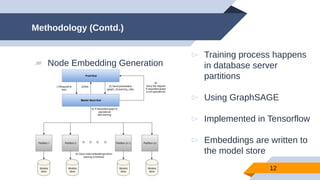
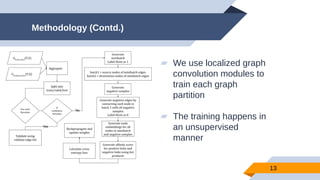
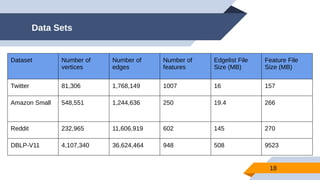
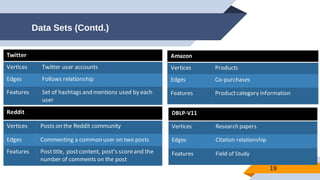
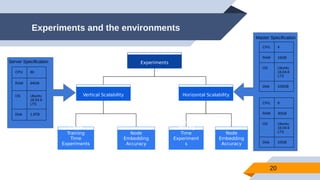
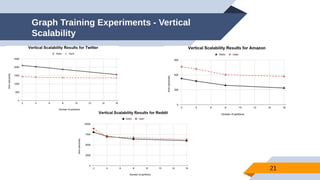
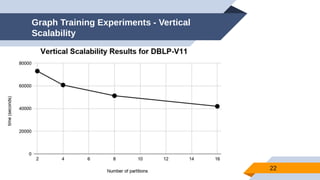
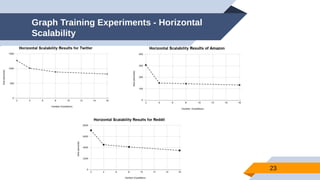
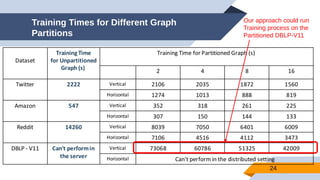
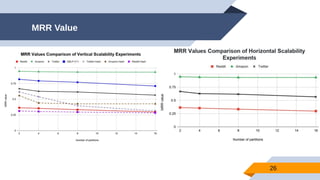
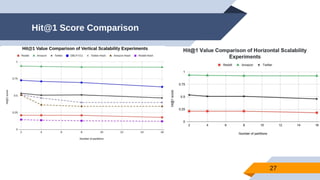
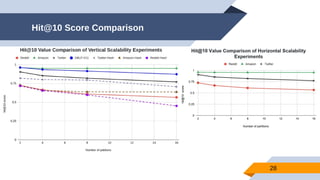
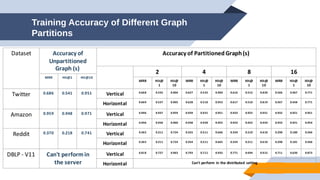
The document discusses a scalable approach for link prediction in large attributed graphs using Graph Convolutional Networks (GCNs) on a distributed graph database, JasmineGraph. It presents a scheduling algorithm to efficiently manage GCN training across multiple machine clusters, improving computational efficiency and accuracy. Key findings highlight JasmineGraph's superior performance on large datasets compared to traditional methods, achieving significant reductions in training time.


![Graph Convolutional Neural Networks
●
Until very recently little attention has been made to the generalization
of neural network models to graph structured data [1]
●
Graph Convolutional Network (GCN) is an improvement made over
Convolutional Neural Networks with the aim of encoding graphs
3
[1] https://tkipf.github.io/graph-convolutional-networks/](https://image.slidesharecdn.com/slides-201027153332/85/Scalable-Graph-Convolutional-Network-Based-Link-Prediction-on-a-Distributed-Graph-Database-Server-3-320.jpg)



![Objectives
▰ Develop a Link prediction application on top of a distributed
graph database server - JasmineGraph [1]
▰ Our approach has
▻ High accuracy by considering graph structure + node
features
▻ Computational efficiency
▻ Effective Communication Management
8
[1] M. Dayarathna (2018), miyurud/jasminegraph, GitHub. [Online]. Available:
https://github.com/miyurud/jasminegraph .](https://image.slidesharecdn.com/slides-201027153332/85/Scalable-Graph-Convolutional-Network-Based-Link-Prediction-on-a-Distributed-Graph-Database-Server-8-320.jpg)
![Related Work
9
No Related Work Relatedness Limitation
1. Link prediction using
heuristics [16]
Eg: Common Neighbour,
Jaccard coefficient, Katz
index
Link prediction mechanism on
graphs
● Finding one heuristic which can be applied for any generic
graph
● Ignoring explicit features of the graph
● Only consider the graph structure
● Capture a small set of structure patterns
2. SEAL [26] Link prediction based on local
subgraphs using a graph neural
network
● Use matrix factorization for node embeddings (train and
optimize embedding vector of each node)
● Huge number of parameters because number of node
parameters are linear with graph size
[16] David Liben-Nowell and Jon Kleinberg. The link-prediction problem for social networks. Journal of the American society for information science and
technology, 58(7):1019–1031, 2007.
[26] M. Zhang and Y. Chen. Link prediction based on graph neural networks. In Proceedings of the 32Nd International Conference on Neural Information
Processing Systems, NIPS’18, pages 5171–5181,USA, 2018. Curran Associates Inc](https://image.slidesharecdn.com/slides-201027153332/85/Scalable-Graph-Convolutional-Network-Based-Link-Prediction-on-a-Distributed-Graph-Database-Server-9-320.jpg)
![Related Work (Contd.)
10
3. GraphSAGE [10]
(Graph SAmple and
aggreGatE)
Inductive node embedding
generation based on GCN
Training on local sub-graphs is possible, but requires entire graph to
be loaded to the memory
4. Pytorch BigGraph [14] Distributed graph training
mechanism
● High number of buckets (If nodes are partitioned to p
partitions, there are p^2 buckets)
● Random node partitioning
● Shared file system
5. Euler [1] Distributed graph training
mechanism
● Distributed graph training mechanism
[1] Alibaba. Euler. URL: https://github.com/alibaba/euler , 2019.
[10] W. Hamilton, Z. Ying, and J. Leskovec, “Inductive representation learning on large graphs,” in Advances in Neural Information
Processing Systems, 2017, pp. 1024–1034.
[14] A. Ler er, L. Wu, J. Shen, T. Lacroix, L. Wehrstedt, A. Bose, and A. Peysakhovich. Pytorch-biggraph: A large-scale graph
embedding system. CoRR, abs/1903.12287, 2019.](https://image.slidesharecdn.com/slides-201027153332/85/Scalable-Graph-Convolutional-Network-Based-Link-Prediction-on-a-Distributed-Graph-Database-Server-10-320.jpg)
![Methodology - JasmineGraph
▰ JasmineGraph Distributed
Database Server [1]
▻ Partitions and stores graph
data using one of the
Metis/hash/etc. partitioning
approaches
11
[1] https://github.com/miyurud/jasminegraph](https://image.slidesharecdn.com/slides-201027153332/85/Scalable-Graph-Convolutional-Network-Based-Link-Prediction-on-a-Distributed-Graph-Database-Server-11-320.jpg)