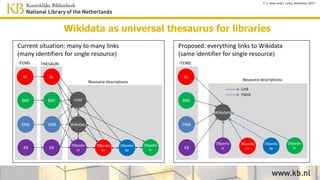
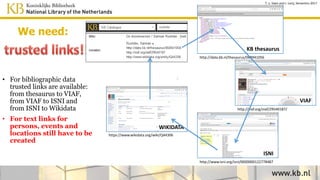
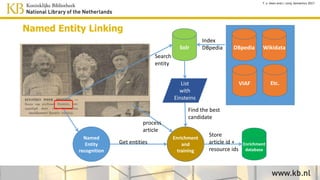
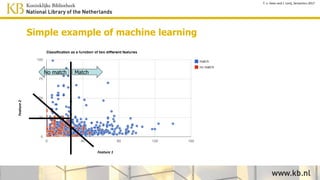
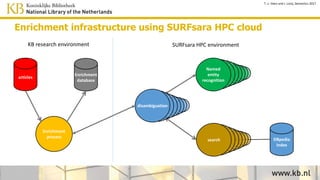
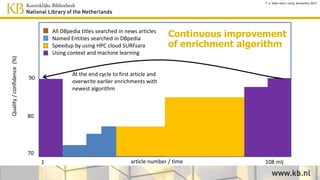
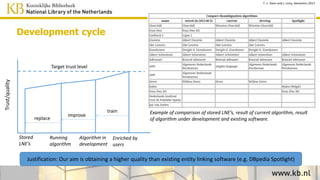
This document discusses improving access to digital collections through semantic enrichment. It describes linking names and entities from text to knowledge bases like Wikidata to make the content more discoverable and usable. The process involves named entity recognition, entity linking using disambiguation algorithms, presenting enriched context, and enabling semantic search. User feedback is gathered to improve the linking algorithms through additional training. The goal is to increase trust in the links for research purposes. Overall, the approach aims to enrich text collections by connecting content to external information sources.











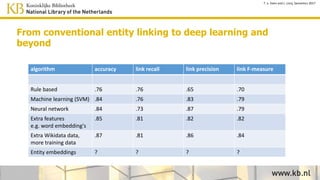
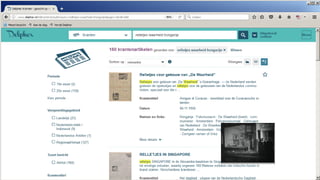


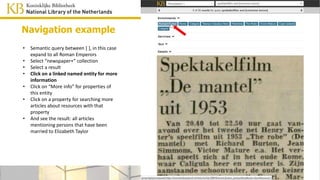
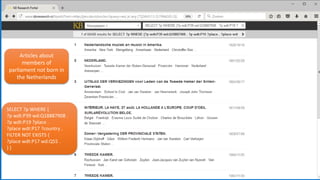
![• Semantic query between [ ], in this
case expand to all Roman Emperors
• Select “newspaper+” collection
• Select a result
• Click on a linked named entity for more
information
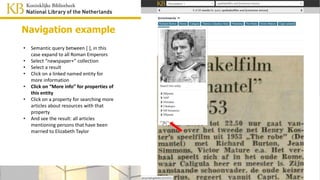
• Click on “More info” for properties of
this entity
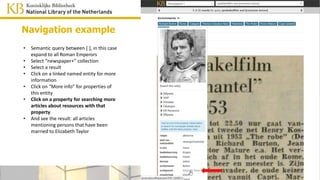
• Click on a property for searching more
articles about resources with that
property
• And see the result: all articles
mentioning persons that have been
married to Elizabeth Taylor
Navigation example Using square brackets the
software tries a few
Wikidata SPARQL queries
and replaces this string
by the Wikidata results.](https://image.slidesharecdn.com/6cnhwbutsogpzta2qux4-signature-8036fbb5b78c2cc1acdc72f9f7af5fc1f451a20e58753a03b5ae4b4dc5f6f76e-poli-170919155800/85/Session-1-2-improving-access-to-digital-content-by-semantic-enrichment-25-320.jpg)
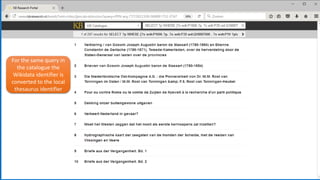
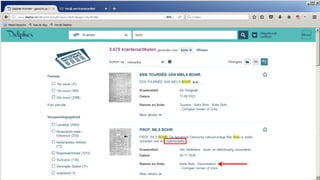
![• Semantic query between [ ], in this case
expand to all Roman Emperors
• Select “newspaper+” collection
• Select a result
• Click on a linked named entity for more
information
• Click on “More info” for properties of
this entity
• Click on a property for searching more
articles about resources with that
property
• And see the result: all articles
mentioning persons that have been
married to Elizabeth Taylor
Navigation example](https://image.slidesharecdn.com/6cnhwbutsogpzta2qux4-signature-8036fbb5b78c2cc1acdc72f9f7af5fc1f451a20e58753a03b5ae4b4dc5f6f76e-poli-170919155800/85/Session-1-2-improving-access-to-digital-content-by-semantic-enrichment-26-320.jpg)
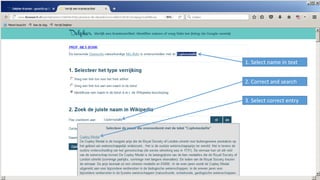
![• Semantic query between [ ], in this case
expand to all Roman Emperors
• Select “newspaper+” collection
• Select a result
• Click on a linked named entity for more
information
• Click on “More info” for properties of
this entity
• Click on a property for searching more
articles about resources with that
property
• And see the result: all articles
mentioning persons that have been
married to Elizabeth Taylor
Navigation example](https://image.slidesharecdn.com/6cnhwbutsogpzta2qux4-signature-8036fbb5b78c2cc1acdc72f9f7af5fc1f451a20e58753a03b5ae4b4dc5f6f76e-poli-170919155800/85/Session-1-2-improving-access-to-digital-content-by-semantic-enrichment-27-320.jpg)
![• Semantic query between [ ], in this
case expand to all Roman Emperors
• Select “newspaper+” collection
• Select a result
• Click on a linked named entity for
more information
• Click on “More info” for properties of
this entity
• Click on a property for searching more
articles about resources with that
property
• And see the result: all articles
mentioning persons that have been
married to Elizabeth Taylor
Navigation example](https://image.slidesharecdn.com/6cnhwbutsogpzta2qux4-signature-8036fbb5b78c2cc1acdc72f9f7af5fc1f451a20e58753a03b5ae4b4dc5f6f76e-poli-170919155800/85/Session-1-2-improving-access-to-digital-content-by-semantic-enrichment-28-320.jpg)
![• Semantic query between [ ], in this case
expand to all Roman Emperors
• Select “newspaper+” collection
• Select a result
• Click on a linked named entity for more
information
• Click on “More info” for properties of
this entity
• Click on a property for searching more
articles about resources with that
property
• And see the result: all articles
mentioning persons that have been
married to Elizabeth Taylor
Navigation example](https://image.slidesharecdn.com/6cnhwbutsogpzta2qux4-signature-8036fbb5b78c2cc1acdc72f9f7af5fc1f451a20e58753a03b5ae4b4dc5f6f76e-poli-170919155800/85/Session-1-2-improving-access-to-digital-content-by-semantic-enrichment-29-320.jpg)
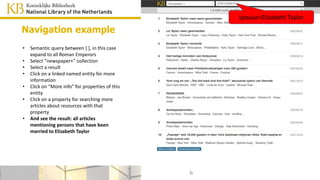
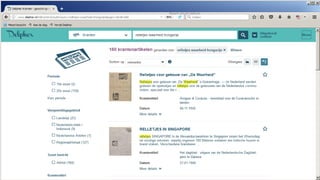
![spouse=Elizabeth Taylor
• Semantic query between [ ], in this case
expand to all Roman Emperors
• Select “newspaper+” collection
• Select a result
• Click on a linked named entity for more
information
• Click on “More info” for properties of this
entity
• Click on a property for searching more
articles about resources with that
property
• And see the result: all articles
mentioning persons that have been
married to Elizabeth Taylor
Navigation example](https://image.slidesharecdn.com/6cnhwbutsogpzta2qux4-signature-8036fbb5b78c2cc1acdc72f9f7af5fc1f451a20e58753a03b5ae4b4dc5f6f76e-poli-170919155800/85/Session-1-2-improving-access-to-digital-content-by-semantic-enrichment-30-320.jpg)