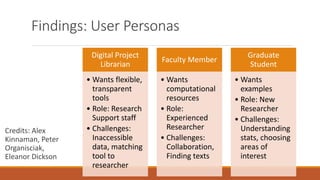
This document summarizes findings from interviews conducted as part of a user needs assessment for the HathiTrust Research Center (HTRC). Key findings discussed include:
- Scholars have challenges with data acquisition and management when conducting large-scale text analysis, such as obtaining good quality data and building reusable datasets.
- Generating and negotiating results is difficult, as scholars desire more control over tools and workflows and better archiving of data and algorithms.
- Research collaborations present challenges around work styles and the need for test datasets that multiple researchers can work with.
- Teaching and training needs include resources for faculty looking to learn about digital tools and challenges integrating computational methods into humanities classes.









![Analysis: Generating and Negotiating
Findings
“I yearn, I think, for workflows where we can actually—I don’t know what this would
look like in an interface particularly, but so that the scholar could actually set their own
tokenization rules. I think that would be really valuable. It would be a way that we could
create less language specific or actually, I should say control the language specificity of
the algorithm. I think that is the real need.”
“I wish more people were archiving their data and their algorithms from the source
code, as you see CS papers that will benchmark results against a dataset that’s no
longer valid, available. Then how do you try to replicate or beat those results? It
becomes impossible to evaluate your own methods against theirs and really slows
down the pace of research, because if one could surpass state of the art, then that’s an
application and [a] step forward.”](https://image.slidesharecdn.com/dh2016slidesfinalrevised-160714151651/85/Scholarly-Requirements-for-Large-Scale-Text-Analysis-9-320.jpg)