딥 러닝 세계에
입문하기위한 분투
2018. 11. 10
Ubuntu Fest in Daejeon
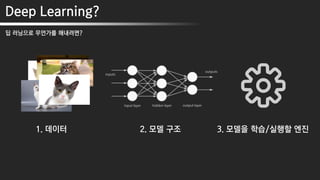
2.
Introduce
발표자 소개
- 임베디드소프트웨어 개발 전공
- 현재: Face Detection 관련 업무 in
- EDM Heavy Listener
- Music Information Retrieval 분야 연구자가 목표!
이수민
Soomin Lee
3.
My story
오늘의 이야기요약
딥 러닝의 세계에 끼어들기 위해 했던 일들!
- 만들어보고 싶은 딥 러닝 모델 생각하기
- 데이터 모으고 정제하기
- 머신 러닝의 기초 공부하기
- 비슷한 문제를 풀었던 논문 읽기
- 적당한 프레임워크를 선택해서 구현하기
- 논문을 넓게 읽어 나가며 시야 넓히기
How to getData?
데이터를 어떻게 얻을 것인가?
1. 직접 데이터를 수집한다
2. 공개된 데이터셋을 이용한다.
11.
How to getData?
데이터를 어떻게 얻을 것인가?
1. 직접 데이터를 수집한다
2. 공개된 데이터셋을 이용한다.
12.
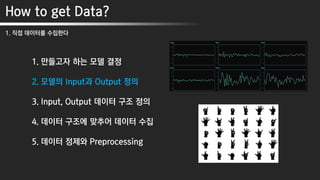
How to getData?
1. 직접 데이터를 수집한다
1. 만들고자 하는 모델 결정
2. 모델의 Input과 Output 정의
3. Input, Output 데이터 구조 정의
4. 데이터 구조에 맞추어 데이터 수집
5. 데이터 정제와 Preprocessing
13.
How to getData?
1. 직접 데이터를 수집한다
1. 만들고자 하는 모델 결정
2. 모델의 Input과 Output 정의
3. Input, Output 데이터 구조 정의
4. 데이터 구조에 맞추어 데이터 수집
5. 데이터 정제와 Preprocessing
14.
How to getData?
1. 직접 데이터를 수집한다
1. 만들고자 하는 모델 결정
2. 모델의 Input과 Output 정의
3. Input, Output 데이터 구조 정의
4. 데이터 구조에 맞추어 데이터 수집
5. 데이터 정제와 Preprocessing
15.
How to getData?
1. 직접 데이터를 수집한다
1. 만들고자 하는 모델 결정
2. 모델의 Input과 Output 정의
3. Input, Output 데이터 구조 정의
4. 데이터 구조에 맞추어 데이터 수집
5. 데이터 정제와 Preprocessing
Input
Output
16.
How to getData?
1. 직접 데이터를 수집한다
1. 만들고자 하는 모델 결정
2. 모델의 Input과 Output 정의
3. Input, Output 데이터 구조 정의
4. 데이터 구조에 맞추어 데이터 수집
5. 데이터 정제와 Preprocessing
17.
How to getData?
1. 직접 데이터를 수집한다
1. 만들고자 하는 모델 결정
2. 모델의 Input과 Output 정의
3. Input, Output 데이터 구조 정의
4. 데이터 구조에 맞추어 데이터 수집
5. 데이터 정제와 Preprocessing
18.
How to getData?
데이터를 어떻게 얻을 것인가?
1. 직접 데이터를 수집한다
2. 공개된 데이터셋을 이용한다.
19.
How to getData?
2. 공개된 데이터셋을 사용한다
STAR Dataset
Image : CIFAR-10, ImageNet, etc…
Face : MS-Celeb, VGGFace, FDDB, WIDER FACE, etc…
NLP : WikiData, Dbpedia, SQuAD, etc…
MIR : Million Song Dataset, FMA, MagnaTagATune, etc…
How to getData?
Kaggle에서 손쉽게 데이터 얻기
Dataset Description
Dataset 구조 Summary
24.
<포켓몬의 스탯 정보를이용해 전설의 포켓몬 예측>
<영화 Metadata를 이용해 영화의 수익 예측>
How to get Data?
Kaggle에서 데이터 분석 연습
예측에 중요한 Feature는 무엇인가?
(Domain에 따른 Feature 선정)
어떤 데이터를 취하고
어떤 데이터를 버려야 하는가?
고차원의 데이터를 어떻게 효율적으로
분석할 수 있는가?
25.
How to getData?
Kaggle에서 모델 구현을 위한 DB 획득
Fashion MNIST <-> 실제 옷 Image 간의 Domain Translation Network 구현
Synthetic Eye image Real Eye image 변환하는 SimGAN 구현
26.
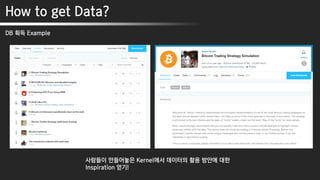
How to getData?
DB 획득 Example
2012년 1월부터 2018년 7월까지의 1분 간격 비트코인 가격 데이터
https://www.kaggle.com/mczielinski/bitcoin-historical-data
27.
How to getData?
DB 획득 Example
데이터셋이 포함하고 있는 내용
- 1분 간격으로 시가, 최고가, 최저가, 종가, 거래량 등이 나열되어 있음.
28.
실제 CSV 데이터의모양과 구조, 수치 분포 대략적 확인
- 필터와 정렬 기능을 사용할 수 있음.
How to get Data?
DB 획득 Example
29.
사람들이 만들어놓은 Kernel에서데이터의 활용 방안에 대한
Inspiration 얻기!
How to get Data?
DB 획득 Example
Which model shouldI use?
무슨 모델을 사용해야 할까?
데이터와 문제 정의에 따라 달라지는 모델 구조
Image Classification : Convolutional Models
Time-series predicton : Recurrent Models (LSTM, etc…)
Image Generation : Generative Models (VAE, GAN, etc…)
Natural Language : Recurrent Models, Attention Mechanism
32.
Which model shouldI use?
무슨 모델을 사용해야 할까?
우리가 해보려는 것
거의 100% 누군가가 이미 해 보았던 것이고
그 누군가는 자신의 삽질기를 예쁘게 정리해서
논문이라는 형태로 세상에 자랑했을 것이다!
33.
How to studyDeep Learning?
논문은 좋은데, 읽으려면 배경 지식은 필수!
Binary Cross Entropy?
Softmax?
Adam Optimizer?
Intersection Over Union?
Precision / Recall?
34.
How to studyDeep Learning?
딥 러닝의 기초 다지기
딥 러닝 튜토리얼 분야 본좌 : Stanford CS231n
다루는 내용 : Neural Networks, Loss function, Optimization,
CNN, RNN, Detection, Visualizing, Generative Models, RL, etc…
35.
How to studyDeep Learning?
딥 러닝의 기초 다지기
Ian Goodfellow가 직강을 해주는 그런 강의!
36.
How to studyDeep Learning?
딥 러닝의 기초 다지기
Google 머신러닝 단기집중과정
37.
머신 러닝의 기초에충실한 커리큘럼
이해를 돕기 위한 상호 작용하는 보조 자료
TensorFlow + Google Colab을 이용한 즉각 실습
How to study Deep Learning?
딥 러닝의 기초 다지기
38.
How to studyDeep Learning?
학습 환경 만들기
NVIDIA GPU가 장착된 개인 컴퓨터 / 서버 : 최고!
기초적인 머신 러닝 실습은 CPU만으로도 충분히 가능.
Google Colab 등 온라인 시스템 이용!
https://colab.research.google.com/
39.
How to studyDeep Learning?
학습 환경 만들기 : Google Colab
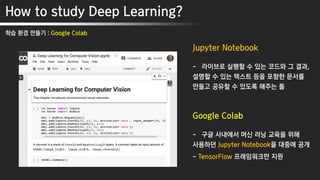
Jupyter Notebook
- 라이브로 실행할 수 있는 코드와 그 결과,
설명할 수 있는 텍스트 등을 포함한 문서를
만들고 공유할 수 있도록 해주는 툴
40.
How to studyDeep Learning?
학습 환경 만들기 : Google Colab
Jupyter Notebook
- 라이브로 실행할 수 있는 코드와 그 결과,
설명할 수 있는 텍스트 등을 포함한 문서를
만들고 공유할 수 있도록 해주는 툴
Google Colab
- 구글 사내에서 머신 러닝 교육을 위해
사용하던 Jupyter Notebook을 대중에 공개
- TensorFlow 프레임워크만 지원
41.
How to studyDeep Learning?
학습 환경 만들기 : Google Colab
Google Colab의 장점
1. 온라인으로 공유하여 여러 명이 동시에 작업 가능
2. Google Drive 연동으로 Custom Dataset 업로드와 사용이 용이
3. 높은 확률로 Tesla K80 GPU를 이용한 실습 가능
4. 심지어 얼마 전부터 TPU도 체험 가능!
42.
How to studyDeep Learning?
학습 환경 만들기 : Google Colab
43.
코드 작성 후바로 실행 가능!
How to study Deep Learning?
학습 환경 만들기 : Google Colab
44.
Which model shouldI use?
이제 모델을 만들어 보자!
기초를 다졌으니, 이제 모델을 만들어 보자!
Image Classification : Convolutional Models
Time-series predicton : Recurrent Models (LSTM, etc…)
Image Generation : Generative Models (VAE, GAN, etc…)
Natural Language : Recurrent Models, Attention Mechanism
Which model shouldI use?
논문 리딩 : Top-Down Approach
CycleGAN
GAN
DCGAN ResNet
pix2pix CGAN
PatchGAN
GAN 구조의 기본이 되는 모델
GAN을 발전시켜 실용화한 모델
GAN의 실용성을 발전시킨 모델
CycleGAN의 기반이 된
기존 모델
복잡하고 무거운 CNN을
가능케 하는 모델
CGAN을 특정 Approach에
응용한 모델
트레이닝 방식에 변화를 준 방법
50.
Which model shouldI use?
논문 리딩 : Top-Down Approach
Object Detection Paper List
51.
Which model shouldI use?
논문 리딩 : Top-Down Approach
Faster R-CNN
Fast R-CNN
R-CNN
YOLO v1
YOLO v2
SSD
R-FCN
OHEM
RetinaNet
Mask R-CNN
52.
Which model shouldI use?
논문이 이해되지 않으면 코드를 참고하자!
논문의 내용(수식, 테크닉)이
이해되지 않는 경우,
코드를 보는 것이 이해에
효과적일 경우가 많음!
How to makemy own model?
왜 프레임워크를 사용하는가?
딥 러닝 프레임워크를 사용하는 이유
1. 계산 그래프(Computational Graph)를 쉽게 설계할 수 있다.
2. 계산 그래프에서 Loss와 Gradient를 쉽게 구할 수 있다.
3. Gradient를 이용한 모델의 업데이트 또한 자동으로 수행해준다.
4. GPU를 활용하기 쉬운 환경이 제공된다.
56.
How to makemy own model?
어떤 프레임워크를 사용할 것인가?
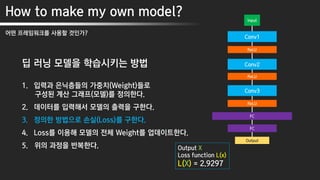
딥 러닝 모델을 학습시키는 방법
1. 입력과 은닉층들의 가중치(Weight)들로
구성된 계산 그래프(모델)를 정의한다.
2. 데이터를 입력해서 모델의 출력을 구한다.
3. 정의한 방법으로 손실(Loss)를 구한다.
4. Loss를 이용해 모델의 전체 Weight를 업데이트한다.
5. 위의 과정을 반복한다.
57.
How to makemy own model?
어떤 프레임워크를 사용할 것인가?
딥 러닝 모델을 학습시키는 방법
1. 입력과 은닉층들의 가중치(Weight)들로
구성된 계산 그래프(모델)를 정의한다.
2. 데이터를 입력해서 모델의 출력을 구한다.
3. 정의한 방법으로 손실(Loss)를 구한다.
4. Loss를 이용해 모델의 전체 Weight를 업데이트한다.
5. 위의 과정을 반복한다.
Input
Conv1
ReLU
FC
Output
Conv2
ReLU
Conv3
ReLU
FC
58.
How to makemy own model?
어떤 프레임워크를 사용할 것인가?
딥 러닝 모델을 학습시키는 방법
1. 입력과 은닉층들의 가중치(Weight)들로
구성된 계산 그래프(모델)를 정의한다.
2. 데이터를 입력해서 모델의 출력을 구한다.
3. 정의한 방법으로 손실(Loss)를 구한다.
4. Loss를 이용해 모델의 전체 Weight를 업데이트한다.
5. 위의 과정을 반복한다.
Input
Conv1
ReLU
FC
Output
Conv2
ReLU
Conv3
ReLU
FC
Output : X
59.
How to makemy own model?
어떤 프레임워크를 사용할 것인가?
딥 러닝 모델을 학습시키는 방법
1. 입력과 은닉층들의 가중치(Weight)들로
구성된 계산 그래프(모델)를 정의한다.
2. 데이터를 입력해서 모델의 출력을 구한다.
3. 정의한 방법으로 손실(Loss)를 구한다.
4. Loss를 이용해 모델의 전체 Weight를 업데이트한다.
5. 위의 과정을 반복한다.
Input
Conv1
ReLU
FC
Output
Conv2
ReLU
Conv3
ReLU
FC
Output X
Loss function L(x)
L(X) = 2.9297
60.
How to makemy own model?
어떤 프레임워크를 사용할 것인가?
딥 러닝 모델을 학습시키는 방법
1. 입력과 은닉층들의 가중치(Weight)들로
구성된 계산 그래프(모델)를 정의한다.
2. 데이터를 입력해서 모델의 출력을 구한다.
3. 정의한 방법으로 손실(Loss)를 구한다.
4. Loss를 이용해 모델의 전체 Weight를 업데이트한다.
5. 위의 과정을 반복한다.
Input
Conv1
ReLU
FC
Output
Conv2
ReLU
Conv3
ReLU
FC
L(X) = 2.9297
61.
How to makemy own model?
Static vs Dynamic Graph Input
Conv1
ReLU
FC
Output
Conv2
ReLU
Conv3
ReLU
FC
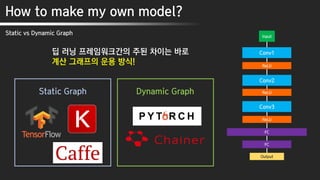
딥 러닝 프레임워크간의 주된 차이는 바로
계산 그래프의 운용 방식!
Static Graph Dynamic Graph
62.
How to makemy own model?
Static Graph : TensorFlow
(Source : CS231n)
63.
How to makemy own model?
Static Graph : TensorFlow
(Source : CS231n)
계산 그래프 정의
64.
How to makemy own model?
Static Graph : TensorFlow
(Source : CS231n)
계산 그래프 정의
계산 그래프 실행
65.
How to makemy own model?
Static Graph : TensorFlow
(Source : CS231n)
처음 실행이 시작될 때 계산 그래프가 고정!
66.
How to makemy own model?
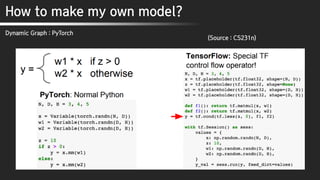
Dynamic Graph : PyTorch
(Source : CS231n)
67.
How to makemy own model?
Dynamic Graph : PyTorch
(Source : CS231n)
Data, Weight 정의
68.
How to makemy own model?
Dynamic Graph : PyTorch
(Source : CS231n)
Data, Weight 정의
계산 그래프 생성
69.
How to makemy own model?
Dynamic Graph : PyTorch
(Source : CS231n)
매 Iteration마다 계산 그래프를 다시 생성!
70.
How to makemy own model?
Dynamic Graph : PyTorch
(Source : CS231n)
How to makemy own model?
그래서 무슨 프레임워크를 써야 좋은가?
각 프레임워크만의 장단점이 존재!
73.
How to makemy own model?
Framework : TensorFlow
TensorFlow
- 구글에서 개발하여 밀고 있는 프레임워크
- Python, C++, JAVA, JavaScript API 지원
- TensorFlow Serving 등 제품화를 위한 지원
- 거대한 사용자 커뮤니티, 활발한 Open Source 활동
- Session 등 개념 이해 필요
- Define-and-Run 모델 : 런타임에 계산 그래프를 변경할 수 없음
- Torch 등에 비해 속도가 느림
74.
학습 시각화 툴TensorBoard 제공
How to make my own model?
Framework : TensorFlow
75.
How to makemy own model?
Framework : Keras
Keras
- 여러 딥 러닝 프레임워크들에 대한 고수준 추상화가 목표
- Caffe, Torch, TensorFlow 등 다양한 프레임워크의 모델 사용 가능
- 직관적이고 접근하기 쉬운 코드 구조
- 기반 라이브러리 단에서 문제가 발생할 경우 Debugging이 어려움
- 비교적 작은 사용자 커뮤니티
76.
How to makemy own model?
Framework : PyTorch
PyTorch
- 깔끔한 코드 구조
- Dynamic Computational Graph
- 설계와 동시에 실행/검증이 가능한 대화형 개발 구조
- 사용자 커뮤니티가 큰 편에 속함
- 큰 프로젝트와 상용화를 위한 복잡한 모델 개발에는 비효율적
77.
How to makemy own model?
Framework : Caffe
Caffe
- 코드 작성 없이 모델의 작성 / 트레이닝 가능
- Python / OpenCV 인터페이스가 편리함
- 학습했던 네트워크의 Fine Tuning 등의 작업이 편리함
- 유연하지 못한 프레임워크 :
Caffe에 없는 새로운 Layer를 만들어 학습시키려면
Caffe의 소스 코드를 수정하여 다시 빌드해야 함.
78.
How to makemy own model?
Framework : Chainer
Chainer
- Dynamic Computational Graph
- 속도가 다른 프레임워크들에 비해 빠름
- 사용자 커뮤니티가 많이 작은 편
- 참고 자료가 부족함






















































































![[222]딥러닝을 활용한 이미지 검색 포토요약과 타임라인 최종 20161024](https://cdn.slidesharecdn.com/ss_thumbnails/22220161024-161025034006-thumbnail.jpg?width=640&height=640&fit=bounds)


![[221] 딥러닝을 이용한 지역 컨텍스트 검색 김진호](https://cdn.slidesharecdn.com/ss_thumbnails/221-161025004534-thumbnail.jpg?width=640&height=640&fit=bounds)

























![[3장] 딥러닝을 위한 환경 구축하기 | 수학 통계를 몰라도 이해할 수 있는 쉬운 딥러닝 | 반병현](https://cdn.slidesharecdn.com/ss_thumbnails/3-220318054202-thumbnail.jpg?width=640&height=640&fit=bounds)




























