Download as PDF, PPTX











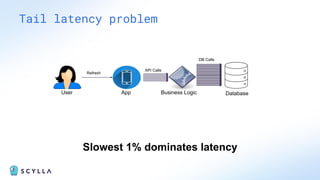
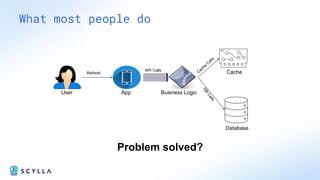
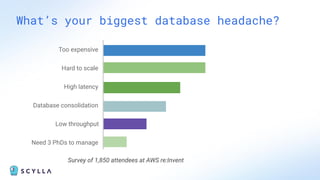
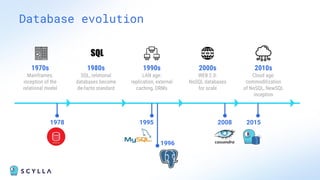
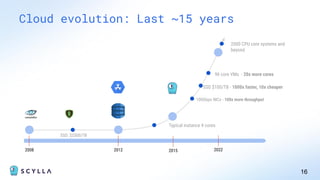




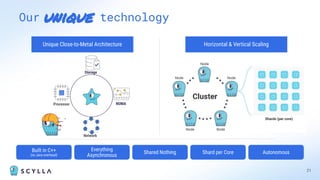
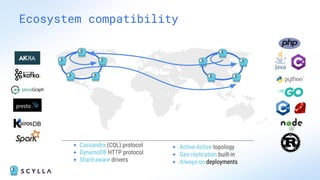
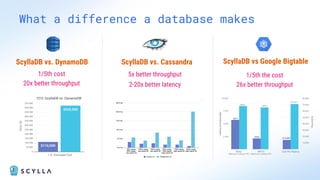


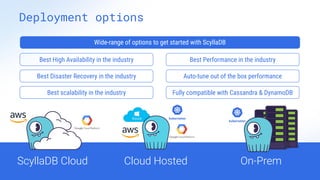
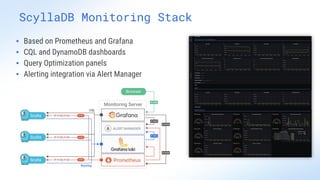
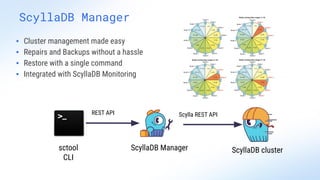









ScyllaDB is a high-performance, low-latency database solution designed for data-intensive applications, offering over 5x higher throughput and over 20x lower latency compared to traditional databases. It supports modern infrastructure, provides significant cost savings, and integrates seamlessly with existing systems like Apache Cassandra and DynamoDB. The tool is aimed at eliminating complexity while ensuring predictable performance, making it suitable for a wide range of applications including real-time analytics and scalable deployment options.


![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=640&height=640&fit=bounds)




















































































