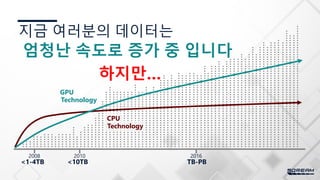
“BUT YOUR DATABASEWASN’T
BUILT TO HANDLE THIS LEVEL OF DATA”
NoSQL & Hadoop GPU Database Relational DB
MPP In-Memory Massive Data
Hive-Hadoop
Kinetica
SAP HANA
Mongo DB SQREAM DBOmnisci
(MapD)
MemSQL
VoltDB
DB2 BLU
IBM
Netezza
IBM
Oracle
DB2
Teradata
Vertica Redshift
Exadata
Oracle
Server
SQL
Classic Relational
Snowflake BigQuery
Public Cloud Only
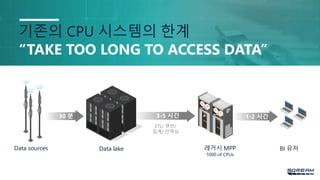
INGESTION시 GPU활용
수천개의 프로세싱 CORE
900 GB/s 메모리 Bandwidth
데이터 압축
메타데이터 수집
대용량 데이터 스트림에 대한 반복 처리
강력한 데이터 INGEST
15.
GPU – 새로운패러다임
• GPU 기술은 빠른 속도로 성장 하고 있음 – 수천개의 CORE
• 놀라운 메모리 Throughput 성능 – 900GB/s
• GPU 당 약 33 Tflops. X86 Server는 약 3Tflops 지원함
• GPU는 “Throughput Oriented”
• 연산 처리 (Number Crunching)에 특화됨 – (압축알고리즘, SORTING 알고리즘, 집계처리 등)
Cache
ALU
Control
ALU
ALU
ALU
DRAM
CPU
DRAM
GPU
17
SQREAM DB는..
• Massivelyparallel engine
• Faster and smaller than CPUs
POWERED
BY GPUs
• 테라바이트 페타바이트
• 메모리 제약 사항 없음
• Ingests 3 TB/hr/GPU (평균)
• 컬럼기반의 데이터 저장
• 상시 압축
• ANSI SQL 표준
• 표준 커넥터 제공
• 2U 서버에 100TB 분석
• 높은 TCO
• Python, AI, Jupyter, etc.
• Built for data science
보유한 현재 DATA STORE의 분석 범위를 확장
MASSIVELY
SCALABLE
SQL
DATABASE
EXTENSIBLE
FOR ML/AI
MINIMAL
FOOTPRINT
LIGHTNING
FAST
18.
18
개념 1
• 컬럼기반의 데이터베이스는 검증된
BI 특화된 데이터베이스 기술 임
• 빅데이터 분석에 용이함 – 시계열
집계 처리 등
• 컬럼기반 아키텍처는 가장 효율적인
데이터 압축을 가능케 함
COLUMNAR
19.
19
개념 2
• “Chunking”아키텍처를 통한 다차원화 된 PARTIONTIONING 기술을 제공 함 – 이는 데이터
스캐닝 시 필요한 데이터만 찾는 Data Skipping을 가능케 함 – 다음 장 참조
• 데이터 Ingestion 중 자동으로 Chunking Process는 수행 됨
CHUNKING
Table
Chunks
Columns
20.
20
개념 3
• Alwayson, calculated for every chunk
• 예:
SELECT * FROM t WHERE YEAR>2017
(all chunks with YEAR<=2017 can be skipped)
SMART METADATA / DATA SKIPPING
day month year val1 val2 val3
10 2017
11 2017
12 2017
01 2018
02 2018
03 2018
이 부분만
읽게 됨
이 부분은
“SKIPPING” 됨
데이터베이스 관리에 있어 인덱스 개념은 사라짐
21.
21
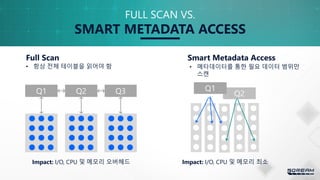
FULL SCAN VS.
•항상 전체 테이블을 읽어야 함 • 메타데이터를 통한 필요 데이터 범위만
스캔
SMART METADATA ACCESS
Smart Metadata Access
Q1 Q2 Q3
Q2
Q1
Impact: I/O, CPU 및 메모리 최소Impact: I/O, CPU 및 메모리 오버헤드
Full Scan
22.
22
개념 4
원시 데이 터 VS 압축데이터
• Sqream은 항시 데이터 압축을 자동으로 진행하며 GPU를 활용 함
• 대부분의 데이터베이스는 데이터 로딩 이후 수동 작업을 통해 압축을 진행 함
• 자동적이고 유동적으로 (Automatic Adaptive Compression) 원시 데이터에 가장
최적화된 압축 알고리즘을 채택 하며 이는 쿼리 성능에도 최상의 결과를 도출함
• 평균 1:5 압축율을 기대 할 수 있으며 80% 스토리지 용량 개선 뿐만 아니라 80%
이상의 I/O 개선에도 기여 함
• 원시 데이터 100 TB -> (20 TB, + 수 GB 의 메타데이터) 의 SQream 데이터
23.
23
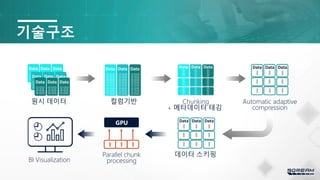
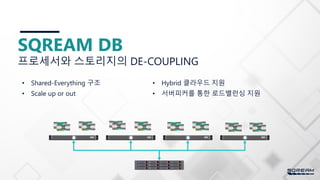
기술구조
Automatic adaptive
compression
Data DataData
GPU
Parallel chunk
processing
데이터 스키핑
Data Data Data
Chunking
Data Data Data
+ 메타데이터 태깅
컬럼기반
Data DataDataData
원시 데이터
Data Data Data
Data Data Data
Data Data Data
BI Visualization
SEAMLESS 인터페이스
AS-IS BI환경과
Java | Python | SQL | R | C++
- Data Sources -
- ETL and others -
- SQream DB-
Cloud Infrastructure
- BI and Visualization -
26.
GPU-POWERED ANALYTICS
• GPU서버의탁월한 컴퓨팅 파워
• 강력한 Ingestion 성능 + 압축률 +
메타데이터 수집 – 동시 진행
• 조인 쿼리 성능 (Super-Fast)
준 실시간 수준의 원시 데이터 탐색 (DATA EXPLORATION)
(TPC-DS 기준 1500억 건 - 150억 건 타임시리즈
하루 기준 테이블 조인 및 연산 처리 쿼리 – 20초 내)
4000만 고객 인사이트
통신사
HPDL380g9
with NVIDIA Tesla GPU
96 GB RAM + 6 TB storage
$200K
40 NODES
5 full racks
7600 CPU cores
$10,000,000
18M
10M
360M
120M
Ingest time
Reporting time
Ownership Cost
30.
쿼리 및 보고서처리 시간 단축
기존 레거시 MPP 를 GPU-POWERED SQream으로 교체
AIS는 더 많은 데이터 DRILL 범위를 갖게 됨
예: OOKLA를 통해 4G Speed Test 결과 원시
데이터 분석을 진행 함 (3개의 통신사 대상). 이에
대한 한주간 비교분석을 AIS를 대상으로 진행
데이터 적재 이후, AIS는 그 어떤 지연 없이
다각의 디멘션을 분석 할 수 있게 됨 (예: latency,
download speed, ppload speed)
통신사
31.
LOCATION-BASED DATA
학생들 대상캠페인
3 테이블 조인 - 33억 건 ⋈ 4000만 건 ⋈ 30만 건
• 학생들의 밀집 구간을 3G/4G 데이터 사용률을
통해 대시보드 제공
• 큰 도형은 데이터 사용률이 높은 지역을 표시함
• 색감은 하루기준으로 시간을 표시함 – 밤
시간대는 진한 색감으로 표현
• 그 어떤 중간 집계 처리 프로세스 없이
대시보드에서 직접 구현
32.
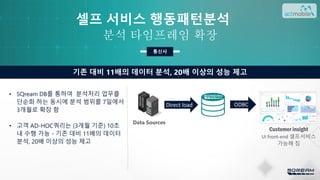
문제점
• 급증하는 데이터분석력 한계 도달, 이에
많은 데이터를 통한 인사이트 손실이 있다
고 판단 함
• 하루 평균 4만개 이상의 쿼리 수행이
가능하고 수천만 건의 데이터 Ingestion이
가능한 분석 플랫폼 도입을 고려
인도의 MULTI-CHANNEL MESSAGING 통신사
요구사항
• 통신사 고객별 자가생성 (셀프-
서비스) 행동패턴 보고서 서비스
개시
• 고객대면 서비스 품질 및 충성도
제고
33.
통신사
Data Sources
ODBCETL
Customer insight
통신사고객 셀프서비스
Legacy MPP
성능 수준이 맞지 않거나
AD_HOC 쿼리 처리 불가능
현 MPP로 불가능
• 월 평균 수백억 건 이상의 메시지
(200+여 국가 대상) 전송
• 현 MPP 시스템의 인프라 단축을 진행
하는 동시에 주 단위의 분석 업무 진행
• 현 레거시 MPP시스템은 1주간 데이터
분석 결과 UI 표현에 있어 수분간 지연
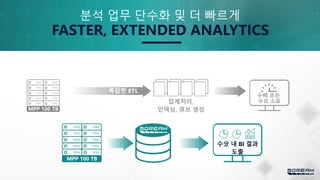
기존 대비 11배의 데이터 분석, 20배 이상의 성능 제고
분석 타임프레임 확장
셀프 서비스 행동패턴분석
34.
통신사
• SQream DB를통하여 분석처리 업무를
단순화 하는 동시에 분석 범위를 7일에서
3개월로 확장 함
• 고객 AD-HOC쿼리는 (3개월 기준) 10초
내 수행 가능 - 기존 대비 11배의 데이터
분석, 20배 이상의 성능 제고
ODBCDirect load
Customer insight
UI front-end 셀프서비스
가능해 짐
Data Sources
기존 대비 11배의 데이터 분석, 20배 이상의 성능 제고
분석 타임프레임 확장
셀프 서비스 행동패턴분석
35.
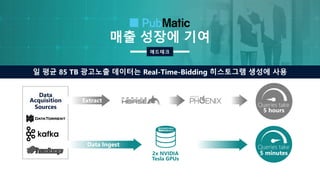
매출 성장에 기여
애드테크
TeslaGPUs
Acquisition
Sources
일 평균 85 TB 광고노출 데이터는 Real-Time-Bidding 히스토그램 생성에 사용
Data
2x NVIDIA
Queries take
5 hours
Extract
Data Ingest Queries take
5 minutes
새로운 비즈니스 인사이트발견
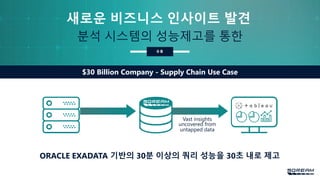
유통
$30 Billion Company - Supply Chain Use Case
분석 시스템의 성능제고를 통한
ORACLE EXADATA 기반의 30분 이상의 쿼리 성능을 30초 내로 제고
Vast insights
untapped data
uncovered from
38.
분석 성능 수준유지
유통
TCO 감축
Netezza
압축률
평균쿼리성능
(초)33.70
4.0
31.70
4.7
TCO
서버개수
(S-Blade / GPUs)
8 full 42U racks,
56 S-Blades 7 TB RAM
56
$12,000,000
Dell C4130 with
4x NVIDIA Tesla GPUs
512 GB RAM + iSCSI JBOD (20TB)
4
$500,000
ACV 계산 - 24 TB 데이터, 3000억 건, 8 개 테이블 NESTED-JOIN
SQream and Orangedemonstrate 100x cost
performance, removing limits of databases.”
“
Pascal Déchamboux | Director of Software
SQream helps us keep pace with rapidly
increasing data for real customer benefits.”
“
Suppachai Panichayunon, Head Solution Architect
WHAT OUR
CUSTOMERS SAY
SQream is helping us to cut years of cancer
research on large genomic datasets.”
“
Prof. Gideon Rechavi, Head of Cancer Research
We saw a cost effective opportunity to obtain
analytic capabilities we couldn’t have before.“
“
RF Group Leader
41.
PROOF OF VALUE
NDA
제품소개POC 계획 및 업무
분석
유스케이스분석
KPI 정의
쿼리 리뷰
데이터샘플 리뷰
킥오프
최상 인프라 제안
ETL 프로세스 설계
내부리뷰
유스케이스 검증
데이터로드 및 테스트
쿼리 옵티마이저
42.
BUSINESS VALUE IDENTIFICATION
•분석업무 유스케이스는 무엇 입니까?
• 데이터 시각화 툴은 무엇을 쓰고 계십니까?
• Terabyte 기준으로 분석에 쓰이는 데이터 용량은 어떻게 됩니까? 1-3년 내 얼마나 더
데이터 범위를 확장 할 것 같습니까?
• 현재 Data Lake 용량과 성장률은 어떻게 됩니까?
• 현재 쿼리 성능은 어떠 합니까? 얼만큼 더 제고 해야 한다고 생각 하십니까?
• 원시 데이터 소스는 어디 입니까? 충분히 분석 다각화가 (Dimension) 되어 있다고 생각
하십니까?
• 분석 업무 전체 유저수는 어떻게 됩니까? 동신 유저 수는 무엇 입니까?
43.
FAST AND SIMPLE
빅데이터탐색
원시데이터 직접 쿼리
AD-HOC에 대한 신속 처리
더 많은 분석 범위 및 더 넓은 기간 분석
더 깊은 분석 이사이트, 정확도 제고
전반 Business Intelligence 고도화
Multiple
JOINs on
any field
Time
Series
Regular
Expressions
ANSI-92
Compatible
Window
Analysis
ODBC, JDBC
Python
Connectivity
44.
FEEL FREE TO
ADDRESS
Headquarters,7 WTC
250 Greenwich Street
New York, New York
박찬호
한국기술총괄
jamesp@sqream.com | sqream.com
WE ARE SOCIAL
CONTACT
45.
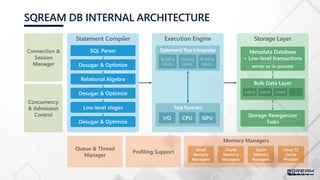
SQREAM DB INTERNALARCHITECTURE
Statement Compiler
SQL Parser
Desugar & Optimize
Relational Algebra
Desugar & Optimize
Low-level stages
Execution Engine
StatementTree Interpreter
Task Runners
I/O CPU GPU
Storage Layer
Metadata Database
+ Low-level transactions
server or in-process
Bulk Data Layer
Extent Extent Extent …
Storage Reorganizer
Tasks
Queue & Thread
Manager
Profiling Support
Memory Managers
Building
blocks
Building
blocks
Building
blocks
Connection &
Session
Manager
Concurrency
& Admission
Control
Desugar & Optimize
Small
Memory
Managers
Chunk
Memory
Managers
Spool
Memory
Managers
Linux FS
Cache
Prodder












































![[236] 카카오의데이터파이프라인 윤도영](https://cdn.slidesharecdn.com/ss_thumbnails/236-161025031702-thumbnail.jpg?width=640&height=640&fit=bounds)

























![[코세나, kosena] 빅데이터 구축 및 제안 가이드](https://cdn.slidesharecdn.com/ss_thumbnails/random-161220075637-thumbnail.jpg?width=640&height=640&fit=bounds)


![[AWS Builders] 우리 워크로드에 맞는 데이터베이스 찾기](https://cdn.slidesharecdn.com/ss_thumbnails/awsbuildersaws201webinardatabasejuyeonpark-190306072417-thumbnail.jpg?width=640&height=640&fit=bounds)



![[중소기업형 인공지능/빅데이터 기술 심포지엄] 대용량 거래데이터 분석을 위한 서버인프라 활용 사례](https://cdn.slidesharecdn.com/ss_thumbnails/6-180918045307-thumbnail.jpg?width=640&height=640&fit=bounds)

























