




























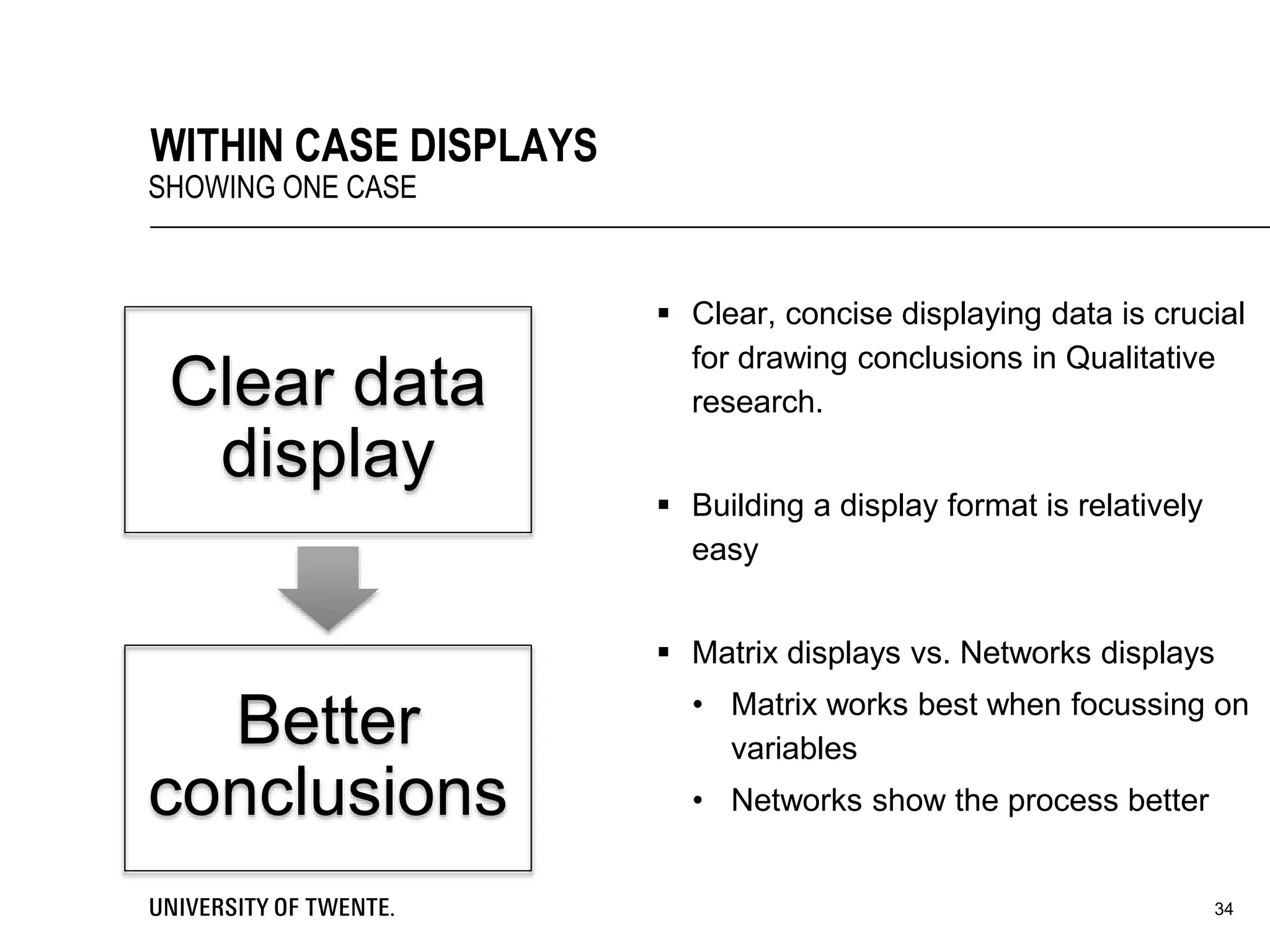

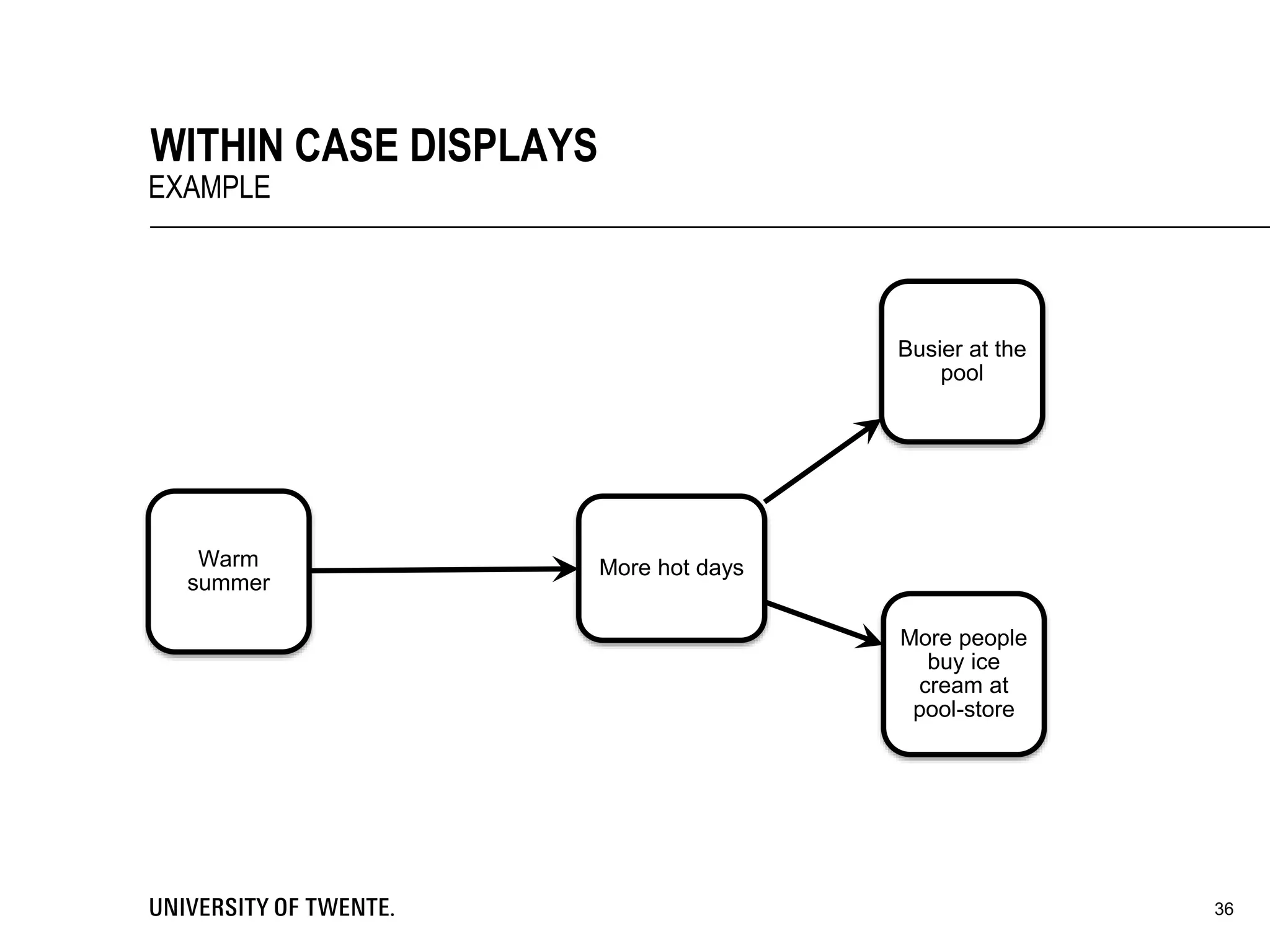
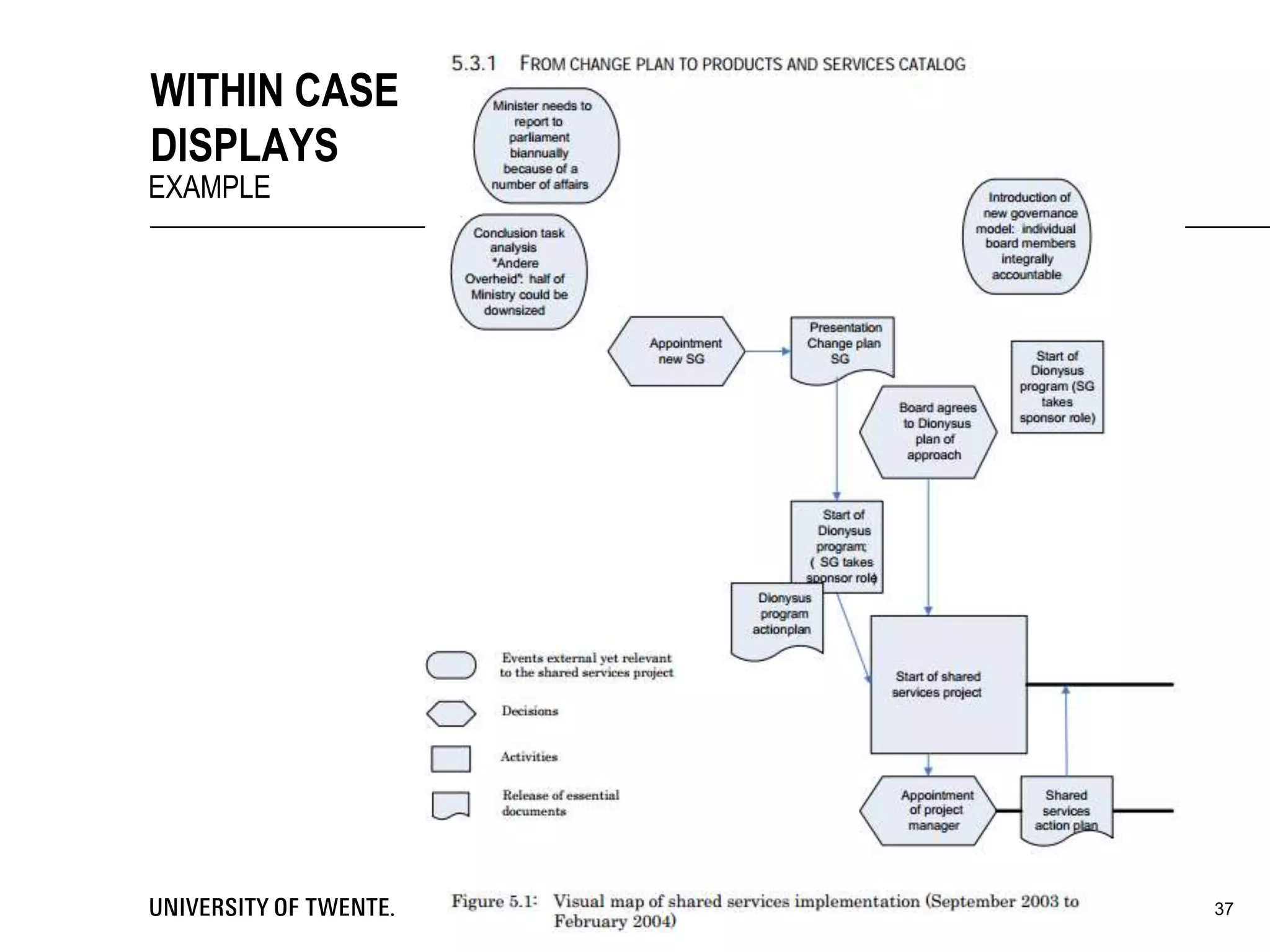




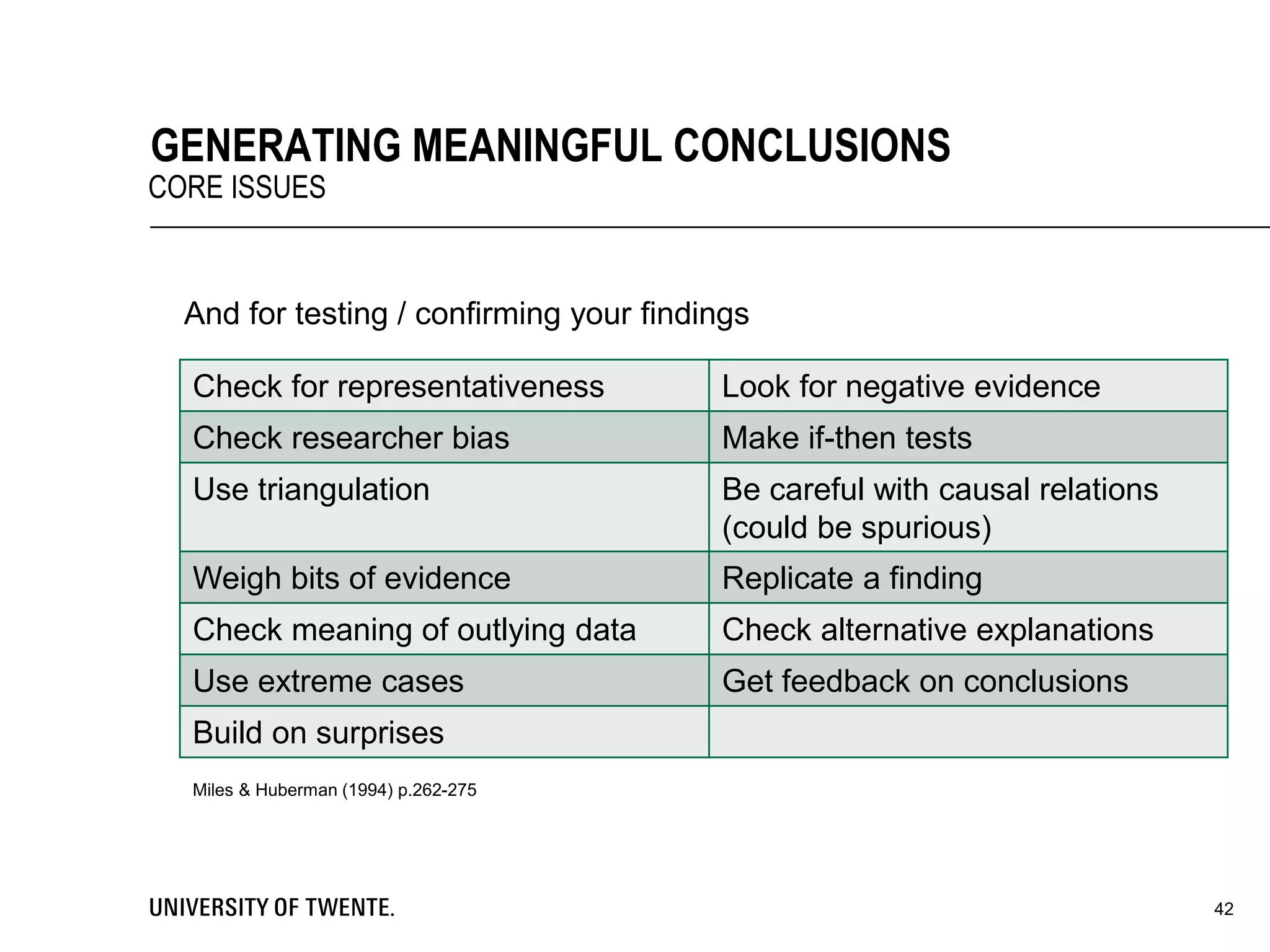








This document provides guidance on conducting qualitative research. It discusses key aspects of the research process such as developing a conceptual framework, determining what and who to study, collecting data through methods like interviews and observation, and analyzing the data through techniques such as coding and creating displays. The document emphasizes generating conclusions that consider alternative explanations and testing findings for reliability and generalizability.






































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)
















