hierarchy Standard for directory structure in Linux.
101 4.1 create partitions and filesystems
This document discusses Linux file systems and partitioning. It covers commands used to create partitions like fdisk and mkfs, as well as filesystem types like ext3. It also discusses creating and managing swap spaces. The key points are that Linux uses mkfs to format partitions, fdisk to create partitions, and mkswap to initialize swap spaces which are then activated with swapon.
Linux
Linux is an open-source operating system that can run on various hardware. The document discusses various Linux commands and concepts related to directories, files, permissions, users, groups, text editors like vi and vim, process management, disk partitioning and more. It also covers Linux installation, package management, shell scripting and configuring network and services like SSH, web servers and more. Exercises are included to help understand concepts like mount points, journaling and file attributes.
Linux Commands
The document discusses various Linux commands for shells, files, processes, networking and more. It provides descriptions and examples of commands like bash, ls, cat, grep, cut and vi for navigating directories, viewing files, searching contents and extracting fields. It also covers concepts like pipes, redirection, wildcards and regular expressions.
Basic linux day 5
This document discusses user and group administration in Linux. It covers:
- Users must belong to at least one primary group and can belong to up to 15 secondary groups.
- The /etc/passwd, /etc/shadow, and /etc/group files store user and group information.
- Commands like useradd, usermod, and userdel are used to manage users, and groupadd, groupmod, and groupdel are used to manage groups.
- Cron jobs allow scheduling tasks to run on a defined schedule. Cron job schedules are stored in /var/spool/cron for each user, and cron activity is logged to /var/log/cron.
Part 2
The document discusses several MS-DOS commands: Dir, Copy, MD, CD, Del, and Color. Dir lists files and directories, Copy copies files, MD creates directories, CD changes directories, Del deletes files, and Color sets the text and background colors in the command prompt. Examples of using each command with different parameters or switches are provided.
Basic Linux day 1
This document provides an overview of why GNU/Linux is useful, where it is used, the different distributions, basics of the operating system like shell, directory structure, logging in, and commands. Some key benefits of GNU/Linux mentioned are that software is free, it enables advanced multitasking and networking, is multiuser, and provides access to programming languages and open source projects. Common distributions include Red Hat Linux, Debian, and SUSE. The document then covers basics like shell, directory structure, logging in, and demonstrates many common commands like ls, cat, cp, rm, mv, and their usage.
Basic linux day 3
The document discusses different Linux commands for finding files and directories, including find, locate, and grep. It also covers input/output redirection using pipes (|), redirecting standard output and error (> and 2>) to files, and merging standard output and error streams (2>&1). Specific examples are provided on searching for files by name, date, permissions and size, ignoring case sensitivity, counting matches, and displaying line numbers.
File management
File management in c language , which helps us to handle files and can do much operation like copy ,concate etc by use of ANSI C programming language
Basic Linux day 6
The document provides information on various tools used for backups, compression, decompression, and network troubleshooting in Linux. It discusses gzip, bzip2, zip, and tar for compressing and archiving files. It also covers scp for securely copying files over SSH, cURL and wget for downloading files from the web, and network troubleshooting tools like ping, ifconfig, netstat, and telnet.
101 3.4 use streams, pipes and redirects
This document provides an overview of Linux commands for redirecting standard input, output, and error streams. Some key points covered include:
- Redirecting input (<), output (> and >>), and pipes (|) to send output as input to another command
- Common redirection operators like tee to send output to both a file and stdout, and xargs to expand input to command line arguments
- Redirecting standard error (2>) independently from standard output using 2>, 2>>, 2>&1
- Using command substitution (`command` and $(command)) to capture output and use as arguments
- Chaining commands together in pipelines (|) to filter and transform text streams
- Examples of
Basic linux day 4
The document discusses various text editors and process management in Linux. It covers the vi text editor including starting vi, editing files, saving files, and exiting vi. It also discusses the two modes of vi - insert mode and command mode. For process management, it defines what a process is, provides commands like ps and kill to view and terminate processes, and describes zombie processes and how to remove them.
Basic Linux day 2
The document provides information on basic Linux commands for working with files, permissions, users and running levels. Some key points:
- Commands like ls, du, df, free are used to view disk usage, files, permissions and available memory. chmod, chown, chgrp change file/folder permissions and ownership.
- Permissions are represented by rwx for read, write and execute for the user, group and others. Numerical values like 755 can set complex permission schemes.
- Linux has 7 run levels from 0-6 for different system states like shutdown, single-user mode, multi-user with networking. Services are started via links in run level directories.
- Common commands
101 2.1 design hard disk layout
The document provides information about designing hard disk layouts in Linux systems. It discusses partitioning schemes and the use of extended partitions to allow for more than 4 primary partitions. It also covers creating filesystems and swap spaces on partitions using tools like mkfs, mkswap, and mke2fs. Mount points are explained as directories where partitions can be mounted to make their contents accessible in the file system hierarchy.
101 3.3 perform basic file management
This document provides an overview of basic Linux file management commands like cp, mv, rm, mkdir and touch. It discusses using cp to copy files and directories, mv to move and rename files, rm to remove files and directories, mkdir to create directories and touch to update file timestamps. It also covers using find to search for files based on criteria like name, size, permissions and timestamps.
Operating Systems: File Management
The document discusses how operating systems manage files and memory allocation. It explains that from the computer's perspective, there are no actual files, only blocks of allocated and unallocated memory. The file manager in the operating system creates the illusion of files and folders by tracking file locations, allocating and de-allocating memory blocks, and maintaining file records. Files can be stored contiguously, non-contiguously, or via indexed blocks with pointers. Access permissions are managed via access control matrices or command line tools like cacls and chmod.
Basic unix commands_1
This document provides summaries of 30 common Unix commands. It begins with an introduction explaining the purpose and scope of the document. The commands are then listed alphabetically, with each getting a brief 1-2 sentence description. For some commands, simple examples of usage are also provided. The document aims to give beginners a quick overview of the basic usage of important Unix commands.
Basic C L I
This document provides an overview of basic command line interface (CLI) concepts and commands for navigating directories, managing files and permissions, searching for files, redirection and piping, symbolic links, and getting system information. It discusses CLI commands for listing, copying, moving, and deleting files and directories, as well as commands for viewing files, date/time, manuals, and more. The document also covers wildcards, regular expressions, permissions, and resources for getting additional CLI help and information.
Bozorgmeh os lab
This document provides instructions for various exercises to be completed as part of an Operating Systems lab manual. It includes exercises on system calls like fork, exec, wait; I/O system calls; simulating commands like ls and grep; scheduling algorithms like FCFS, SJF, priority, round robin; inter-process communication using shared memory, pipes, message queues; the producer-consumer problem using semaphores; and memory management schemes including paging, segmentation, and file allocation techniques. Example code is provided for implementing different memory management algorithms using concepts like free space list, allocated space list, and block merging.
What's hot (20)
Viewers also liked
Proyecto gerencia industrial iupsmpzo.
Este documento describe la empresa Calzado Fion C.A., incluyendo su historia, estructura organizacional, departamentos y procesos. Explica que Calzado Fion es una empresa familiar dedicada a la fabricación de botas de seguridad desde 1960. Describe los departamentos de producción, ventas, compras, administración y finanzas. También resume los modelos de auditoría interna y externa utilizados para evaluar los sistemas de información y procesos de cada departamento.
Scotland's castles Rafa Garcia
Scotland is known for its many historic castles. The document discusses 7 important castles in Scotland - Edinburgh Castle, Caerlaverock Castle, Edzell Castle, Gwrych Castle, Bothwell Castle, Drum Castle, and Fraser Castle. For each castle, brief details are provided about its location in Scotland and notable features. The capital of Scotland is Edinburgh and the official languages are English, Scottish Gaelic, and Scots. Kilts are a symbol of traditional Scottish dress.
Apresentação Nativi
A NATIVI surge com proposta de criatividade por trás da reciclagem e reutilização de materiais, desenvolvendo produtos em malhas com fios de Pet, Bambu, Algodão Orgânico. Sua fábrica fica em Franca, São Paulo, próxima ao Parque Nacional da Serra da Canastra. Cada produto da linha NATIVI utiliza matérias-primas ecológicas e sustentáveis como PET, bambu e algodão orgânico.
Artículo sobre consideraciones fundamentales del muestreo
El documento discute los conceptos fundamentales del muestreo, incluyendo cómo determinar el tamaño de la muestra y los métodos para seleccionar la muestra. Explica que el muestreo es una técnica estadística útil para obtener información sobre una población más grande de manera más eficiente que medir a toda la población. También describe algunos métodos comunes de muestreo como el muestreo aleatorio simple y el muestreo estratificado. El propósito del muestreo es poder generalizar los resultados de la muestra a la población total
Phrases (1) (1)
1) A phrase is a group of words that functions as a noun, verb, or adjective within a sentence. There are different types of phrases including noun phrases, adjective phrases, verb phrases, prepositional phrases, gerund phrases, and infinitive phrases.
2) A sentence is a group of words that forms a complete thought, starting with a capital letter and ending with a period. It contains phrases such as a noun phrase, verb phrase, and other elements.
3) Examples of different phrases are provided such as a prepositional phrase starting with a preposition and ending with an object, and a gerund phrase containing a gerund verb and other elements.
Proceso de manufactura unidad iii
Este documento describe los conceptos básicos de termodinámica involucrados en el corte de metales, incluyendo los tipos de virutas producidas y las variables importantes de corte. También discute el uso de tablas físicas y químicas relacionadas con la termodinámica del corte de metales y los aspectos de seguridad industrial asociados con el desprendimiento de virutas durante el proceso de manufactura.
Large-Scale ETL Data Flows With Data Pipeline and Dataduct
As data volumes grow, managing and scaling data pipelines for ETL and batch processing can be daunting. With more than 13.5 million learners worldwide, hundreds of courses, and thousands of instructors, Coursera manages over a hundred data pipelines for ETL, batch processing, and new product development.
In this session, we dive deep into AWS Data Pipeline and Dataduct, an open source framework built at Coursera to manage pipelines and create reusable patterns to expedite developer productivity. We share the lessons learned during our journey: from basic ETL processes, such as loading data from Amazon RDS to Amazon Redshift, to more sophisticated pipelines to power recommendation engines and search services.
Go Zero to Big Data in 15 Minutes with the Hortonworks Sandbox
Hortonworks recently unveiled the Hortonworks Sandbox, a free, comprehensive, easy-to-use, hands-on learning environment that provides the fastest onramp for anyone interested in learning, evaluating or using Apache Hadoop™ in an enterprise.
This interactive webinar will discuss and demo features of the Hortonworks Sandbox, including:
-How to download and use the Sandbox tutorials.
-How to upload your own datasets to test and validate the use of Apache Hadoop.
-Demos of features and use cases for your very own Hortonworks Sandbox.
Data Process Systems, connecting everything
This document summarizes Patrick de Vries' presentation on connecting everything at the Hadoop Summit 2016. The presentation discusses KPN's use of Hadoop to manage increasing data and network capacity needs. It outlines KPN's data flow process from source systems to Hadoop for processing and generating reports. The presentation also covers lessons learned in implementing Hadoop including having strong executive support, addressing cultural challenges around data ownership, and leveraging existing investments. Finally, it promotes joining a new TELCO Hadoop community for telecommunications providers to share use cases and lessons.
Impression techiques / implant dentistry course/ implant dentistry coursevvv
Indian Dental Academy: will be one of the most relevant and exciting training
center with best faculty and flexible training programs for dental
professionals who wish to advance in their dental practice,Offers certified
courses in Dental implants,Orthodontics,Endodontics,Cosmetic Dentistry,
Prosthetic Dentistry, Periodontics and General Dentistry.
Airflow at WePay
A 20 minute talk about how WePay runs airflow. Discusses usage and operations. Also covers running Airflow in Google cloud.
Video of the talk is available here:
https://wepayinc.box.com/s/hf1chwmthuet29ux2a83f5quc8o5q18k
Hadoop & Spark Performance tuning using Dr. Elephant
Dr. Elephant is a tool for the users of Hadoop to help them understand, analyze and tune their Hadoop/Spark applications easily, thus improving their productivity and the cluster’s efficiency. It analyzes the Hadoop and Spark jobs using a set of pluggable, configurable, rule-based heuristics that provide insights on how a job performed, and then uses the results to make suggestions about how to tune the job to make it perform more efficiently.
Choice Based Credit System
This document outlines regulations for Choice Based Credit Semester System (CBCS) at HPU. Some key points:
- Courses are divided into compulsory, core, elective, and general interest categories with associated credit hours.
- Programs last 3-5 years and are divided into semesters with teaching hours and calendar.
- Assessment includes continuous comprehensive evaluation and end semester exams weighted 50-50.
- Grades are assigned on a 10 point scale and used to calculate GPA and CGPA for student performance.
- Regulations provide guidance on course combinations and sequencing for different undergraduate programs and majors.
Hadoop in Healthcare Systems
This document discusses how Hadoop can help address challenges in healthcare services. In low penetration regions, big data can help remotely collect medical data and provide a single scalable solution to reduce the rural-urban divide. In high penetration regions, big data can encourage patient self-awareness and self-management to reduce pressure on primary care providers and expensive unplanned hospitalizations. A case study is presented on using Hadoop for chronic patient self-management that is scalable, fault tolerant, open source, robust, interoperable and secure. The case study resulted in patients feeling empowered and lower strains on primary and emergency care centers.
Hadoop Performance Optimization at Scale, Lessons Learned at Twitter
- Profiling Hadoop jobs at Twitter revealed that compression/decompression of intermediate data and deserialization of complex object keys were very expensive. Optimizing these led to performance improvements of 1.5x or more.
- Using columnar file formats like Apache Parquet allows reading only needed columns, avoiding deserialization of unused data. This led to gains of up to 3x.
- Scala macros were developed to generate optimized implementations of Hadoop's RawComparator for common data types, avoiding deserialization for sorting.
Big Data Benchmarking
Covers different types of big data benchmarking, different suites, details into terasort, demo with TPCx-HS
Meetup Details of presentation:
http://www.meetup.com/lspe-in/events/203918952/
Dental implants
Dental implants can be used to support crowns, bridges, or dentures for patients who are missing one or more teeth. There are several types of implants based on placement location and material. Implant surgery involves placing the implant fixture into the jawbone, with some procedures allowing the implant to heal below gum tissue or protruding above gum tissue. Regular dental visits are needed after implant placement to monitor bone and soft tissue health around the implants.
Viewers also liked (20)
Artículo sobre consideraciones fundamentales del muestreo
Artículo sobre consideraciones fundamentales del muestreo
Large-Scale ETL Data Flows With Data Pipeline and Dataduct
Large-Scale ETL Data Flows With Data Pipeline and Dataduct
Go Zero to Big Data in 15 Minutes with the Hortonworks Sandbox
Go Zero to Big Data in 15 Minutes with the Hortonworks Sandbox
Impression techiques / implant dentistry course/ implant dentistry coursevvv
Impression techiques / implant dentistry course/ implant dentistry coursevvv
Hadoop & Spark Performance tuning using Dr. Elephant
Hadoop & Spark Performance tuning using Dr. Elephant
Hadoop Performance Optimization at Scale, Lessons Learned at Twitter
Hadoop Performance Optimization at Scale, Lessons Learned at Twitter
Similar to HadoopCompression
Compression Options in Hadoop - A Tale of Tradeoffs
Yahoo! is one of the most-visited web sites in the world. It runs one of the largest private cloud infrastructures, one that operates on petabytes of data every day. Being able to store and manage that data well is essential to the efficient functioning of Yahoo!`s Hadoop clusters. A key component that enables this efficient operation is data compression. With regard to compression algorithms, there is an underlying tension between compression ratio and compression performance. Consequently, Hadoop provides support for several compression algorithms, including gzip, bzip2, Snappy, LZ4 and others. This plethora of options can make it difficult for users to select appropriate codecs for their MapReduce jobs. This paper attempts to provide guidance in that regard. Performance results with Gridmix and with several corpuses of data are presented. The paper also describes enhancements we have made to the bzip2 codec that improve its performance. This will be of particular interest to the increasing number of users operating on “Big Data” who require the best possible ratios. The impact of using the Intel IPP libraries is also investigated; these have the potential to improve performance significantly. Finally, a few proposals for future enhancements to Hadoop in this area are outlined.
Compression Options in Hadoop - A Tale of Tradeoffs
Yahoo! is one of the most-visited web sites in the world. It runs one of the largest private cloud infrastructures, one that operates on petabytes of data every day. Being able to store and manage that data well is essential to the efficient functioning of Yahoo!`s Hadoop clusters. A key component that enables this efficient operation is data compression. With regard to compression algorithms, there is an underlying tension between compression ratio and compression performance. Consequently, Hadoop provides support for several compression algorithms, including gzip, bzip2, Snappy, LZ4 and others. This plethora of options can make it difficult for users to select appropriate codecs for their MapReduce jobs. This paper attempts to provide guidance in that regard. Performance results with Gridmix and with several corpuses of data are presented. The paper also describes enhancements we have made to the bzip2 codec that improve its performance. This will be of particular interest to the increasing number of users operating on “Big Data” who require the best possible ratios. The impact of using the Intel IPP libraries is also investigated; these have the potential to improve performance significantly. Finally, a few proposals for future enhancements to Hadoop in this area are outlined.
Hadoop Summit San Jose 2013: Compression Options in Hadoop - A Tale of Tradeo...
Yahoo! is one of the most-visited web sites in the world. It runs one of the largest private cloud infrastructures, one that operates on petabytes of data every day. Being able to store and manage that data well is essential to the efficient functioning of Yahoo's Hadoop clusters. A key component that enables this efficient operation is data compression.
With regard to compression algorithms, there is an underlying tension between compression ratio and compression performance. Consequently, Hadoop provides support for several compression algorithms, including gzip, bzip2, Snappy, LZ4 and others. This plethora of options can make it difficult for users to select appropriate codecs for their MapReduce jobs. This paper attempts to provide guidance in that regard. Performance results with Gridmix and with several corpuses of data are presented.
The paper also describes enhancements we have made to the bzip2 codec that improve its performance. This will be of particular interest to the increasing number of users operating on "Big Data" who require the best possible ratios. The impact of using the Intel IPP libraries is also investigated; these have the potential to improve performance significantly. Finally, a few proposals for future enhancements to Hadoop in this area are outlined.
August 2013 HUG: Compression Options in Hadoop - A Tale of Tradeoffs
Yahoo! is one of the most-visited web sites in the world. It runs one of the largest private cloud infrastructures, one that operates on petabytes of data every day. Being able to store and manage that data well is essential to the efficient functioning of Yahoo!`s Hadoop clusters. A key component that enables this efficient operation is data compression. With regard to compression algorithms, there is an underlying tension between compression ratio and compression performance. Consequently, Hadoop provides support for several compression algorithms, including gzip, bzip2, Snappy, LZ4 and others. This plethora of options can make it difficult for users to select appropriate codecs for their MapReduce jobs. This talk attempts to provide guidance in that regard. Performance results with Gridmix and with several corpuses of data are presented. The talk also describes enhancements we have made to the bzip2 codec that improve its performance. This will be of particular interest to the increasing number of users operating on “Big Data” who require the best possible ratios. The impact of using the Intel IPP libraries is also investigated; these have the potential to improve performance significantly. Finally, a few proposals for future enhancements to Hadoop in this area are outlined.
Speaker: Govind Kamat, Member of Technical Staff, Yahoo!
Analyze corefile and backtraces with GDB for Mysql/MariaDB on Linux - Nilanda...
Mydbops 9th Opensource Database Meetup - April 2021
Analyze Corefile and backtraces with GDB for Mysql/MariaDB on Linux
Compression Commands in Linux
The document discusses several Linux commands for compressing and archiving files, including gzip, bzip2, tar, compress, zip, and unzip. Gzip and bzip2 can compress individual files into .gz and .bz2 formats respectively, with bzip2 typically providing better compression than gzip at the cost of speed. The tar command is used to archive multiple files together into a single tar file, which can then be compressed further using gzip or bzip2. Compress, zip, and unzip allow compressing and extracting files in additional formats.
Zipnotes
The document provides information about the Archive::Zip module in Perl, which allows a program to create, manipulate, read and write zip archive files. It describes how to create a new archive, add and modify members, set compression options, and read from or write to zip files. Various methods are explained, including constructing zip objects, adding/removing members, and getting/setting member attributes.
Hadoop compression analysis strata conference
The document compares several compression formats used in Hadoop: Snappy, LZ4, LZO, bzip2, gzip, and zlib. It provides information on their algorithms, file extensions, Java support, strengths, weaknesses, compression ratios, and speeds on sample data. Snappy is the fastest for compression but slowest for decompression. LZ4 and LZO provide very fast compression and decompression. Bzip2 achieves the highest compression ratio but is the slowest overall.
Hadoop compression strata conference
The document discusses data compression in Hadoop. There are several benefits to compressing data in Hadoop including reduced storage needs, faster data transfers, and less disk I/O. However, compression increases CPU usage. There are different compression algorithms and file formats that can be used including gzip, bzip2, LZO, LZ4, zlib, snappy, Avro, SequenceFiles, RCFiles, ORC, and Parquet. The best options depend on factors like the data, query needs, support in Hadoop distributions, and whether the data schema may evolve. Columnar formats like Parquet provide better query performance but slower write speeds.
G zip compresser ppt
The document describes a file compression application. It allows large files to be compressed to reduce file size and speed up transfers. It uses the GZip and Deflate compression standards which save space and time by compressing data. The application provides functions for compressing files into a zip archive and decompressing files from the archive. It produces compressed files with smaller sizes than the originals, allowing more efficient storage, emailing, and downloading of files.
Assignment 1 MapReduce With Hadoop
This document provides instructions for an assignment on MapReduce with Hadoop. It includes setting up the environment, writing a WordCount program as a first example, and estimating Euler's constant using a Monte Carlo method as a second example. The document asks multiple questions at each step to help the reader understand and complete the tasks. It covers downloading and configuring Hadoop, writing Map and Reduce functions, compiling and running jobs on a Hadoop cluster, and analyzing the results.
Linux Common Command
This document provides solutions to common Linux commands and tasks. It covers topics such as environment setting, hardware and system specifications, file editing and compression, networking, performance monitoring, package management with RPM, and multimedia. Solutions are provided for tasks like changing the startup runlevel, monitoring swap size, editing files, getting the network IP and registering the hostname, and burning discs.
Hadoop introduction
This document provides an introduction to Hadoop and its core components. It discusses HDFS and how it provides a scalable, fault-tolerant distributed file system. It also covers MapReduce and how it allows distributed processing of large datasets across clusters. Finally, it mentions some newer technologies like YARN, Spark, and Tez that improve on and extend the original MapReduce framework in Hadoop.
Part 4 of 'Introduction to Linux for bioinformatics': Managing data
This is part 4 of the training session 'Introduction to Linux for bioinformatics'. We shows basics of data management, and tips for handling big data effectively. Interested in following this training session? Please contact me at http://www.jakonix.be/contact.html
CDS Filtering Program - User Manual
CDS Filtering is a little python program allowing you to filter your predicted ORFs, CDSs, RNA, or any other type of DNA or RNA sequences.
Download Link for CDS Filtering Program : https://goo.gl/RiAtC0
The Rise of ZStandard: Apache Spark/Parquet/ORC/Avro
Zstandard is a fast compression algorithm which you can use in Apache Spark in various way. In this talk, I briefly summarized the evolution history of Apache Spark in this area and four main use cases and the benefits and the next steps:
1) ZStandard can optimize Spark local disk IO by compressing shuffle files significantly. This is very useful in K8s environments. It’s beneficial not only when you use `emptyDir` with `memory` medium, but also it maximizes OS cache benefit when you use shared SSDs or container local storage. In Spark 3.2, SPARK-34390 takes advantage of ZStandard buffer pool feature and its performance gain is impressive, too.
2) Event log compression is another area to save your storage cost on the cloud storage like S3 and to improve the usability. SPARK-34503 officially switched the default event log compression codec from LZ4 to Zstandard.
3) Zstandard data file compression can give you more benefits when you use ORC/Parquet files as your input and output. Apache ORC 1.6 supports Zstandardalready and Apache Spark enables it via SPARK-33978. The upcoming Parquet 1.12 will support Zstandard compression.
4) Last, but not least, since Apache Spark 3.0, Zstandard is used to serialize/deserialize MapStatus data instead of Gzip.
There are more community works to utilize Zstandard to improve Spark. For example, Apache Avro community also supports Zstandard and SPARK-34479 aims to support Zstandard in Spark’s avro file format in Spark 3.2.0.
7-zip compression settings guide
7-zip User manual to set best compression settings for their needs
This guide is created to help 7-zip users understand what settings do what and how to achieve best compression on their systems, for this guide I am using 7-zip gui however I believe reading this guide will help you with commend line version as well.
For the web version you can go here
http://digitalstudio7.blogspot.com/2014/03/7-zip-compression-settings-guide.html
Take a look at this pages as well
http://www.youtube.com/user/Avtoandlevan
https://twitter.com/Studio76HD
digitalstudio7.blogspot.com
Golang execution modes
Golang supports several execution modes that determine how code is built and linked. The main modes are:
- exe: Default for main packages, builds everything into a single executable.
- shared: Combines packages into a shared library for dynamic linking, reducing binary size. Currently only supported on Linux.
- archive: Default for non-main packages, builds into a .a library file.
- c-shared/c-archive: Builds packages into a single C shared library/archive file for calling from C/C++.
- plugin: Builds packages into a shared library that can be dynamically loaded at runtime, similar to dlopen. Currently only supported on Linux.
List the most common arguments and describe the effect of that argumen.docx
List the most common arguments and describe the effect of that argument of the utilities below: 7-zip Gzip Rar Tar Zip
Solution
1) 7-zip : The 7-zip is an open source. it makes easy to obtain and use.
it has main features like high compression ration in 7z format.
-Self extraction capabalities for 7z format.Extra features include password protection as well as adjustable compression levels, compatibility with multiple archive formats.It aslo provides command line and Graphical user interface.
Most common arguments and effects :
Command Line (non-switch)
2) g-zip :it is a compression utility designed to be a replacement for compress.Basically it find matching strings throughout the file and replaces them to reduce the file size.
Most common arguments and effects :
Command-Line :
3) Rar :it is used to compress the media content that has to be shared over the internet.Files can be divided into multriple segments for compression. Further abilities include error recovery. and it supports file spanning.
Most common arguments and effects :
Archive compression Ratio
4) Tar : A TAR file is an archive file that contains one or more files inside. This is often done to ease distribution of a large set of files over the Internet.  Its initial purpose was to backup data to sequential I/O devices.
Cpmmand Line arguments :
5) Zip : it is a popular format widely used in internet. Like other archives Zip files are data containers,they store one or several files in compressed format.
.
Aggregate standard for Netapp storage 7 mode
1. Storage teams create aggregates using naming conventions like aggr0, aggr1 to provision storage. They decide the configuration including the RAID type, number of disks, and disk size.
2. When creating an aggregate, factors like recovery speed, data assurance, and storage space must be considered. Larger RAID groups improve performance but increase risk of data loss if multiple disks fail, while smaller groups reduce this risk but decrease performance.
3. Guidelines for RAID group sizing depend on disk type, with ATA/SATA generally having smaller groups than FC/SAS. The default sizes balance speed, protection, and space utilization, though the maximum sizes allow flexibility based on needs.
Similar to HadoopCompression (20)
Compression Options in Hadoop - A Tale of Tradeoffs
Compression Options in Hadoop - A Tale of Tradeoffs
Compression Options in Hadoop - A Tale of Tradeoffs
Compression Options in Hadoop - A Tale of Tradeoffs
Hadoop Summit San Jose 2013: Compression Options in Hadoop - A Tale of Tradeo...
Hadoop Summit San Jose 2013: Compression Options in Hadoop - A Tale of Tradeo...
August 2013 HUG: Compression Options in Hadoop - A Tale of Tradeoffs
August 2013 HUG: Compression Options in Hadoop - A Tale of Tradeoffs
Analyze corefile and backtraces with GDB for Mysql/MariaDB on Linux - Nilanda...
Analyze corefile and backtraces with GDB for Mysql/MariaDB on Linux - Nilanda...
Part 4 of 'Introduction to Linux for bioinformatics': Managing data
Part 4 of 'Introduction to Linux for bioinformatics': Managing data
The Rise of ZStandard: Apache Spark/Parquet/ORC/Avro
The Rise of ZStandard: Apache Spark/Parquet/ORC/Avro
List the most common arguments and describe the effect of that argumen.docx
List the most common arguments and describe the effect of that argumen.docx
HadoopCompression
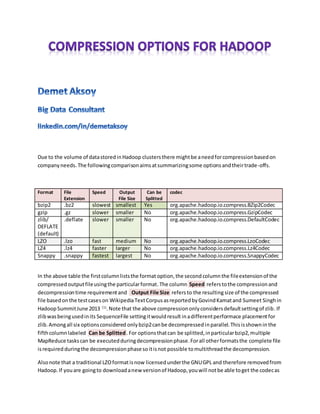
- 1. Due to the volume of datastoredinHadoop clustersthere mightbe aneedforcompressionbasedon companyneeds. The followingcomparisonaimsatsummarizingsome optionsandtheirtrade-offs. Format File Extension Speed Output File Size Can be Splitted codec bzip2 .bz2 slowest smallest Yes org.apache.hadoop.io.compress.BZip2Codec gzip .gz slower smaller No org.apache.hadoop.io.compress.GzipCodec zlib/ DEFLATE (default) .deflate slower smaller No org.apache.hadoop.io.compress.DefaultCodec LZO .lzo fast medium No org.apache.hadoop.io.compress.LzoCodec LZ4 .lz4 faster larger No org.apache.hadoop.io.compress.Lz4Codec Snappy .snappy fastest largest No org.apache.hadoop.io.compress.SnappyCodec In the above table the firstcolumnliststhe format option,the second column the fileextensionof the compressed outputfileusingthe particularformat.The column Speed referstothe compressionand decompressiontime requirementand Output File Size refersto the resultingsize of the compressed file basedonthe testcaseson WikipediaTextCorpusasreportedbyGovindKamatand Sumeet Singhin HadoopSummitJune 2013 (1) .Note that the above compressiononlyconsidersdefaultsettingof zlib.If zlibwasbeingusedinits SequenceFile settingitwouldresult inadifferentperformace placementfor zlib. Amongall six optionsconsidered onlybzip2canbe decompressedinparallel.Thisisshownin the fifthcolumnlabeled Can be Splitted.For optionsthatcan be splitted,inparticularbzip2,multiple MapReduce taskscan be executedduringdecompressionphase.Forall otherformatsthe complete file isrequired duringthe decompressionphasesoitisnot possible tomultithreadthe decompression. Alsonote that a traditional LZOformatisnow licensedunderthe GNUGPL and therefore removedfrom Hadoop. If youare goingto downloadanew versionof Hadoop,youwill notbe able toget the codecas
- 2. part of yourdownload.Therefore the codecshouldbe downloadedseparatelyandenabledmanually and thenyouwill be able touse it as before.LZOisstill supportedwithinthe code base if you wantto continue usingit. It ispossible touse differentcompressiontechniquesatdifferentphasesof MapReduce since the requirementsof eachphase showsvariations.Itispossible touse compression/decompressiononlyata particularphase.Forinstance,duringShuffleandSortphase compressioncanbe quite useful toreduce the networktransferlatency. FastercodecsasLZO,LZ4 or Snappycan be preferred inthisphase toavoid additional CPUoverheadduringcompression/decompression.Incontrastduringthe initial Mapphase it ispossible toinvestinslowercodecssuchas bzip2or zlibwithSequenceFile settingtomake use of parallelismatthisstage.Duringthe Reduce phase gzipcan be used fordata interchange forchained jobs.It ispossible touse bzip2as well duringthe reduce phase asafastercodec. Compressionduring Reduce phase helpsreduce storage requirementsforarchival dataand improve write speeds. The decisiononwhetherto applycompressionforanyphase of the MapReduce jobisa decisionthat can be made basedon the trade-offsbetweenreducedstorage,networktransferloadandthe additional CPUoverheadrunningthe compressioncodec.Forbasictaskswhere data transferoverheads are significantlylarger,the clientswouldbenefitlargelyoncompressionaslongas the CPU overheadon the commoditymachinesdonotresultinan additional overhead. Please note thatHadoopjobsare data intensive andbasedonthe clients’hardware,e.g.,racksversus commoditymachine clusters,optical networkconnectionversusall the waytooldfashionedRS232 connections, decisionsoncompressioncanbe made asa general solutionora particularjobbased solution. (1) GovindKamatand SumeetSingh,CompressionOptionsInHadoop – A Tale of Tradeoffs, HadoopSummit,SanJose,June 2013, http://www.slideshare.net/Hadoop_Summit/kamat- singh-june27425pmroom210cv2