Downloaded 206 times








































































































































































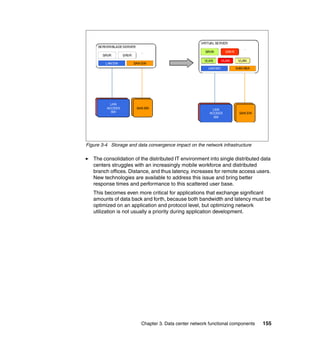






























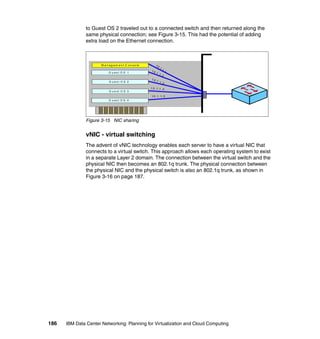
























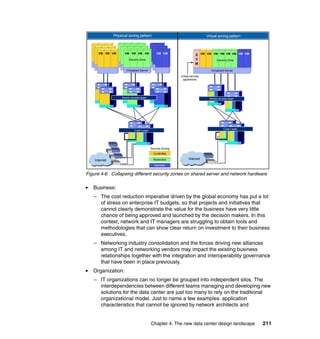


































This document provides an overview of IBM's Data Center Networking: Planning for Virtualization and Cloud Computing. It discusses the drivers for change in the data center that are enabling more dynamic infrastructures through virtualization and cloud computing. These include reducing costs, improving service delivery, and managing risks. The document then describes the various server, storage, software, and management components available from IBM that can help organizations build virtualized and cloud-based data center networks, including virtualization technologies for System z, Power Systems, System x, and BladeCenter servers as well as storage virtualization, virtual infrastructure management tools, and more.






































































































