Abstract
Large ConvolutionalNetwork model이 뛰어난 분류 성능을 보여줬는데
왜 그것이 성능이 잘 나오고, 어떻게 개선되었는지 명확한 이해가 없음.
위와 같은 문제 다루기 위해 시각화 기술 소개함.
• 중간층(intermediate feature)와 분류기의 동작의 통찰력 줌.
• 시각화 기술을 통해 기존 (Krizhevsky et al 2012)의 분류기 성능을 능가하는 모델
아키텍쳐를 찾음.
다른 모델 레이어들로부터 성능 기여를 찾기 위한 연구를 함.
만들어진 ImageNet 모델이 다른 데이터 셋에도 잘
일반화가 된 것을 확인함.
2
4.
Introduction
Convolutional Network분류기가 성공 할 수 있었던 이유
• 1) 많은 training set
• 2) 강력한 GPU
• 3) Drop out
Convnet 모델이 성공적이었음에도 불구하고 그와 같은 성능을 어떻게 만들었는지 또는 그 복잡한 모델
의 행동이나 내부 동작 등을 이해하기 힘듦.
이 논문에서는 모델에 어떤 layer에서 각 feature map을 활성화시키는 input들을 보여 줄 수 있는 시각화
기술을 소개함.
• Training 동안 feature들이 진화하는 걸 볼 수 있음.
• 모델이 가진 잠재적인 문제점을 볼 수 있음.
• Multi-layered Deconvolutional Network (Zeiler et al. 2011)를 사용함.
이미지 일부분을 숨김으로써 Scene의 어떤 부분을 드러내는 것이
분류기에서 중요한지 연구함.
시각화 기술을 통해 다른 아키텍처들을 연구하고 더 능가하는 모델 발견함
또한 이 모델을 가지고 다른 데이터 셋에서 모델의 일반화 능력을 연구함.
3
5.
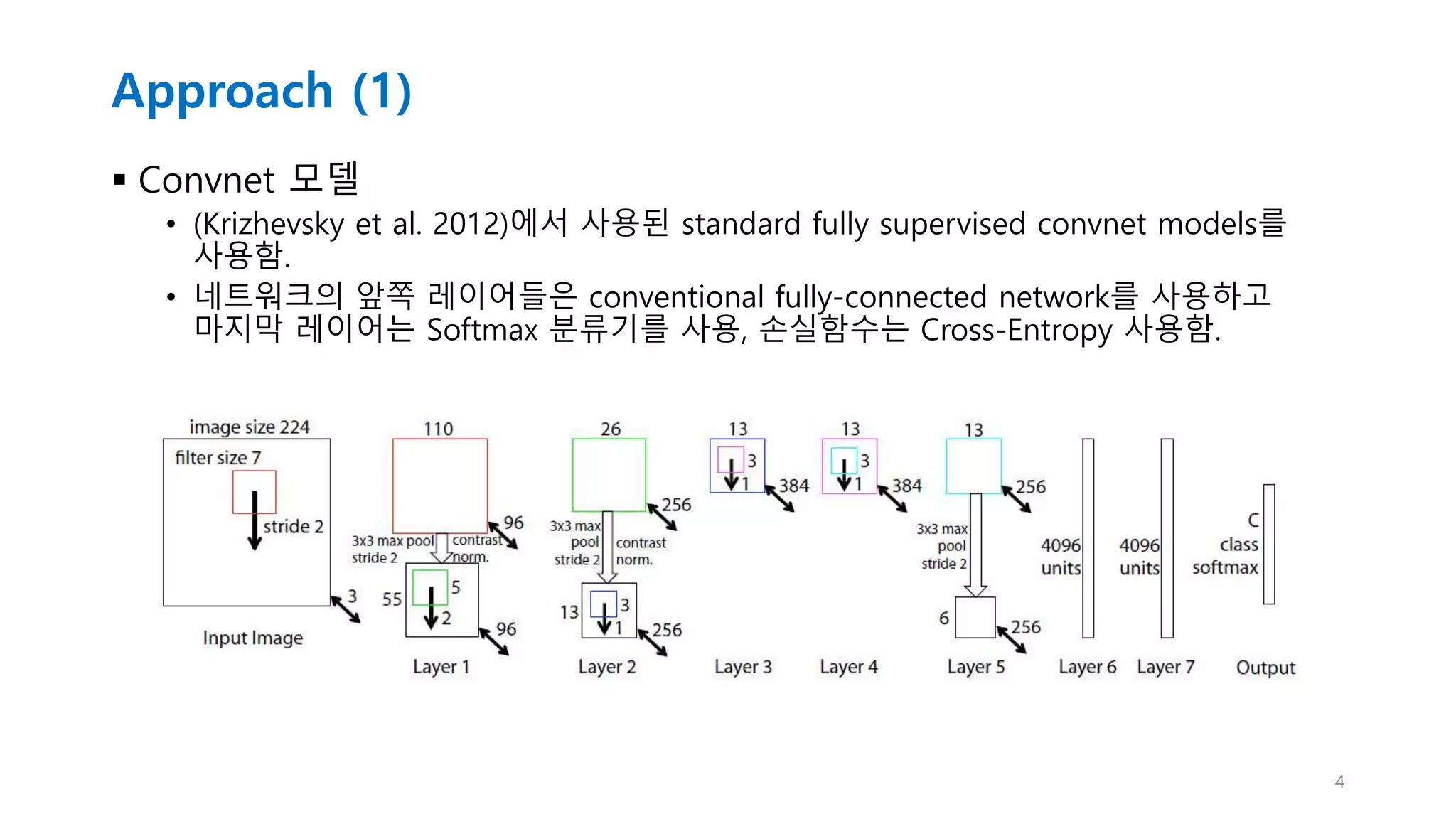
Approach (1)
Convnet모델
• (Krizhevsky et al. 2012)에서 사용된 standard fully supervised convnet models를
사용함.
• 네트워크의 앞쪽 레이어들은 conventional fully-connected network를 사용하고
마지막 레이어는 Softmax 분류기를 사용, 손실함수는 Cross-Entropy 사용함.
4
6.
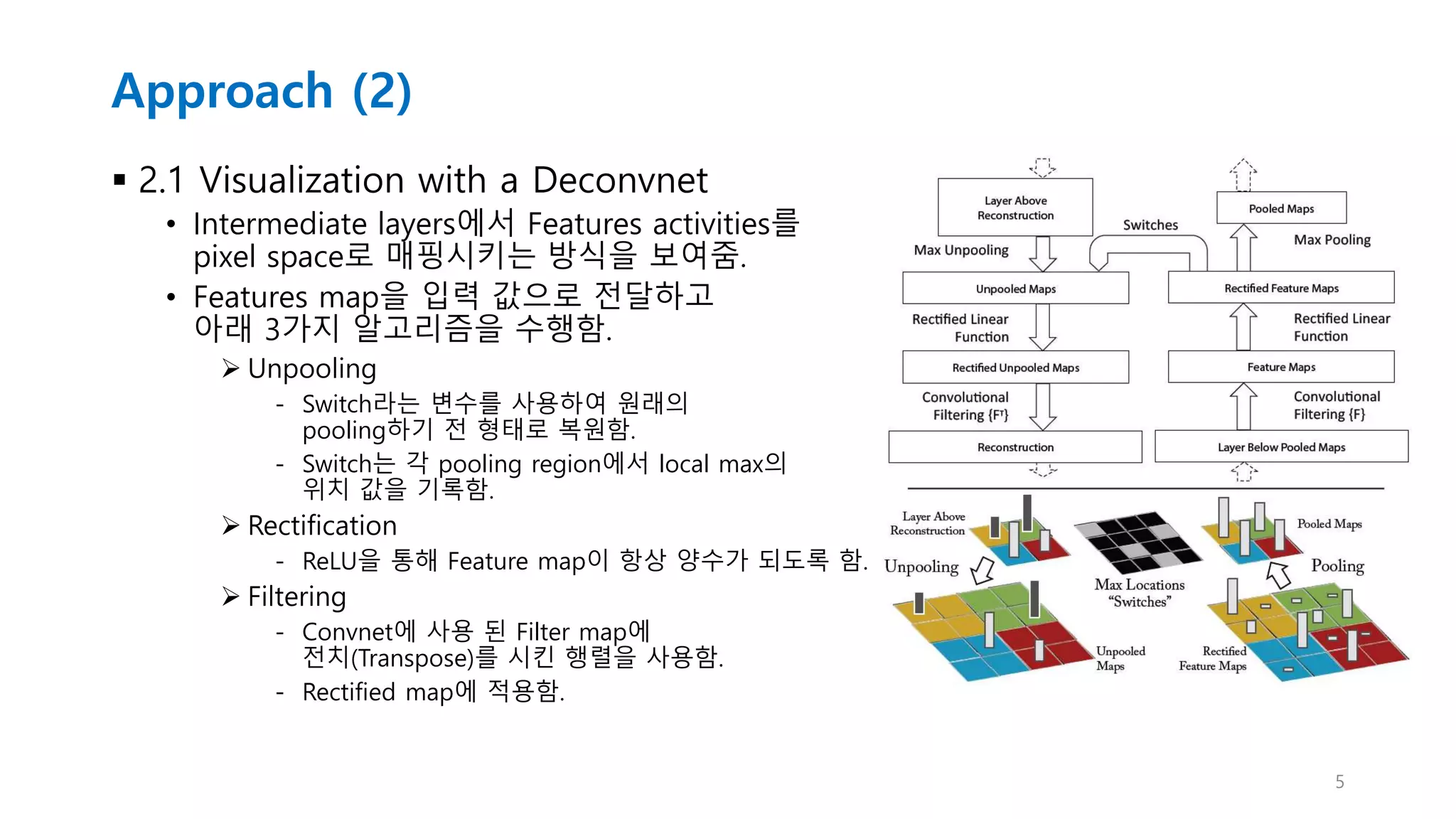
Approach (2)
2.1Visualization with a Deconvnet
• Intermediate layers에서 Features activities를
pixel space로 매핑시키는 방식을 보여줌.
• Features map을 입력 값으로 전달하고
아래 3가지 알고리즘을 수행함.
Unpooling
- Switch라는 변수를 사용하여 원래의
pooling하기 전 형태로 복원함.
- Switch는 각 pooling region에서 local max의
위치 값을 기록함.
Rectification
- ReLU을 통해 Feature map이 항상 양수가 되도록 함.
Filtering
- Convnet에 사용 된 Filter map에
전치(Transpose)를 시킨 행렬을 사용함.
- Rectified map에 적용함.
5
7.
Training Details
(Krizhevskyet al. 2012)와 차이점
• (Krizhevsky et al. 2012)는 3,4,5 레이어에 sparse connections을 사용했지만
여기서 쓰이는 모델은 dense connection임.
• Layer1, 2가 다름. (이후에 설명)
Training
• ImageNet 2012 training set 사용함.
• Preprocessing
256*256 사이즈로 중앙부분을 자르고 모든 픽셀의 평균값을 가지고 뺌.
그런 후 224*224 사이즈로 10장의 이미지를 만들어냄.
• 128 사이즈의 Mini-batch 를 가진 Stochastic gradient descent를 이용하여
parameter를 업데이트함.
• Layer 6,7에서 Dropout을 사용함.
• 모든 가중치는 10^-2로 bias는 0으로 초기화함.
6
8.
Convnet Visualization (1)
Feature Visualization
• 오른쪽 그림은 Training 완료 후의 feature의
모습임. (Visualization 옆에는 해당
image patch를 보여줌)
• 가장 강한 activation 대신에 top 9 activation
을 보여줌.
• Pixel space로 projecting 하는 것은
주어진 feature map을 excite 시키는 다른
구조를 만들어냄.
• Image patch는 visualization보다 변수가 많음.
Visualization은 특정 구조에 초점을 맞춤.
(Ex) Layer5 [1, 2])
• 네트워크에서 각 feature들은 계층적 특성을
지님.
Layer2 : corner, edge/color conjunctions
Layer3 : similar textures
Layer4 : significant variation, more class-specific
Layer5 : entire objects with significant
7
9.
Convnet Visualization (2)
Feature Evolution during Training
• 위 그림은 Feature map중에서 강한 activation을 훈련하는 동안에 진행을
Visualization을 함.
• 낮은 layer에서는 적은 수의 epochs로 학습이 되지만 높은 layer는
40~50개의 상당한 수의 epochs가 필요로 함.
8
10.
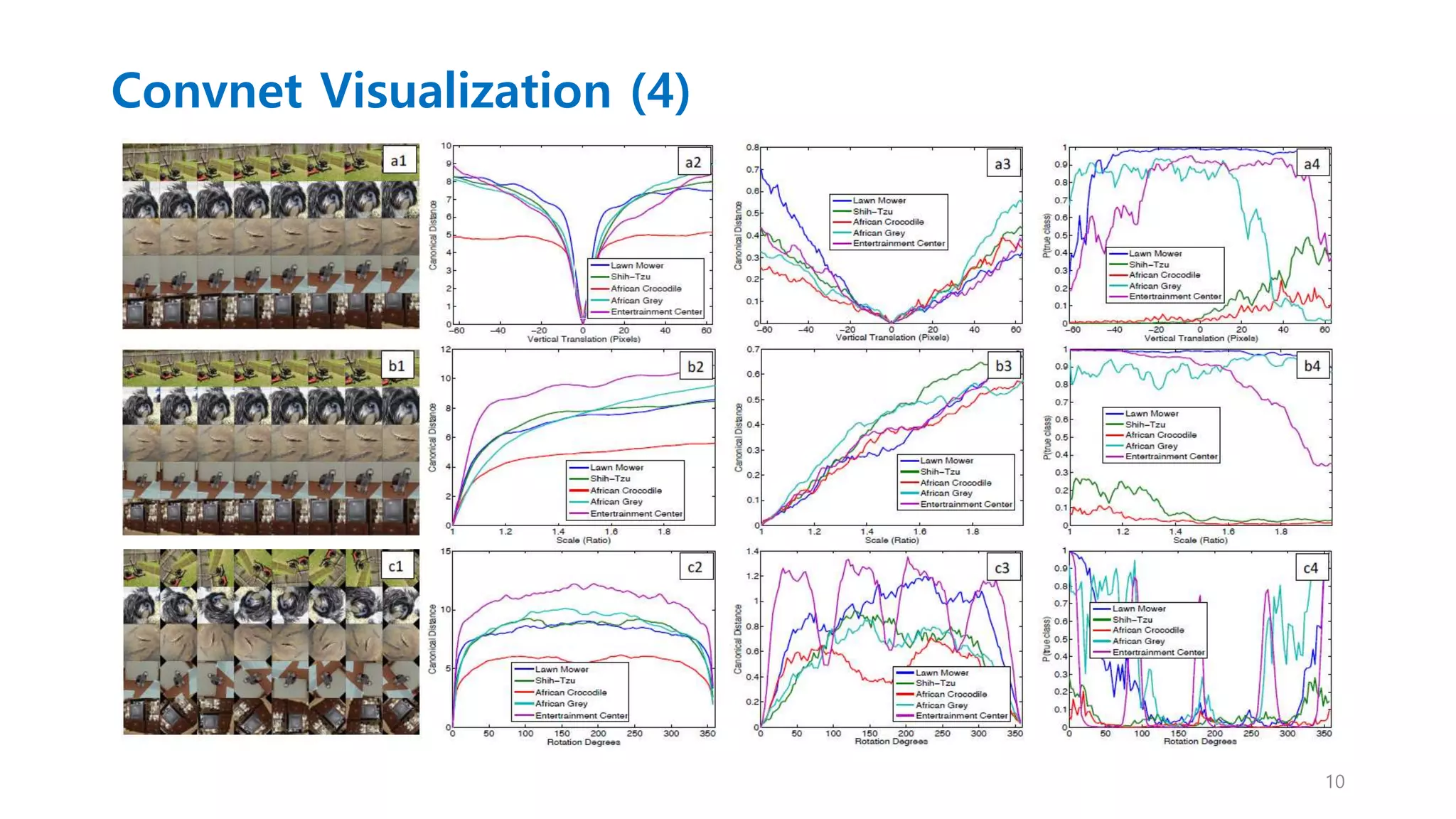
Convnet Visualization (3)
Feature invariance
• Sample Image 5개를 변형(이동, 회전, 확대축소)을 시켜 해당 feature vector와
untransformed feature vector와의 상대적인 변화를 봄.
• 작은 변형에 대해서는 첫 번째 Layer가 큰 영향을 큰 효과를 가지지만
마지막 Layer에 대해서는 영향이 미미함.
• 네트워크 출력은 이동과 스케일에 대해서는 안정적이지만 회전은 그렇지 않음.
(대칭회전 제외)
• 다음 장 그림 변수
A : 이동, B : 스케일, C : 회전
Col1 : 5개의 변형된 이미지
Col2 & 3 : Euclidean distance를 이용한 feature vector 차이.
(2는 Layer 1, 3은 Layer 7)
Col4 : 각 이미지의 True label의 확률
9
Convnet Visualization (5)
Architecture Selection
• Visualization은 좋은 architecture를 선택하는 데 도움을 줌.
• (a)는 feature scale clipping이 없는 1 Layer
(b)와 (d)가 Krizhevsky et al의 1 Layer와 2 Layer
(c)와 (e)가 이 논문에서 바꾼 Layer
• Filter size를 11 * 11 7 * 7 , Stride of convolution 4 2
적용 결과
(b)에서 있던 a mix of extremely high and low frequency information이
(c)에서는 보이지 않음.
(d)에서 aliasing artifact가 보이지만 (e)에서 많이 줄여짐.
게다가 분류기의 성능이 향상됨.
11
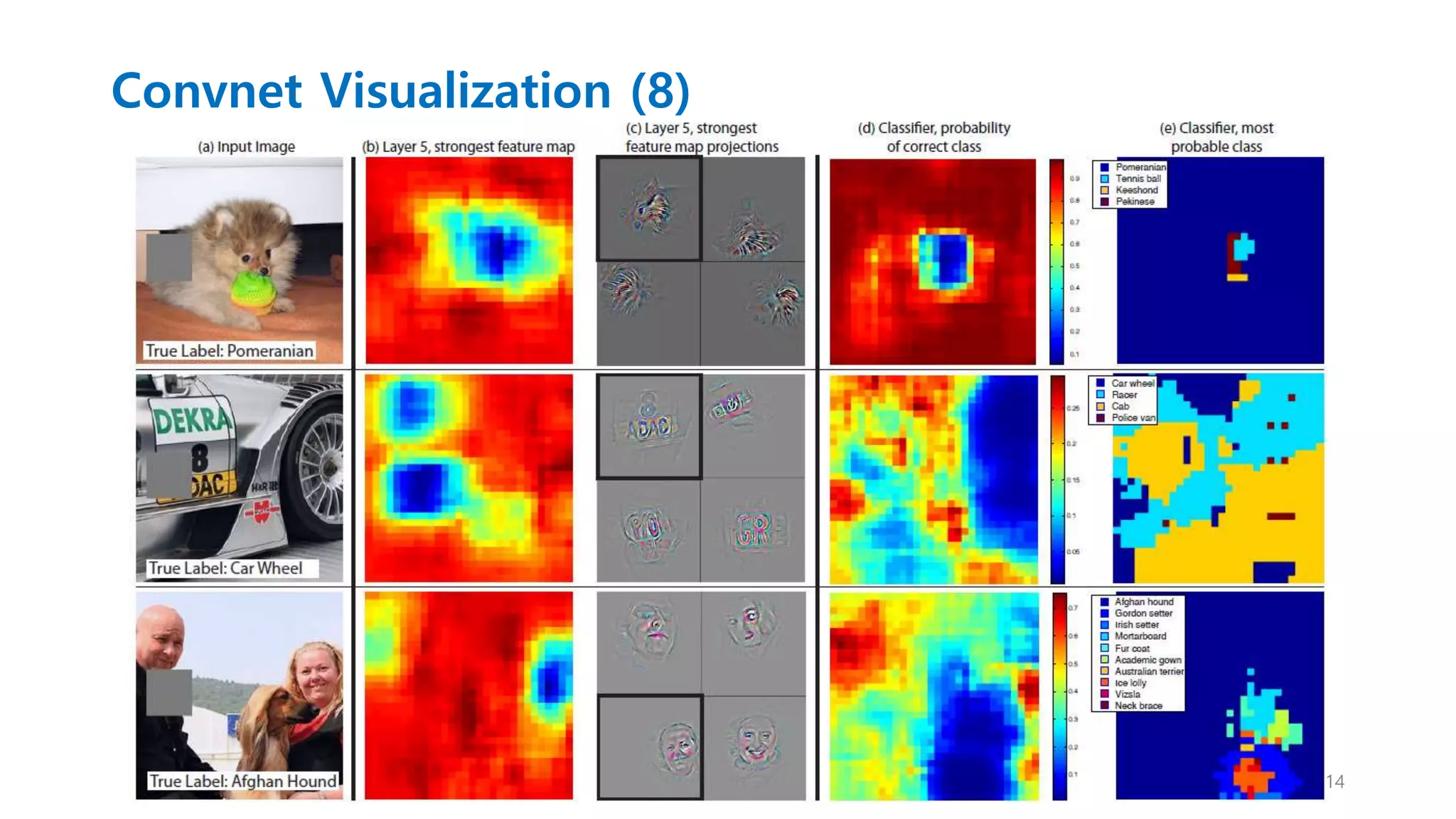
Convnet Visualization (7)
Occlusion Sensitivity
• 이 모델이 정말로 이미지에서 오브젝트의 위치를 확인하는지
또는 주변 환경을 잘 활용하는지를 테스트 해봄.
이미지의 일부분을 가림(Occlusion)으로써 테스트.
• 실험 결과
모델은 씬에서 명확하게 오브젝트를 인지함.
- 오브젝트를 가렸을 때 correct class 확률이 떨어짐.
Visualization은 image structure에 들어 맞는것을 보여주고 또 다른 visualization도
유효하다는 것을 입증함.
13
Convnet Visualization (9)
Correspondence Analysis
• Deep model은 기존 인지 접근 방식들과 다르게 특정한 오브젝트 부분들 사이에
관련성을 만들어내는 명확한 메커니즘이 존재하지 않음.
Deep model이 이것들을 implicitly 하게 계산하는지 찾아봄.
• 실험 방법
5개의 개 이미지를 가지고 각 이미지 마다 왼쪽 눈, 오른쪽 눈, 코, 랜덤 한 위치를
가리고 원본과 가려진 이미지에서 만들어진 각각의 feature vector를 빼줌.
- 𝜖𝑖
𝑙
= 𝑥𝑖
𝑙
− 𝑥𝑖
~𝑙
• i : 이미지 인덱스, l , ~l : Layer l에서의 원본, occlude 된 이미지의 feature map
-
• H : hamming distance, sign() : 양수는 1 음수는 -1 0은 0으로 세팅 하는 함수.
Layer5와 Layer7에서의 feature를 사용함.
• 낮은 값일수록 이미지들 사이에서 더 일관성 있고 더 연관성 있다는 것임.
15
Convnet Visualization (11)
실험 결과
• Layer5에서는 Random과 비교했을 때 오른쪽 눈, 왼쪽 눈, 코의 점수는
상대적으로 낮은 것으로 확인됨.
• 반면에 Layer7에서는 Random과는 별 차이가 없음.
Layer7에서 이런 결과가 나온 이유는 Layer7에서는 개 종을 구별하려고 하는 층이기 때문.
17
19.
5. Experiments (1)
5.1 ImageNet 2012
• Krizhevsky et al., 2012에 아키텍처를
거의 정확하게 구현함 (0.1% 오차).
• 앞서 Visualization을 통해 문제가 있는
부분을 찾아서 보완한 방식을 적용함.
• 여러가지 모델들을 결합하여 최종적으로
14.8% 라는 가장 낮은 에러율을
만들어 냄.(Test Top-5)
18
20.
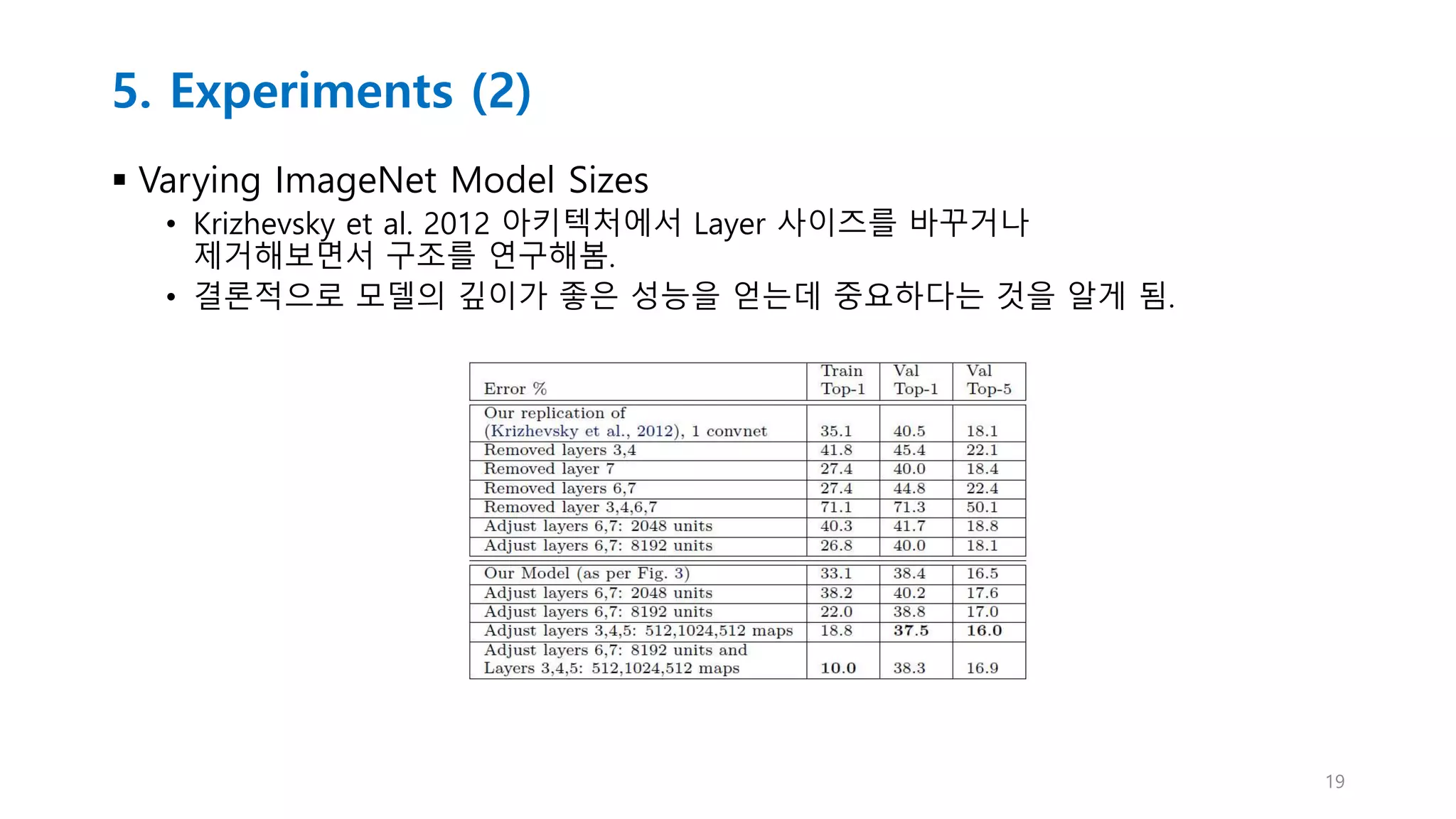
5. Experiments (2)
Varying ImageNet Model Sizes
• Krizhevsky et al. 2012 아키텍처에서 Layer 사이즈를 바꾸거나
제거해보면서 구조를 연구해봄.
• 결론적으로 모델의 깊이가 좋은 성능을 얻는데 중요하다는 것을 알게 됨.
19
21.
5. Experiments (3)
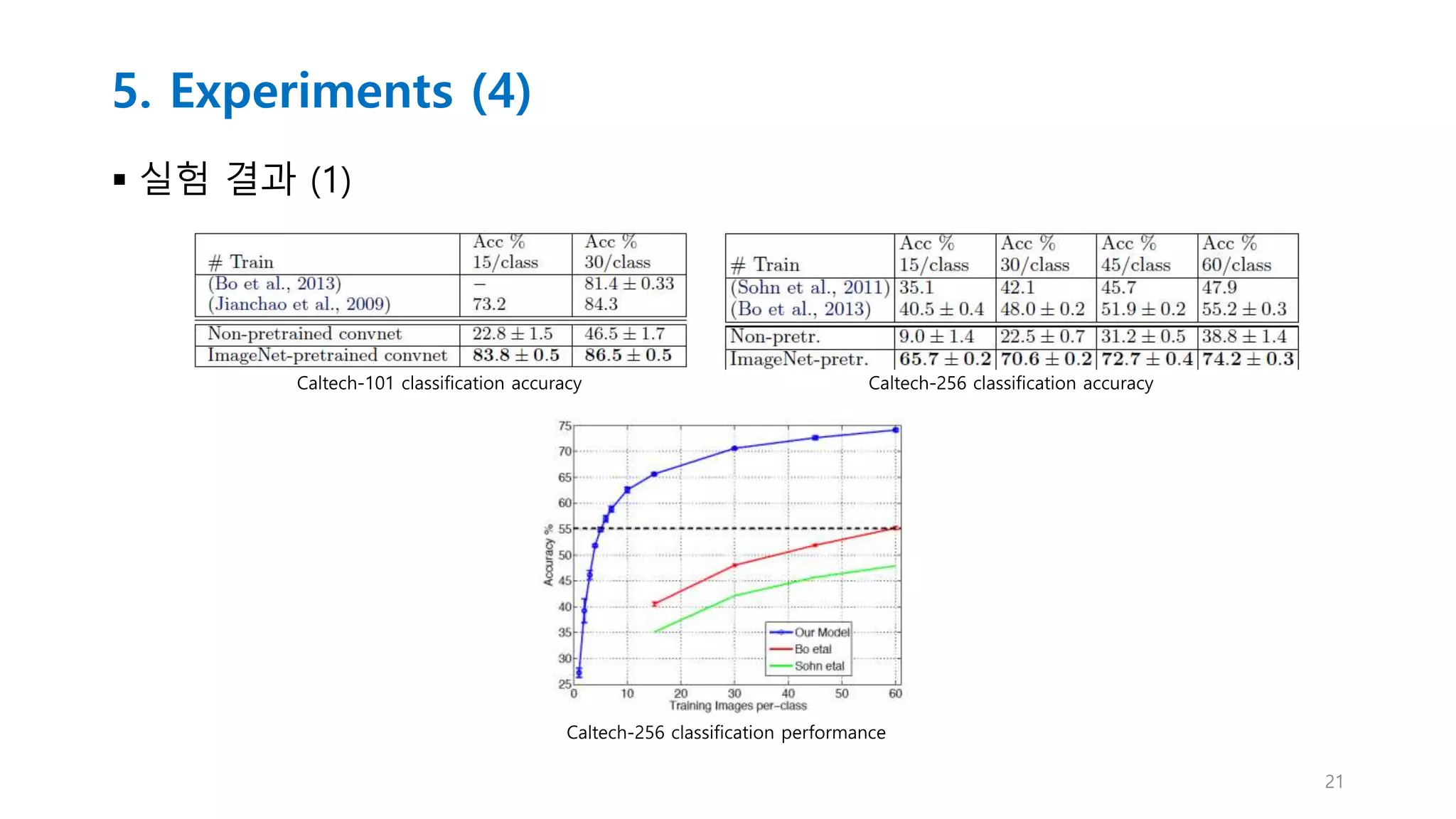
5.2 Feature Generalization
• 다른 데이터 셋에도 일반화가 잘되는지 테스트를 해봄.
데이터 셋
- Caltech-101 (Feifei et al. 2006), Caltech-256 (Griffin et al. 2006)
- PASCAL VOC 2012
• 기존에 만들어진 모델에서 Layer1~7까지 유지시키고 마지막에 softmax classifier만
새로운 데이터 셋으로 다시 훈련 시킴.
• 새로운 training 데이터 셋이 ImageNet이랑 겹치는 이미지가 있을 수 있어서
normalized correlation을 사용하여 그런 이미지들을 제거 시킴.
• Class당 이미지 개수를 늘려가면서 정확도를 측정함.
Caltech-101 : 15 or 30 image per class, 50 image per class
Caltech-256 : 15, 30, 45, 60 image per class
• PASCAL 2012의 경우 이미지의 여러 개의 오브젝트가 존재해서
자신들이 만든 모델과 좀 맞지 않다고 설명함.
20
5. Experiments (5)
실험 결과 (2)
• [A] : (Sande et al. 2012), [B] : (Yan et al. 2012)
• 기존에 좋은 결과를 냈던 모델보다 평균 성능이 3.2% 낮게 나옴.
그러나 5개 class에서 더 높은 성능을 보여줌.
22
24.
5. Experiments (6)
Feature Analysis
• ImageNet-pretrained model이 각 Layer마다 얼마나 feature들을
잘 구별해내는지 실험을 해봄.
• Layer의 수의 변화를 주었고 분류기를 linear SVM이나 softmax를 사용함.
• 데이터 셋은 Caltech-101, Caltech-256 사용함.
• 실험 결과
23
25.
6. Discussion
Convolutionalneural network model에 대해 Visualize하는 방식을 제안함.
Visualize 방식을 통해 모델을 디버깅함으로써 더 나은 구조를 찾는 것을
보여줌.
Occlusion 실험을 통해 분류 훈련 동안 이미지에서 위치 구조에 대해
매우 민감하다는 것을 알게 됨.
모델에서 레이어 제거 실험을 통해 최소한의 깊이가 있는 것이
모델 성능에 좋다는 것을 알게 됨.
우리가 만든 모델이 다른 데이터 셋에도 일반화가 잘 된다는 것을 보여줌.
24





![Convnet Visualization (1)
Feature Visualization
• 오른쪽 그림은 Training 완료 후의 feature의
모습임. (Visualization 옆에는 해당
image patch를 보여줌)
• 가장 강한 activation 대신에 top 9 activation
을 보여줌.
• Pixel space로 projecting 하는 것은
주어진 feature map을 excite 시키는 다른
구조를 만들어냄.
• Image patch는 visualization보다 변수가 많음.
Visualization은 특정 구조에 초점을 맞춤.
(Ex) Layer5 [1, 2])
• 네트워크에서 각 feature들은 계층적 특성을
지님.
Layer2 : corner, edge/color conjunctions
Layer3 : similar textures
Layer4 : significant variation, more class-specific
Layer5 : entire objects with significant
7](https://image.slidesharecdn.com/visualizingandunderstandingconvolutionalnetworks-171116075511/75/Paper-Review-Visualizing-and-understanding-convolutional-networks-8-2048.jpg)










![5. Experiments (5)
실험 결과 (2)
• [A] : (Sande et al. 2012), [B] : (Yan et al. 2012)
• 기존에 좋은 결과를 냈던 모델보다 평균 성능이 3.2% 낮게 나옴.
그러나 5개 class에서 더 높은 성능을 보여줌.
22](https://image.slidesharecdn.com/visualizingandunderstandingconvolutionalnetworks-171116075511/75/Paper-Review-Visualizing-and-understanding-convolutional-networks-23-2048.jpg)




















![[부스트캠프 Tech Talk] 배지연_Structure of Model and Task](https://cdn.slidesharecdn.com/ss_thumbnails/boostcampaitechtechtalkbaejiyeon-211210113740-thumbnail.jpg?width=640&height=640&fit=bounds)



![[데이터 분석 소모임] Convolution Neural Network 김려린](https://cdn.slidesharecdn.com/ss_thumbnails/qjbtpgxtsksukja7q6eq-cnn-gimryeorin-240226120343-804ea096-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Paper] eXplainable ai(xai) in computer vision](https://cdn.slidesharecdn.com/ss_thumbnails/paperexplainableaixaiincomputervision-210411093712-thumbnail.jpg?width=640&height=640&fit=bounds)

![[222]딥러닝을 활용한 이미지 검색 포토요약과 타임라인 최종 20161024](https://cdn.slidesharecdn.com/ss_thumbnails/22220161024-161025034006-thumbnail.jpg?width=640&height=640&fit=bounds)







