Downloaded 11 times










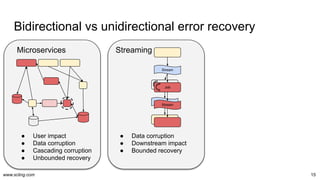

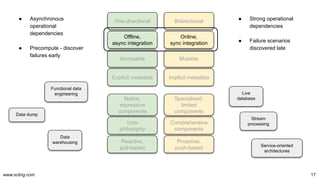






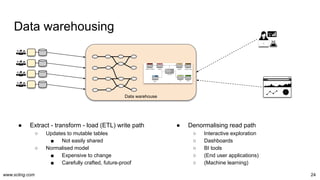



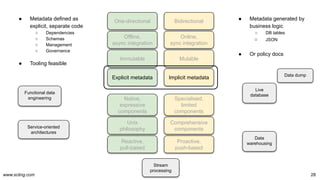

![www.scling.com
class Session(SparkSubmitTask):
"""Sessions ending or active during a particular hour."""
hour = DateHourParameter()
window_size = IntParameter(default=4)
jar = 'orderpipeline.jar'
entry_class = 'com.example.shop.SessionJob'
def requires(self):
return [Click(hour=self.hour - offset))
for offset in range(self.window_size)]
def output(self):
return GCSTarget("gs://mybucket/prod/red/order_user/v1/" +
f"{self.hour:year=%Y/month=%m/day=%d/hour=%H}")
def app_options(self):
return ["--clicks", ",".join(
[req.output().path for req in self.requires]),
"--output", self.output().path]
DAG example, window (simplified)
Click
Session
31
● Immutable, reproducible
● Free to consume by downstream
○ Without ops risk
○ Without human sync](https://image.slidesharecdn.com/allthedataopsalltheparadigms-250617171934-55b90e8e/85/All-the-DataOps-all-the-paradigms-31-320.jpg)

![www.scling.com
Schema definitions
34
{
"type" : "record",
"namespace" : "com.mapflat.example",
"name" : "User",
"fields" : [
{ "name" : "id" , "type" : "int" },
{ "name" : "name" , "type" : "string" },
{ "name" : "age" , "type" : "int" },
{ "name" : "phone" , "type" : ["null", "string"],
"default": null }
]
}
● RDBMS: Table metadata
● Avro format: JSON/DSL definition
○ Definition is bundled with avro data files
○ Reused by Parquet format
● pyschema / dataclass
● Scala case classes
● JSON-schema
● JSON: Each record
○ One record insufficient to deduce schema
{ "id": 1, "name": "Alice", "age": "34" }
{ "id": 1, "name": "Bob", "age": "42", "phone": "08-123456" }
case class User(id: String, name: String, age: Int,
phone: Option[String] = None)
val users = Seq( User("1", "Alice", 32),
User("2", "Bob", 43, Some("08-123456")))](https://image.slidesharecdn.com/allthedataopsalltheparadigms-250617171934-55b90e8e/85/All-the-DataOps-all-the-paradigms-34-320.jpg)
![www.scling.com
● Expressive
● Custom types
● Scalameta
● IDE support
● Avro for data lake storage
Schema definition choice
35
● RDBMS: Table metadata
● Avro: JSON/DSL definition
○ Definition is bundled with avro data files
○ Reused by Parquet format
● pyschema / dataclass
● Scala case classes
● JSON-schema
● JSON: Each record
○ One record insufficient to deduce schema
case class User(id: String, name: String, age: Int,
phone: Option[String] = None)
val users = Seq( User("1", "Alice", 32),
User("2", "Bob", 43, Some("08-123456")))](https://image.slidesharecdn.com/allthedataopsalltheparadigms-250617171934-55b90e8e/85/All-the-DataOps-all-the-paradigms-35-320.jpg)












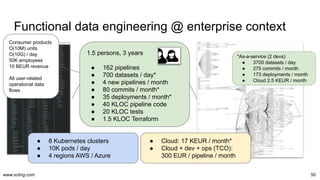

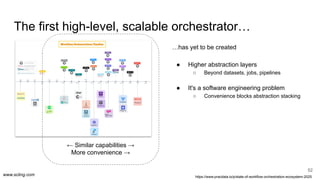



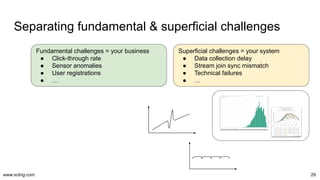
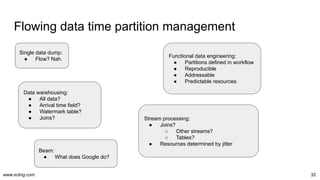
Data warehouses, lakes, lakehouses, streams, fabrics, hubs, vaults, and meshes. We sometimes choose deliberately, sometimes influenced by trends, yet often get an organic blend. But the choices have orders of magnitude in impact on operations cost and iteration speed. Let's dissect the paradigms and their operational aspects once and for all.
























































![[DSC Europe 25] Srba Markovic - From Pilot to Production: Overcoming AI Deplo...](https://cdn.slidesharecdn.com/ss_thumbnails/yjjmrtytmwbalxlba7px-4-srba-markovic-from-pilot-to-production-overcoming-ai-deployment-blockers-with-260114111931-4a892d44-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dragan Jerosimovic - The Anatomy of a Narrative Simulation.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/vzputuprdqr6zwbrwdcw-1-dragan-jerosimovic-the-anatomy-of-a-narrative-simulation-260114111931-9d04fba2-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Stefan Brankovic - #ResumeIsDead. AI-Powered Interviews and C...](https://cdn.slidesharecdn.com/ss_thumbnails/qnmbsv0xq3uysdrq3sev-2-stefan-brankovic-job-bolt-260114111931-a065aa3d-thumbnail.jpg?width=640&height=640&fit=bounds)





