Download to read offline




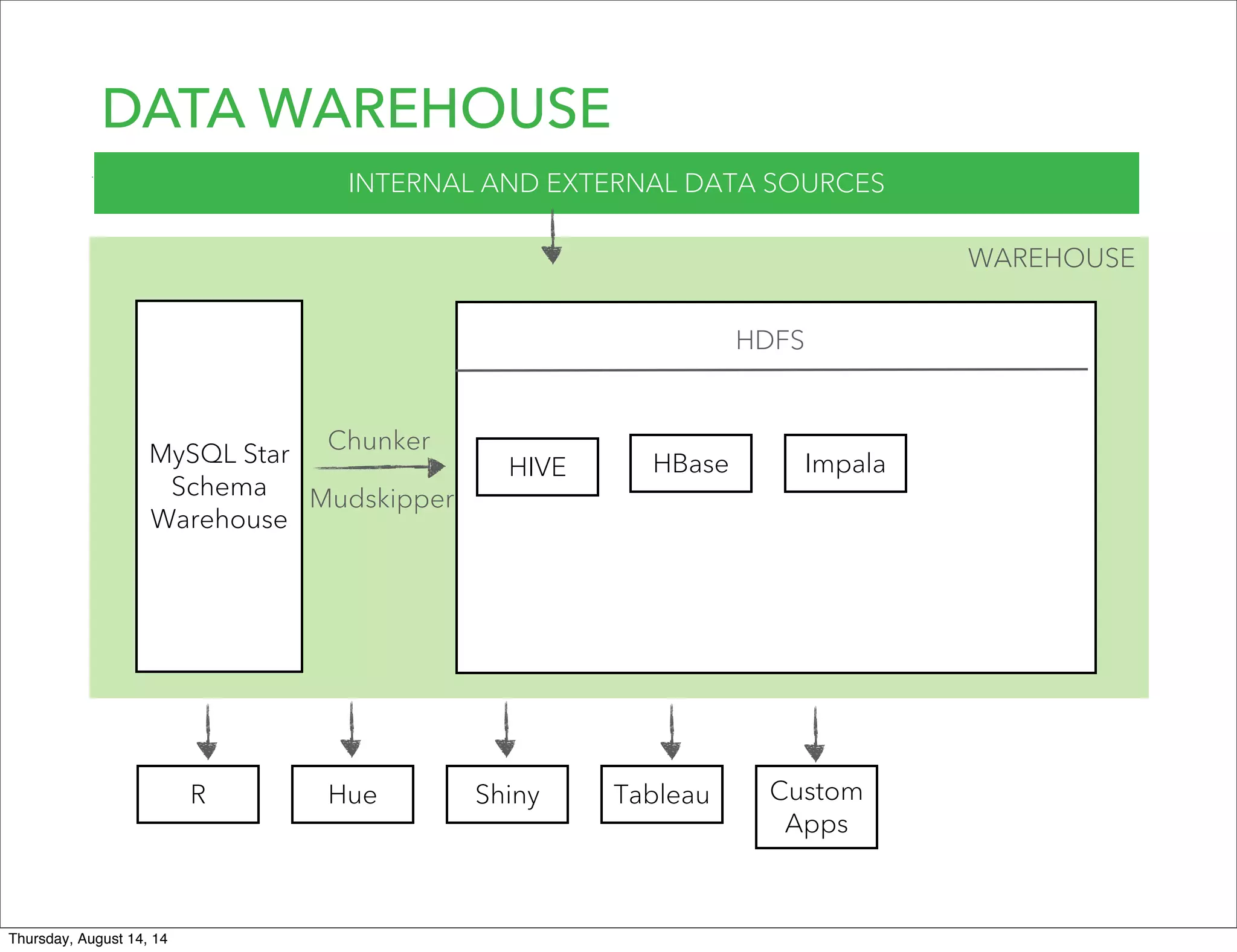

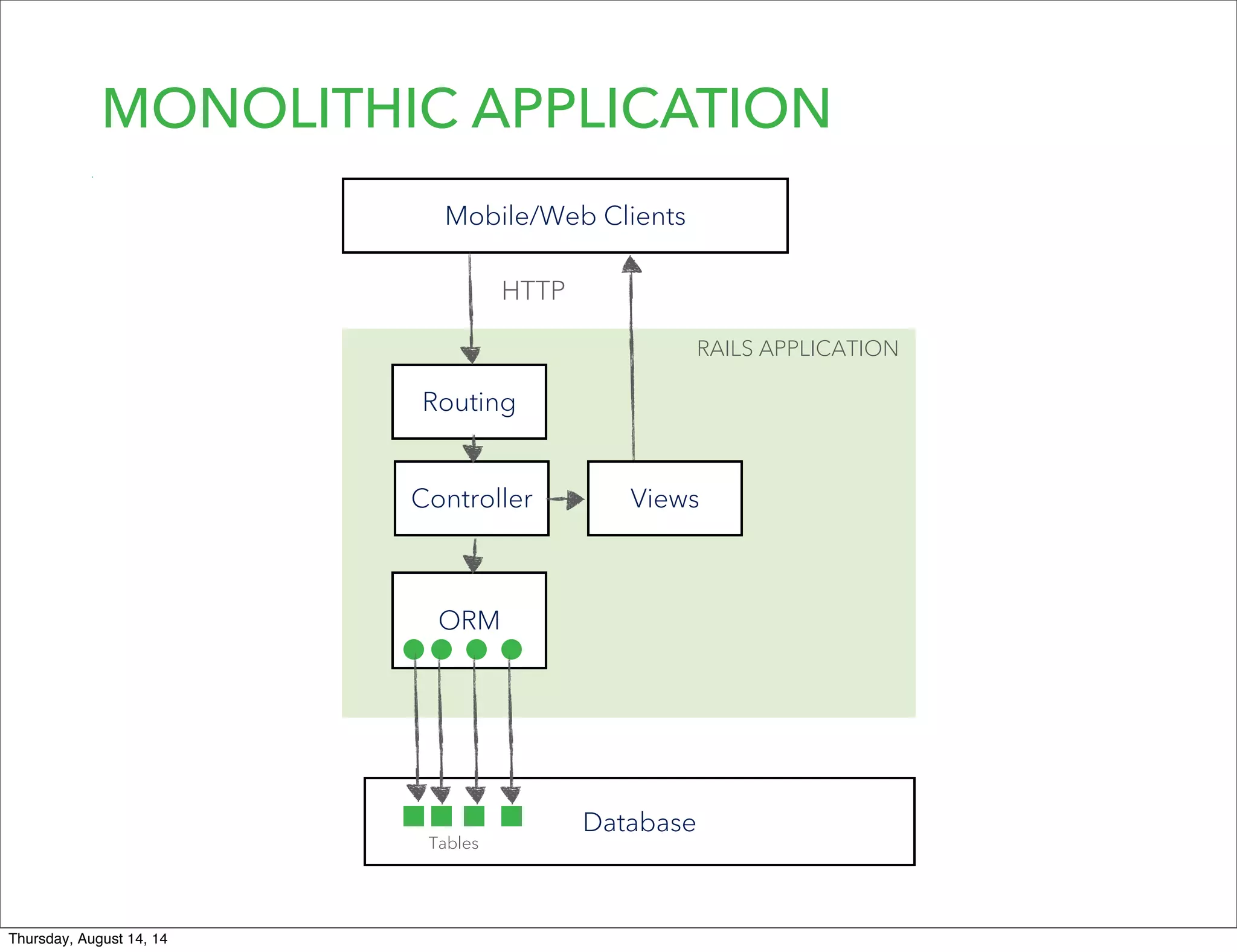
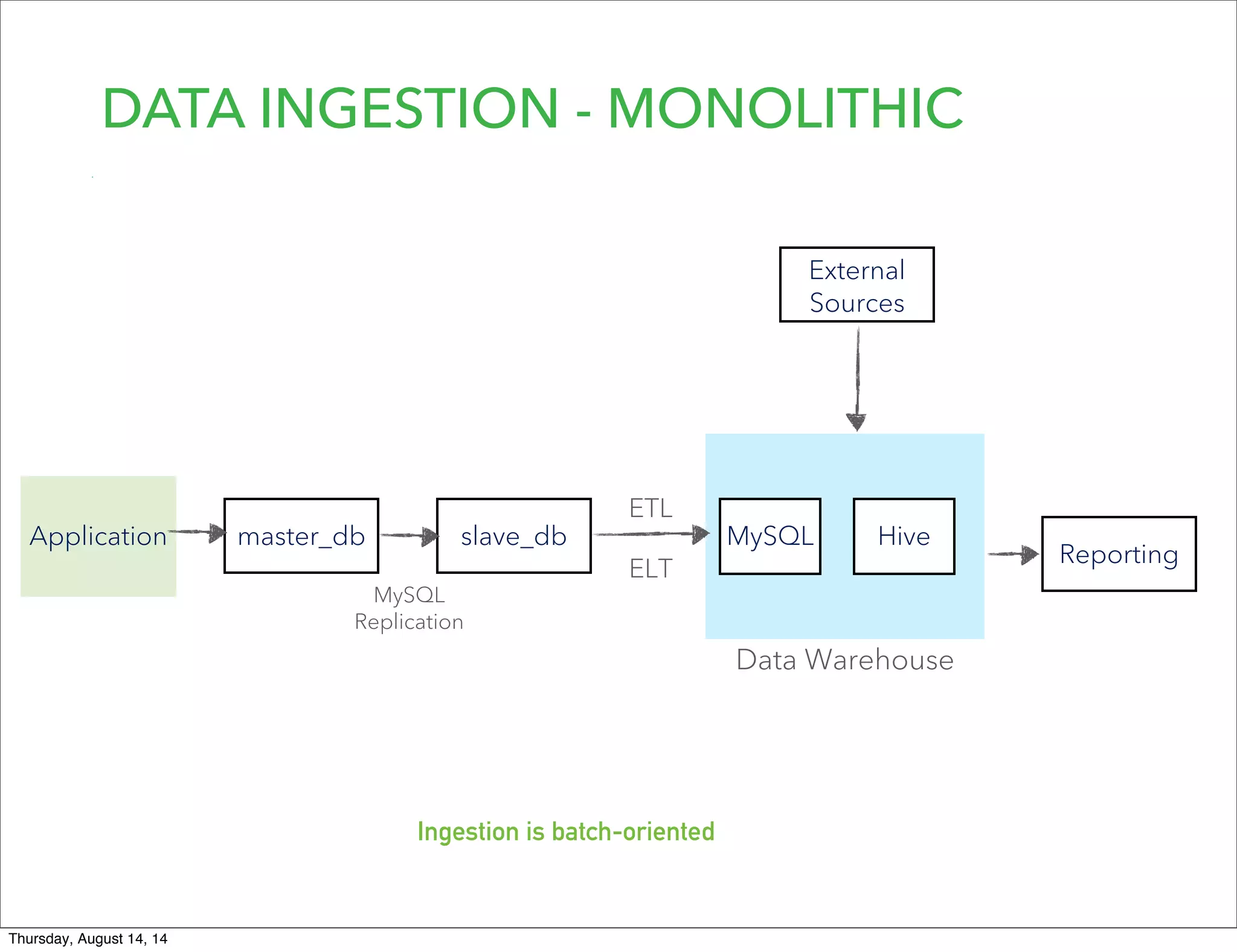

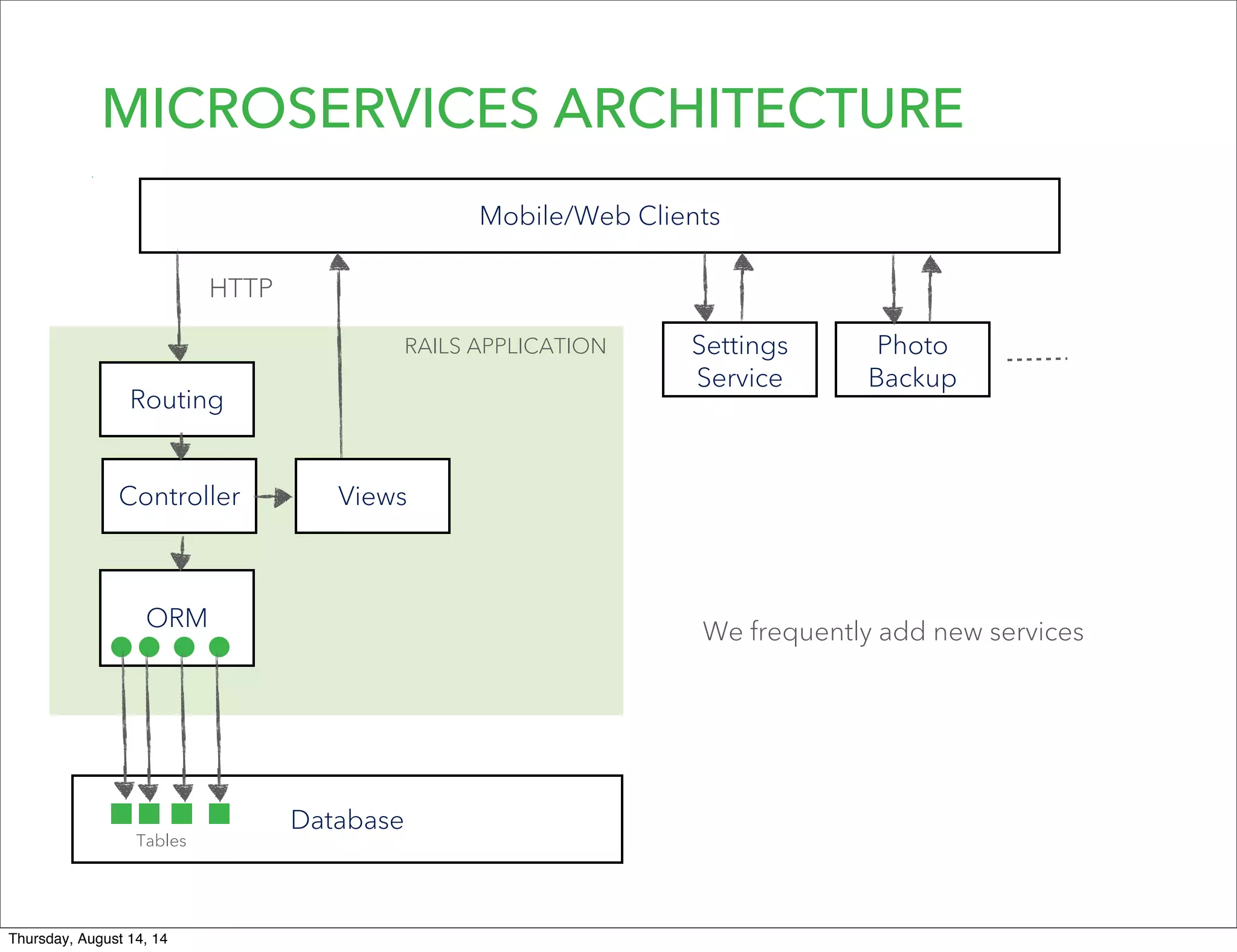
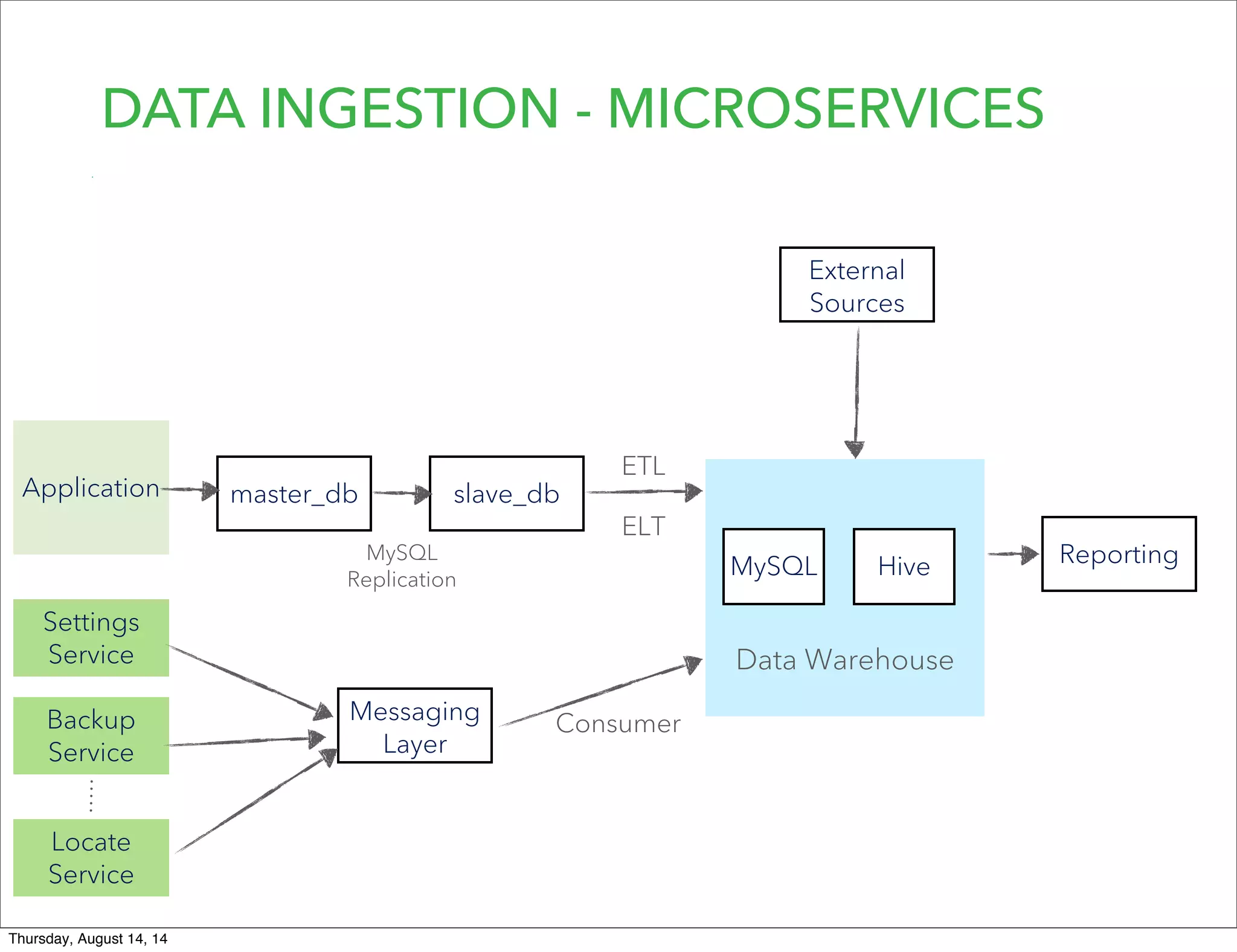


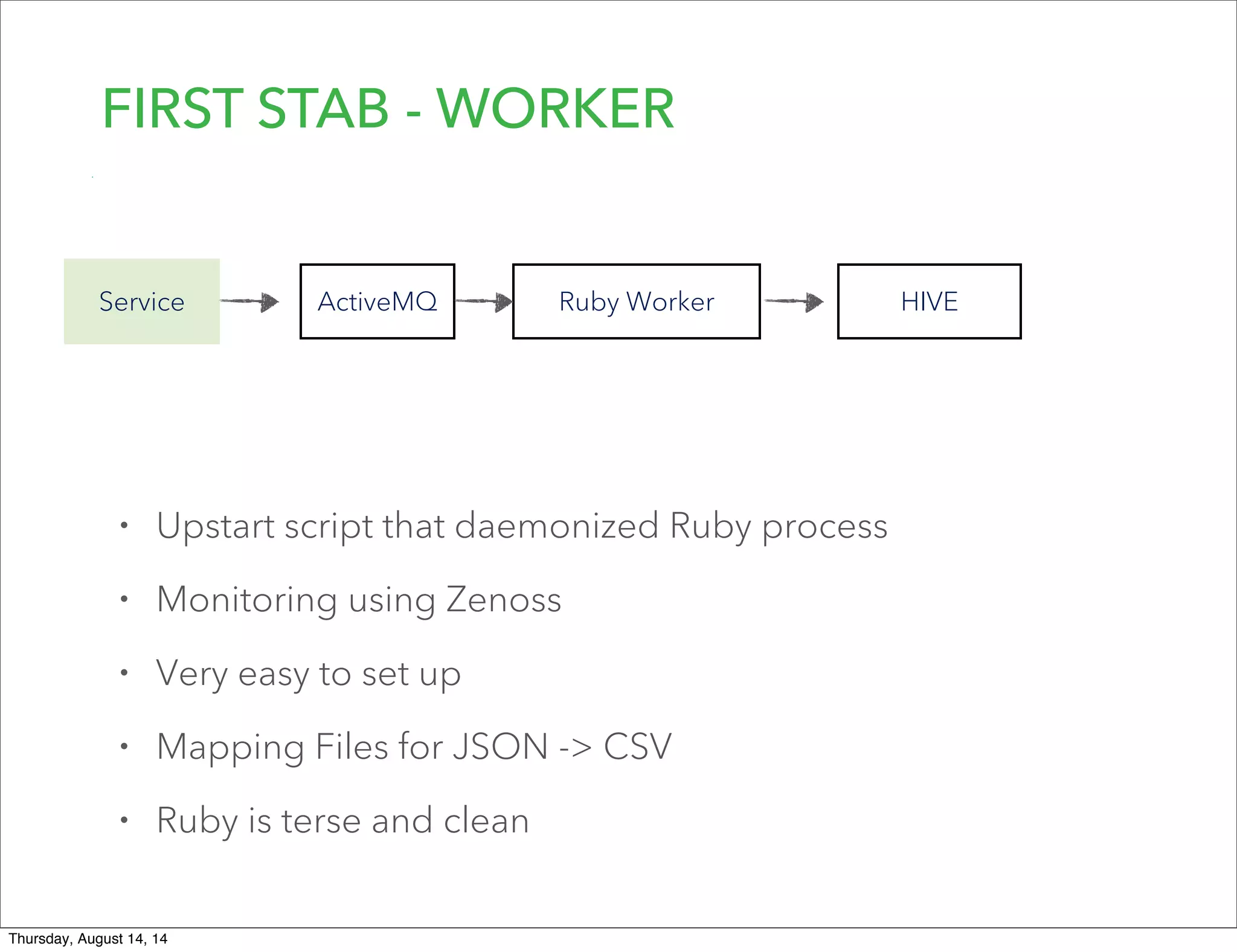

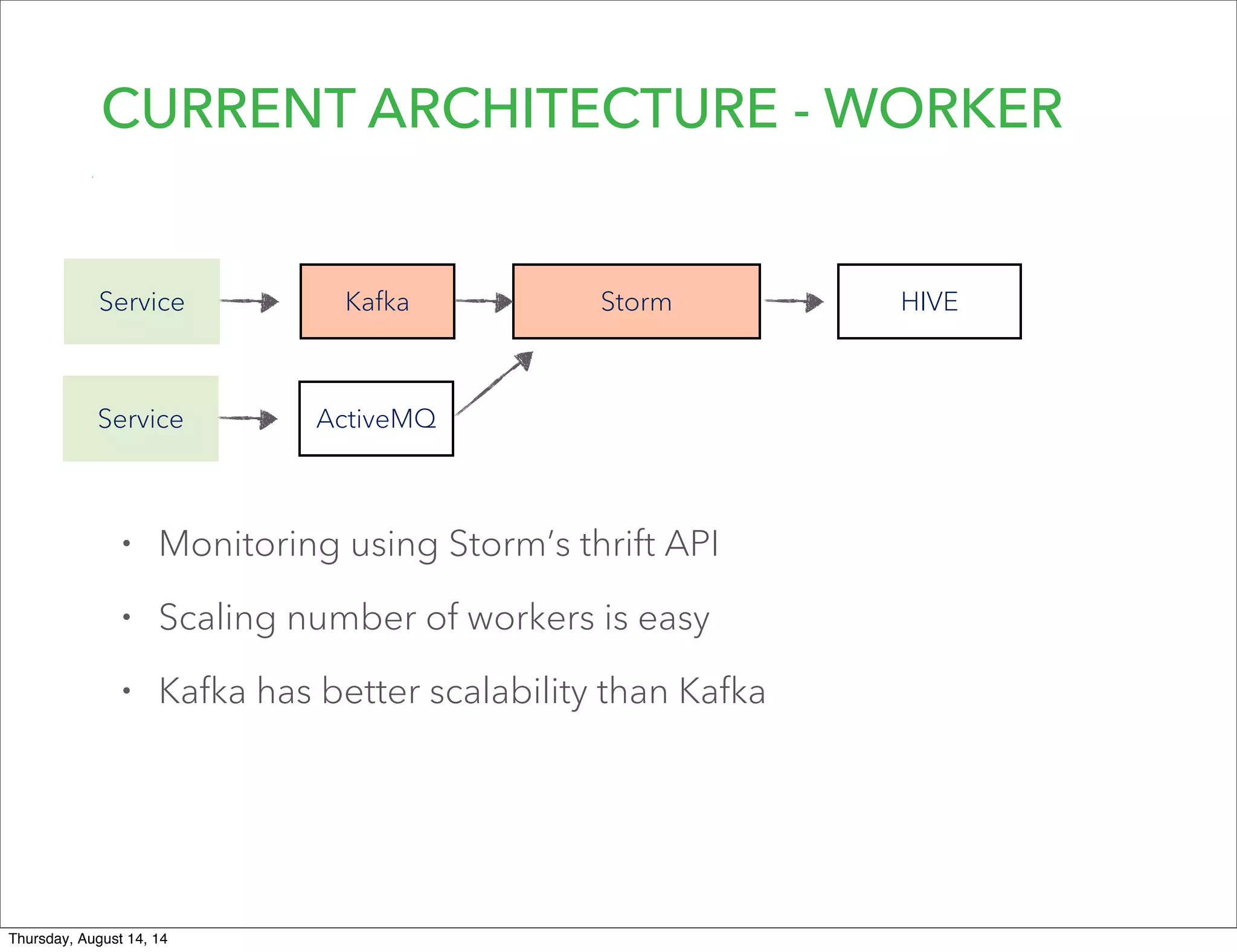
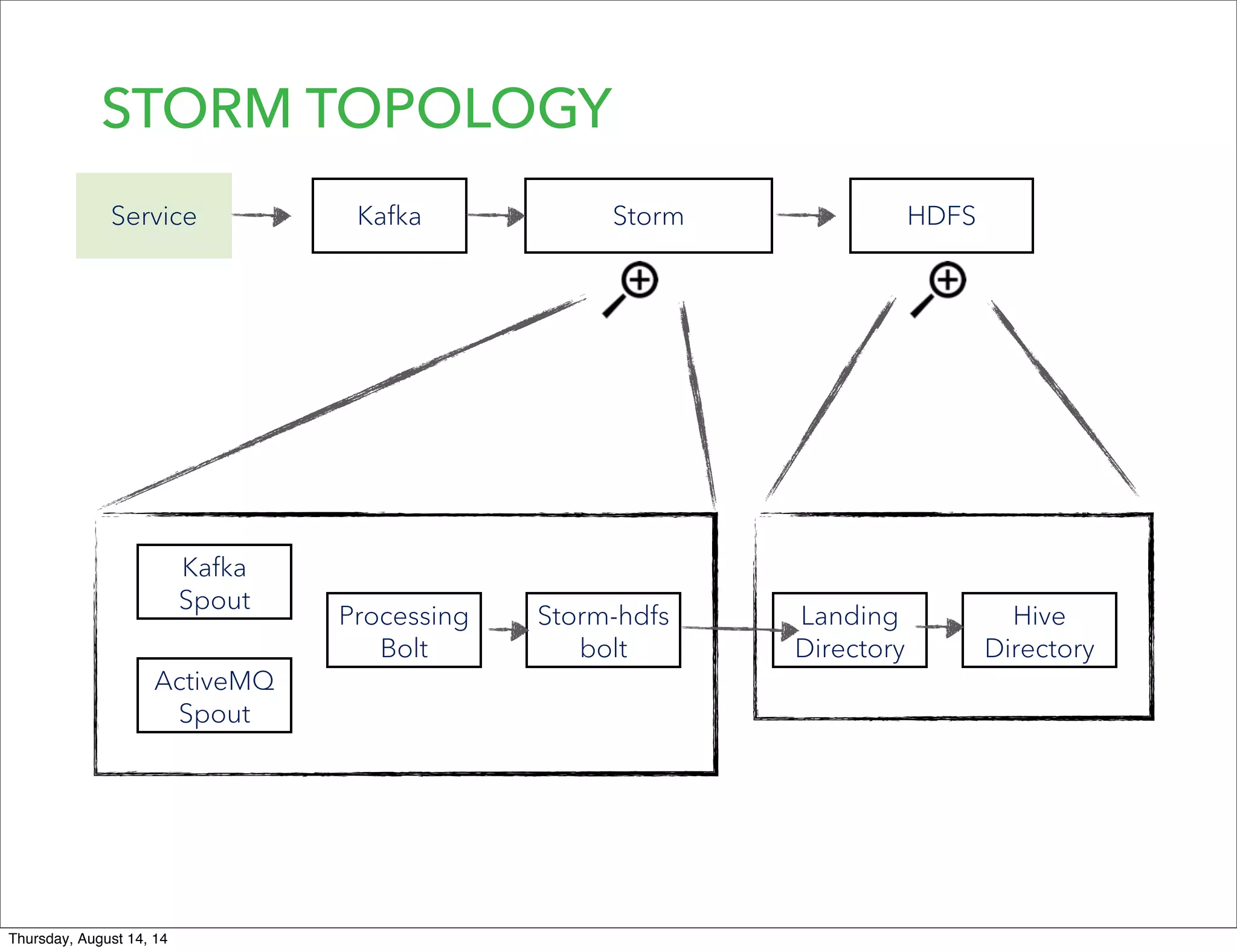


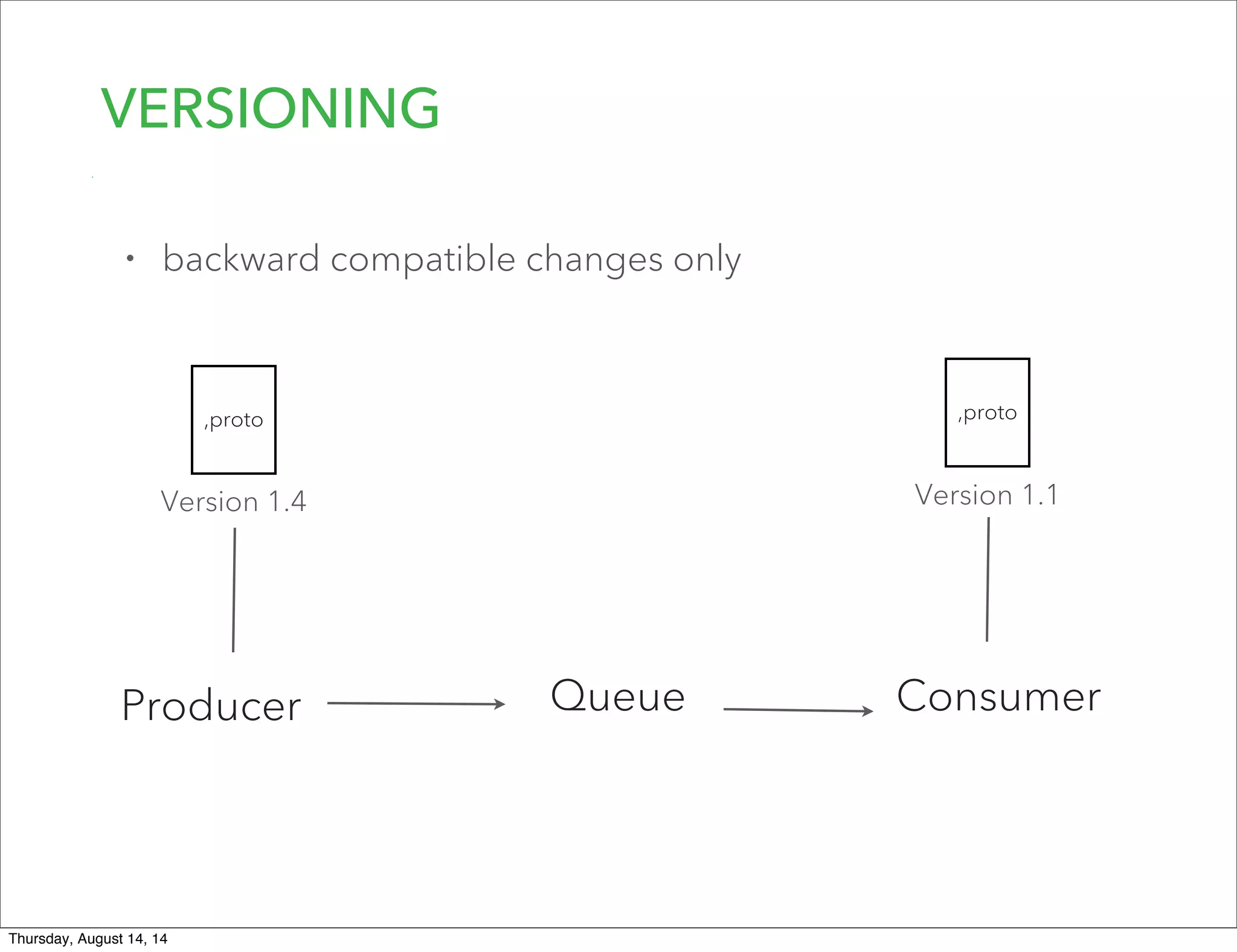
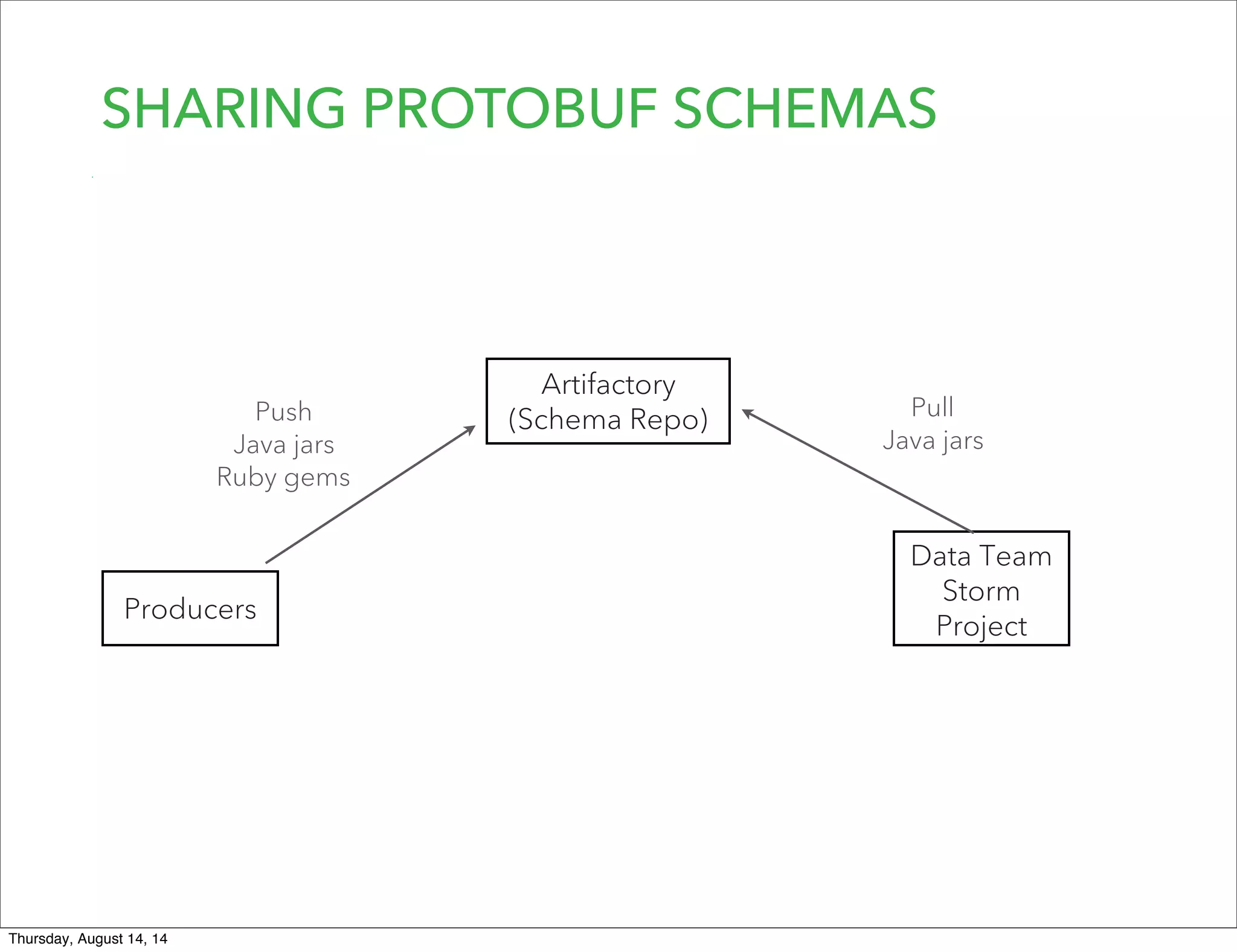


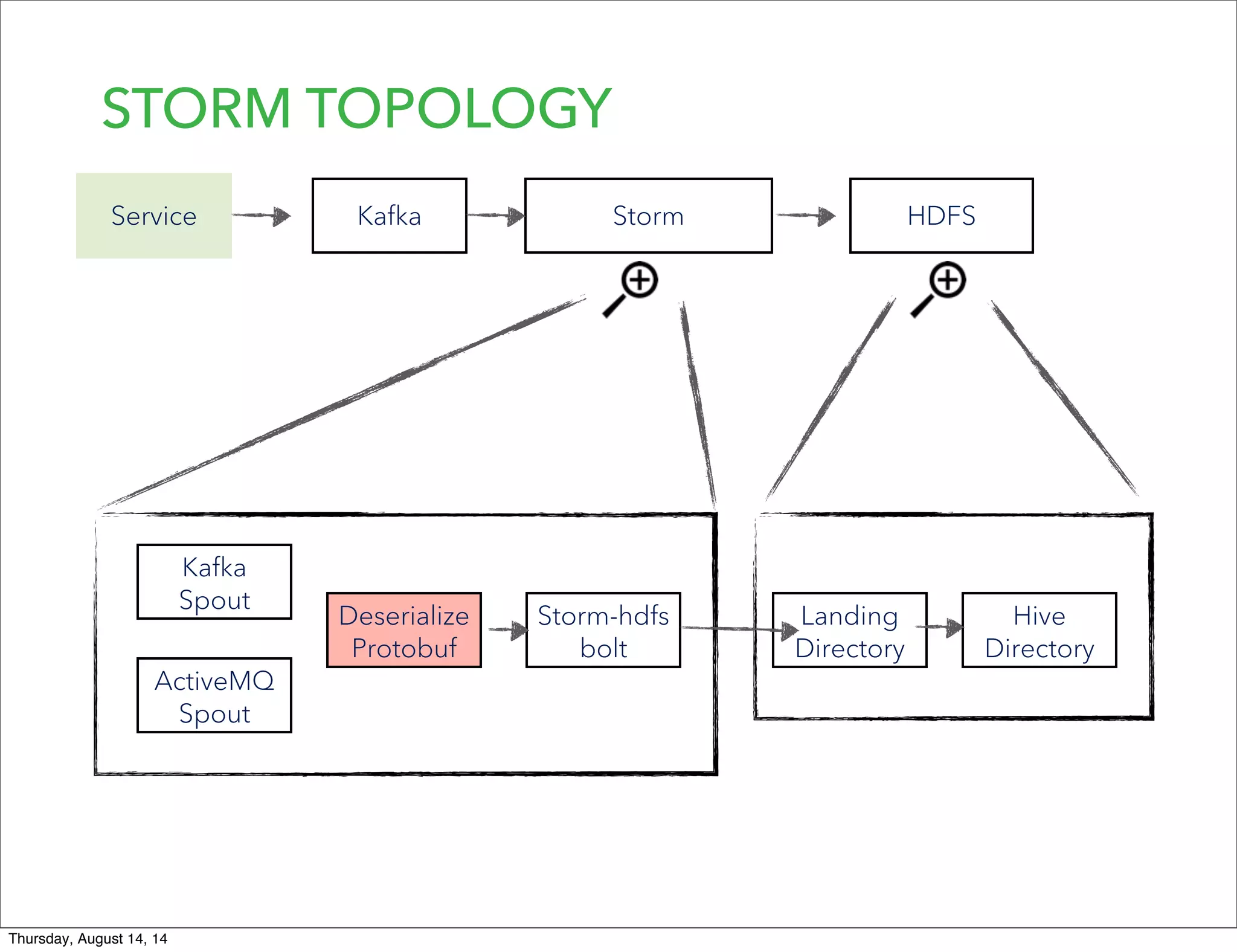





Lookout uses Hadoop to analyze data from over 50 million registered users. They have transitioned from a monolithic architecture to microservices for improved scalability and deployments. They ingest data using Kafka and Storm to process JSON events into Parquet files stored in HDFS. They are exploring using Spark for ETL/ML and H20 for in-memory machine learning.













































































