Downloaded 11 times





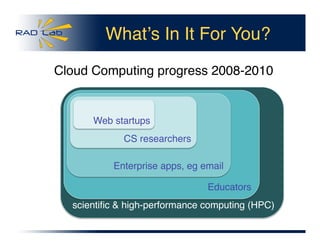











1. Cloud computing provides on-demand access to powerful computing resources at low costs, democratizing access to supercomputing capabilities. Users pay hourly rates starting at $0.085 per hour for computing power equivalent to top supercomputers. 2. Large companies like Google and Amazon are able to provide these cloud services cheaply using massive "warehouse-scale" data centers housing commodity hardware. Sophisticated software hides hardware unreliability and provides on-demand, flexible resources. 3. While cloud computing provides significant opportunities, challenges remain in programming models, handling big data, porting non-cloud scientific applications, and networking for large data transfers. Overall though, cloud computing has the potential to greatly increase access
















![[Research] azure ml anatomy of a machine learning service - Sharat Chikkerur](https://cdn.slidesharecdn.com/ss_thumbnails/researchazuremlanatomyofamachinelearningservice-sharatchikkerur-150820102331-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
















































