This document summarizes Joseph Gonzalez's background and research interests in machine learning and cloud computing. Some key points:
- Gonzalez is co-director of the RISE Lab at UC Berkeley and his research interests include AI systems and machine learning in the cloud.
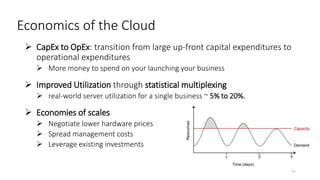
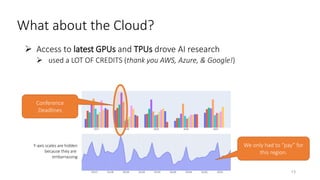
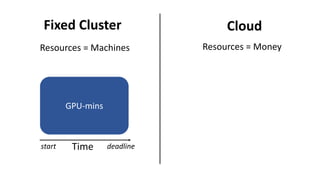
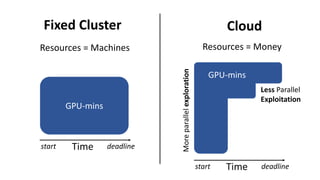
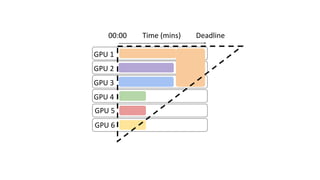
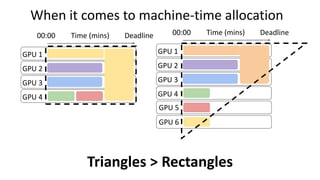
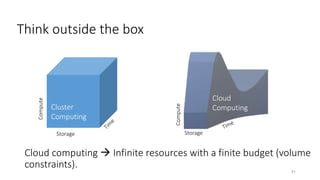
- The document traces the history of cloud computing from its early conceptualization in 1961 to its emergence in 2006 with Amazon Web Services. It discusses how cloud computing has enabled new approaches to AI research through access to vast computational resources.
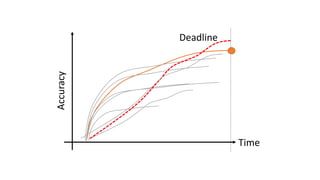
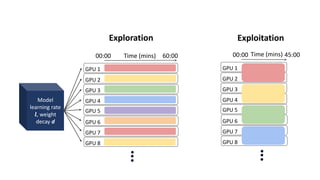
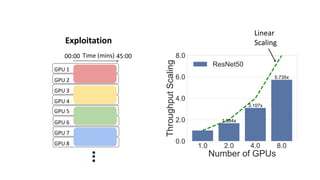
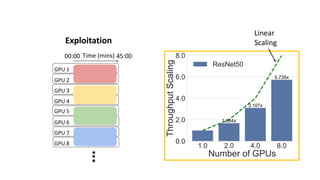
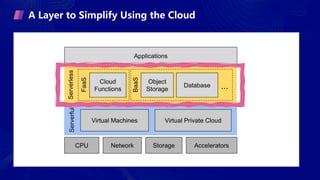
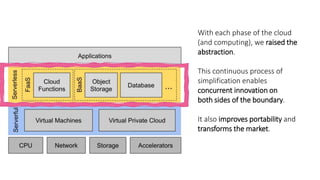
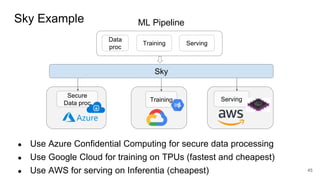
- Gonzalez argues that cloud computing represents a shift to viewing computing as a utility and that "serverless" architectures can further simplify programming and management of cloud resources. He envisions a future of "sky computing" that























![Airport Analogy
When you arrive at the destination airport and need to get to your hotel
you could:
1. Buy a car and drive [Legacy on premise systems]
Long term investment and you are responsible for everything
2. Rent a car and drive [Serverfull]
You are still responsible for fuel, parking, insurance, …
3. Take an Uber. [Serverless]
You are paying only for the transportation you need](https://image.slidesharecdn.com/cloudcomputingformlsysclass-240412180429-7a5f44de/85/cloud_computing_for_ml_sys_hhhhhhhhhhhhhhhhhhhhhhhhhhh-39-320.jpg)




![The Sky Above the Clouds [Unpublished]
Draft of the vision paper describing Sky research agenda
Do Not Distribute
Feedback will help the paper (be critical!)
Makes a case for both the inevitability and need for research in “Sky
Computing”
Things to think about:
Presentation of premise [what is proposed?]
Role of data
Role of research
ML Systems Research Case?
49](https://image.slidesharecdn.com/cloudcomputingformlsysclass-240412180429-7a5f44de/85/cloud_computing_for_ml_sys_hhhhhhhhhhhhhhhhhhhhhhhhhhh-47-320.jpg)
















































