Downloaded 13 times






![Ontological definitionUnderstandsIs RDF “Slice”[1]SoftwareThe Semantic Map allowsany software that can interpret RDF to work with any semantic idea that can be associated with an ontological definition.1http://rdftef.sourceforge.net/](https://image.slidesharecdn.com/dhseasr-100715084743-phpapp02/85/Semantic-Cartography-Using-ontologies-to-create-adaptable-tools-for-text-exploration-7-320.jpg)
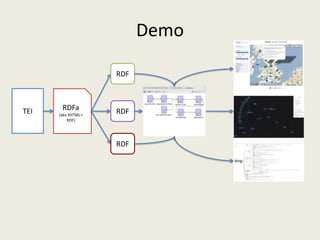

The document discusses the development of the SEASR Workbench, a tool for exploring TEI-encoded texts funded by a NEH Digital Humanities grant. It highlights the challenges of handling variability in TEI encoding and proposes the use of semantic mapping via ontologies and RDF to create adaptable text exploration tools. The work aims to enhance scholarly research through better integration and interpretation of encoded data.
















































































