Downloaded 10 times









![13
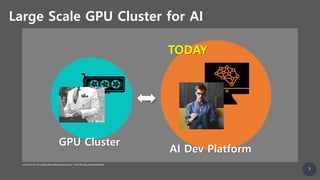
Machine Learning Platform on GPU Cluster
• Rising of Machine Learning Platform
1) Laptop, 2) High Performance Computing [HPC], 3) Machine Learning Platform
Photo by frank mckenna on Unsplash
Personal PC HPC Platform
Mark by Vladyslav Severyn from the Noun Project
+Performance +Convenience
Recall from Open Infrastructure & Cloud Native Days Korea 2019 – 대규모 GPU 기반 K8S Cluster를 활용한 ML Training Troubleshooting (조규남 발표)](https://image.slidesharecdn.com/largescalegpuclusterforai-200716143949/85/Large-scale-gpu-cluster-for-ai-14-320.jpg)








![22
New ML Trend #2
• [149] Benjamin Recht, Christopher Re, Stephen Wright, and Feng Niu. 2011. Hogwild: A lock-free approach to parallelizing stochastic gradient descent. In Advances in Neural Information Processing
Systems. MIT Press, 693–701.
• [38] Jeffrey Dean, Greg Corrado, Rajat Monga, Kai Chen, Matthieu Devin, Mark Mao, Andrew Senior, Paul Tucker, KeYang, Quoc V. Le, et al. 2012. Large scale distributed deep networks. In
Advances in Neural Information Processing Systems. MIT Press, 1223–1231.
• [28] James Cipar, Qirong Ho, Jin Kyu Kim, Seunghak Lee, Gregory R. Ganger, Garth Gibson, Kimberly Keeton, and Eric Xing. 2013. Solving the straggler problem with bounded staleness. In
Proceedings of the 14th Workshop on Hot Topics in Operating Systems (HotOS’13). USENIX, Santa Ana Pueblo, NM. Retrieved from https://www.usenix.org/conference/hotos13/solving-straggler-
problem-bounded-staleness
• [133] Cyprien Noel and Simon Osindero. 2014. Dogwild!-Distributed hogwild for CPU & GPU. In Proceedings of the NIPS Workshop on Distributed Machine Learning and Matrix Computations.
• [35] Henggang Cui, James Cipar, Qirong Ho, Jin Kyu Kim, Seunghak Lee, Abhimanu Kumar, Jinliang Wei, Wei Dai, Gregory R. Ganger, Phillip B. Gibbons, Garth A. Gibson, and Eric P. Xing. 2014.
Exploiting bounded staleness to speed up big data analytics. In Proceedings of the USENIX Conference on USENIX Annual Technical Conference (USENIX ATC’14). USENIX Association, Berkeley,
CA, 37–48. Retrieved from http://dl.acm.org/citation.cfm?id=2643634.2643639.
• [102] Mu Li, David G. Andersen, Jun Woo Park, Alexander J. Smola, Amr Ahmed, Vanja Josifovski, James Long, Eugene J. Shekita, and Bor-Yiing Su. 2014. Scaling distributed machine learning with
the parameter server. In Proceedings of the 11th USENIX Symposium on Operating Systems Design and Implementation (OSDI’14). USENIX Association, Broomfield, CO, 583–598. Retrieved from
https://www.usenix.org/conference/osdi14/technical-sessions/presentation/li_mu.
• [37] Wei Dai, Abhimanu Kumar, Jinliang Wei, Qirong Ho, Garth Gibson, and Eric P. Xing. 2015. High-performance distributed ML at scale through parameter server consistency models. In Proceedings
of the 29th AAAI Conference on Artificial Intelligence (AAAI’15). AAAI Press, 79–87. Retrieved from http://dl.acm.org/citation.cfm?id=2887007.2887019
• [101] Hao Li, Asim Kadav, Erik Kruus, and Cristian Ungureanu. 2015. MALT: Distributed data-parallelism for existing ML applications. In Proceedings of the 10th European Conference on Computer
Systems (EuroSys’15). ACM, New York, NY. DOI:https://doi.org/10.1145/2741948.2741965
• [204] H. Zhang, C. Hsieh, and V. Akella. 2016. HogWild++: A new mechanism for decentralized asynchronous stochastic gradient descent. In Proceedings of the IEEE 16th International Conference on
Data Mining (ICDM’16). 629–638. DOI:https://doi.org/10.1109/ICDM.2016.0074
• [36] Henggang Cui, Hao Zhang, Gregory R. Ganger, Phillip B. Gibbons, and Eric P. Xing. 2016. GeePS: Scalable deep learning on distributed GPUs with a GPU-specialized parameter server. In
Proceedings of the 11th European Conference on Computer Systems (EuroSys’16). ACM, New York, NY. DOI:https://doi.org/10.1145/2901318.2901323
• [83] Jiawei Jiang, Bin Cui, Ce Zhang, and Lele Yu. 2017. Heterogeneity-aware distributed parameter servers. In Proceedings of the ACM International Conference on Management of Data
(SIGMOD’17). ACM, New York, NY, 463–478. DOI:https://doi.org/10.1145/3035918.3035933
• [184] Shaoqi Wang, Wei Chen, Aidi Pi, and Xiaobo Zhou. 2018. Aggressive synchronization with partial processing for iterative ml jobs on clusters. In Proceedings of the 19th International Middleware
Conference (Middleware’18). ACM, New York, NY, 253–265. DOI:https://doi.org/10.1145/3274808.3274828
• [89] Alexandros Koliousis, Pijika Watcharapichat, Matthias Weidlich, Luo Mai, Paolo Costa, and Peter R. Pietzuch. 2019. CROSSBOW: Scaling deep learning with small batch sizes on multi-GPU
servers. Retrieved from http://arxiv.org/abs/1901.02244.
• [19] Keith Bonawitz, Hubert Eichner, Wolfgang Grieskamp, Dzmitry Huba, Alex Ingerman, Vladimir Ivanov, Chloe M. Kiddon, Jakub Konecný, Stefano Mazzocchi, Brendan McMahan, Timon Van
Overveldt, David Petrou, Daniel Ramage, and Jason Roselander. 2019. Towards federated learning at scale: System design. In Proceedings of the Conference on Systems and Machine Learning
(SysML’19). Retrieved from https://arxiv.org/abs/1902.01046.](https://image.slidesharecdn.com/largescalegpuclusterforai-200716143949/85/Large-scale-gpu-cluster-for-ai-23-320.jpg)






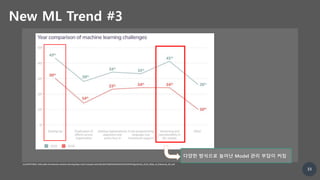
![29
New ML Trend #3
• [4] B. Zoph and Q. V. Le, “Neural architecture search with reinforcement learning.” [Online]. Available: http://arxiv.org/abs/1611.01578
• [5] H. Pham, M. Y. Guan, B. Zoph, Q. V. Le, and J. Dean, “Efficient neural architecture search via parameter sharing,” vol. ICML. [Online]. Available: http://arxiv.org/abs/1802.03268
• [7] B. Zoph, V. Vasudevan, J. Shlens, and Q. V. Le, “Learning transferable architectures for scalable image recognition.” [Online]. Available: http://arxiv.org/abs/1707.07012
• [8] Z. Zhong, J. Yan, W. Wu, J. Shao, and C.-L. Liu, “Practical block-wise neural network architecture generation.” [Online]. Available: http://arxiv.org/abs/1708.05552
• [9] H. Liu, K. Simonyan, and Y. Yang, “DARTS: Differentiable architecture search.” [Online]. Available: http://arxiv.org/abs/1806.09055
• [10] C. Liu, B. Zoph, M. Neumann, J. Shlens, W. Hua, L.-J. Li, L. Fei-Fei, A. Yuille, J. Huang, and K. Murphy, “Progressive neural architecture search.” [Online]. Available:
http://arxiv.org/abs/1712.00559
• [11] H. Liu, K. Simonyan, O. Vinyals, C. Fernando, and K. Kavukcuoglu, “Hierarchical representations for efficient architecture search,” in ICLR, p.
• [15] B. Baker, O. Gupta, N. Naik, and R. Raskar, “Designing neural network architectures using reinforcement learning,” vol. ICLR. [Online]. Available: http://arxiv.org/abs/1611.02167
• [17] E. Real, S. Moore, A. Selle, S. Saxena, Y. L. Suematsu, J. Tan, Q. Le, and A. Kurakin, “Large-scale evolution of image classifiers.” [Online]. Available: http://arxiv.org/abs/1703.01041
• [18] E. Real, A. Aggarwal, Y. Huang, and Q. V. Le, “Regularized evolution for image classifier architecture search.” [Online]. Available: http://arxiv.org/abs/1802.01548
• [19] T. Elsken, J. H. Metzen, and F. Hutter, “Efficient multi-objective neural architecture search via lamarckian evolution.” [Online]. Available: http://arxiv.org/abs/1804.09081
• [20] M. Suganuma, S. Shirakawa, and T. Nagao, “A genetic programming approach to designing convolutional neural network architectures.” [Online]. Available: http://arxiv.org/abs/1704.00764
• [21] R. Miikkulainen, J. Liang, E. Meyerson, A. Rawal, D. Fink, O. Francon, B. Raju, H. Shahrzad, A. Navruzyan, N. Duffy, and B. Hodjat, “Evolving deep neural networks.” [Online]. Available:
http://arxiv.org/abs/1703.00548
• [22] L. Xie and A. Yuille, “Genetic CNN,” vol. ICCV. [Online]. Available: http://arxiv.org/abs/1703.01513
• [94] H. Cai, L. Zhu, and S. Han, “Proxylessnas: Direct neural architecture search on target task and hardware,” arXiv preprint arXiv:1812.00332, 2018.
• [96] X. Chen, L. Xie, J. Wu, and Q. Tian, “Progressive differentiable architecture search: Bridging the depth gap between search and evaluation,” in Proceedings of the IEEE International Conference
on Computer Vision, 2019, pp. 1294–1303.
• [123] S. Xie, H. Zheng, C. Liu, and L. Lin, “Snas: stochastic neural architecture search,” arXiv preprint arXiv:1812.09926, 2018.
• [125] G. D. H. Andrew Hundt, Varun Jain, “sharpDARTS: Faster and More Accurate Differentiable Architecture Search,” Tech. Rep. [Online]. Available: https://arxiv.org/pdf/1903.09900.pdf
• [142] R. Luo, F. Tian, T. Qin, E. Chen, and T.-Y. Liu, “Neural architecture optimization,” in Advances in neural information processing systems, 2018, pp. 7816–7827.
• [143] L. Li and A. Talwalkar, “Random search and reproducibility for neural architecture search,” arXiv preprint arXiv:1902.07638, 2019.](https://image.slidesharecdn.com/largescalegpuclusterforai-200716143949/85/Large-scale-gpu-cluster-for-ai-30-320.jpg)













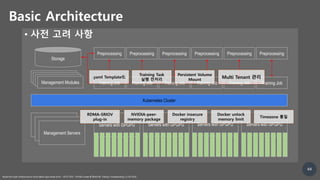





![50
Troubleshooting
• vGPU Issue
- Hardware vender dependence, VM Only (NVIDIA Grid vGPU)
Image from NVIDIA official document https://docs.nvidia.com/grid/4.3/grid-vgpu-user-guide/index.html
[ vGPU Overall Architecture ]
Solution
Servers with
GPGPU
Kubernetes Cluster
Servers with
GPGPU
Servers with
GPGPU
OpenStack Cluster
VM with vGPGPU VM with vGPGPU VM with vGPGPU
Training Job Training Job Training Job Training Job
Recall from Open Infrastructure & Cloud Native Days Korea 2019 – 대규모 GPU 기반 K8S Cluster를 활용한 ML Training Troubleshooting (조규남 발표)](https://image.slidesharecdn.com/largescalegpuclusterforai-200716143949/85/Large-scale-gpu-cluster-for-ai-51-320.jpg)



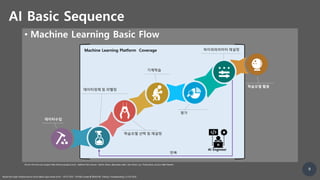
1. Large scale GPU clusters are increasingly being used for machine learning training as neural network architectures become more complex and distributed training becomes necessary. 2. New trends in machine learning include more complex neural network architectures, diverse data types and applications, automated machine learning, and federated learning which distributes training across decentralized devices. 3. To support these new trends, machine learning platforms need to enable fine-grained customization of hardware and software as well as distributed training across multiple nodes.




























![[AWS Dev Day] 인공지능 / 기계 학습 | AWS 기반 기계 학습 자동화 및 최적화를 위한 실전 기법 - 남궁영환 AWS 솔루션...](https://cdn.slidesharecdn.com/ss_thumbnails/20190926-devday-aiml3-younghwan-final-190930020120-thumbnail.jpg?width=640&height=640&fit=bounds)




![[AWS Dev Day] 실습워크샵 | 모두를 위한 컴퓨터 비전 딥러닝 툴킷, GluonCV 따라하기](https://cdn.slidesharecdn.com/ss_thumbnails/gluoncv-190930065523-thumbnail.jpg?width=640&height=640&fit=bounds)






![[AWS Dev Day] 인공지능 / 기계 학습 | 개발자를 위한 수백만 사용자 대상 기계 학습 서비스 확장 하기 - 윤석찬 AWS 수석테...](https://cdn.slidesharecdn.com/ss_thumbnails/scalableawsmlservicefromzerotomillions-190927015651-thumbnail.jpg?width=640&height=640&fit=bounds)


























