급진적으로 늘어나는 데이터, 점차 다양해지는 워크로드의 특성에 적합한 데이터 관리를 위해 AWS는 광범위한 데이터베이스를 제공합니다. 이번 웨비나에서는 관계형 데이터베이스를 비롯, 인메모리, 그래프, 시계열 등 다양한 어플리케이션에 적합한 데이터베이스를 선택할 수 있도록 AWS의 각 데이터베이스의 개요를 소개합니다.
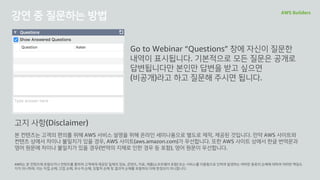
강연 중 질문하는방법 AWS Builders
Go to Webinar “Questions” 창에 자신이 질문한
내역이 표시됩니다. 기본적으로 모든 질문은 공개로
답변됩니다만 본인만 답변을 받고 싶으면
(비공개)라고 하고 질문해 주시면 됩니다.
본 컨텐츠는 고객의 편의를 위해 AWS 서비스 설명을 위해 온라인 세미나용으로 별도로 제작, 제공된 것입니다. 만약 AWS 사이트와
컨텐츠 상에서 차이나 불일치가 있을 경우, AWS 사이트(aws.amazon.com)가 우선합니다. 또한 AWS 사이트 상에서 한글 번역문과
영어 원문에 차이나 불일치가 있을 경우(번역의 지체로 인한 경우 등 포함), 영어 원문이 우선합니다.
AWS는 본 컨텐츠에 포함되거나 컨텐츠를 통하여 고객에게 제공된 일체의 정보, 콘텐츠, 자료, 제품(소프트웨어 포함) 또는 서비스를 이용함으로 인하여 발생하는 여하한 종류의 손해에 대하여 어떠한 책임도
지지 아니하며, 이는 직접 손해, 간접 손해, 부수적 손해, 징벌적 손해 및 결과적 손해를 포함하되 이에 한정되지 아니합니다.
고지 사항(Disclaimer)
3.
• AWS 데이터서비스 포트폴리오
• 관계형 데이터베이스
• NoSQL 데이터베이스
• 시계열 데이터베이스
• 원장 데이터베이스
최신 애플리케이션 특징
•사용자: 1M+
• 데이터 크기: TB–PB–EB
• 서비스 지역: Global
• 성능: Milliseconds–microseconds
• 요청 비율: Millions
• 액세스: Web, Mobile, IoT devices
• 확장성: Up-down, Out-in
• 과금: Pay for what you use
• 개발자 액세스: No assembly required
소셜 미디어차량 호출 미디어 스트리밍 데이팅
6.
AWS의 데이터 서비스포트폴리오
다양한 요구 사항에 따른 폭넓고 기술 집약적인 데이터 서비스
Analytics
QuickSight SageMaker
S3/Glacier
Glue
ETL & Data Catalog
Lake Formation
Data Lakes
Database Migration Service | Snowball | Snowmobile | Kinesis Data Firehose | Kinesis Data Streams
Data Movement
Business Intelligence & Machine Learning
Data Lake
Redshift
Data warehousing
EMR
Hadoop + Spark
Kinesis Data Analytics
Real time
Elasticsearch Service
Operational Analytics
Athena
Interactive analytics
RDS
MySQL, PostgreSQL, MariaDB,
Oracle, SQL Server
Aurora
MySQL, PostgreSQL
DynamoDB
Key value, Document
ElastiCache
Redis, Memcached
Neptune
Graph
Timestream
Time Series
RDS on VMware
QLDB
Ledger Database
Databases
DocumentDB
Document
Amazon Relational DatabaseService (RDS)
가장 많이 선호하는 데이터베이스 엔진을 갖춘 관계형 데이터베이스
가용성 및 내구성
다중AZ를 이용한 동기식 복제,
자동화된 백업, 데이터베이스 스냅샷,
자동 호스팅 교체
빠른 성능과 보안
고성능 OLTP 애플리케이션에
최적화된 SSD 지원 옵션, 저장 및
전송 시 암호화 지원
뛰어난 확장성
마우스 몇 번의 클릭으로도
데이터베이스의 컴퓨팅 및
스토리지 리소스 확장
관리 용이성
하드웨어 프로비저닝, 데이터베이스
설정, 패치 및 백업과 같은 관리
작업을 자동화
9.
Amazon Aurora 특징
클라우드에최적화된 MySQL 및 PostgreSQL 호환성의 관계형 데이터베이스
가용성 및 내구성
내결함성을 갖춘 자가 복구 분산
스토리지 시스템으로 3개의 가용
영역에 걸처 6개의 복사본 유지,
S3로의 지속적인 백업
완전 관리형
하드웨어 프로비저닝, 소프트웨어
패치, 설정, 구성 또는 백업과 같은
데이터베이스 관리 작업에 대해
걱정할 필요 없음
뛰어난 보안
Amazon VPC를 사용한
네트워크 격리, 저장 및
전송 데이터 암호화 등의
보안 기능 제공
성능 및 확장성
표준 MySQL보다 5배, 표준
PostgreSQL보다 3배 빠르며, 최대
15개의 읽기 전용 복제본으로 확장
가능
10.
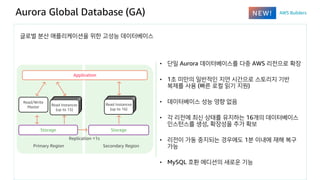
Aurora Global Database(GA)
글로벌 분산 애플리케이션을 위한 고성능 데이터베이스
• 단일 Aurora 데이터베이스를 다중 AWS 리전으로 확장
• 1초 미만의 일반적인 지연 시간으로 스토리지 기반
복제를 사용 (빠른 로컬 읽기 지원)
• 데이터베이스 성능 영향 없음
• 각 리전에 최신 상태를 유지하는 16개의 데이터베이스
인스턴스를 생성, 확장성을 추가 확보
• 리전이 가동 중지되는 경우에도 1분 이내에 재해 복구
가능
• MySQL 호환 에디션의 새로운 기능
Primary Region Secondary Region
Application
Storage Storage
Replication <1s
11.
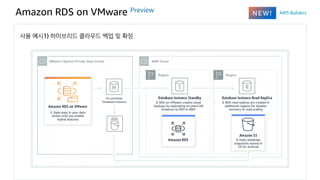
Amazon RDS onVMware Preview
온프레미스 VMware 환경에서 Amazon RDS 데이터베이스 배포
가용성과 내구성
온프레미스 데이터베이스를
Amazon RDS 인스턴스로 복제하여
저렴한 비용의 하이브리드 백업,
재해 복구, 장기 보관 및 특정 시점
복원 수행
보안 및 규정 준수
보안, 개인 정보, 규정 등을 준수하기
위해 회사 내에서 유지되어야 하는
워크로드에 대한 관리 자동화
확장성 및 성능
마우스 몇 번의 클릭으로
온프레미스 데이터베이스의
저장, 컴퓨팅 및 메모리
확장
완전 관리형
온프레미스 데이터 센터에서 관계형
데이터베이스를 쉽게 프로비저닝,
모니터링 및 운영,
AWS로 마이그레이션
12.
Amazon RDS onVMware Preview
사용 예시1) 하이브리드 클라우드 백업 및 확장
13.
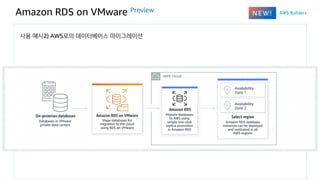
Amazon RDS onVMware Preview
사용 예시2) AWS로의 데이터베이스 마이그레이션
Not Only SQL(NoSQL)
0000 {“Texas”}
0001 {“Illinois”}
0002 {“Oregon”}
TXW
A
I
L
Key
Column
0000-0000-0000-0001
Game Heroes
Version 3.4
CRC ADE4
Key Value
Graph
Document
Column-family
16.
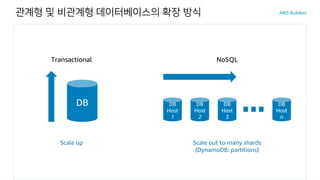
관계형 및 비관계형데이터베이스의 확장 방식
Scale up Scale out to many shards
(DynamoDB: partitions)
DB
DB DB
Host
1
DB
Host
n
DB
Host
2
DB
Host
3
Transactional NoSQL
17.
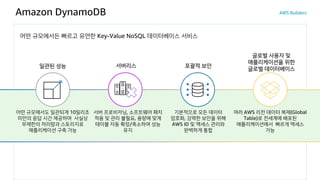
Amazon DynamoDB
어떤 규모에서든빠르고 유연한 Key-Value NoSQL 데이터베이스 서비스
포괄적 보안
기본적으로 모든 데이터
암호화, 강력한 보안을 위해
AWS ID 및 액세스 관리와
완벽하게 통합
일관된 성능
어떤 규모에서도 일관되게 10밀리초
미만의 응답 시간 제공하여 사실상
무제한의 처리량과 스토리지로
애플리케이션 구축 가능
글로벌 사용자 및
애플리케이션을 위한
글로벌 데이터베이스
여러 AWS 리전 데이터 복제(Global
Table)로 전세계에 배포된
애플리케이션에서 빠르게 엑세스
가능
서버리스
서버 프로비저닝, 소프트웨어 패치
적용 및 관리 불필요, 용량에 맞게
테이블 자동 확장/축소하여 성능
유지
DynamoDB-read/write capacity on-demand(GA)
용량계획 없이 초당 수천 개의 요청을 처리할 수 있는 유연한 청구 옵션
용량 계획 불필요
예상되는 읽기/쓰기 처리량을 지정하지
않아도 문제 없음
예기치 않은 부하 증가에 이상적
상황에 따라 0에서 수만의 요청을
처리할 수 있도록 증가 가능
사용한 만큼만 지불
사용한 만큼만 지불하는 간편한 요금제
트랜잭션 처리가 필요한사례
시나리오: 고객이 물건을 구입하는 경우
“PUT”:
“TableName”: “Orders”,
“OrderStatus”: “Sold”,
“Item”: “Bike”,
“Quantity”: “1”
“PUT”:
“TableName”: “Inventory”,
“Item”: “Bike”,
“Quantity”: “- 1”
Transact-write-items
{
“PUT”:
“TableName”: “Orders”,
“OrderStatus”: “Sold”,
“Item”: “Bike”,
“Quantity”: “1”
“PUT”:
“TableName”: “Inventory”,
“Item”: “Bike”,
“Quantity”: “- 1”
}
여기서 실패할 경우, Orders에는
추가하나 Inventory에는 업데이트 안 됨
여기서 실패할 경우 Inventory의 일부만
업데이트 발생
상황에 따라 개발자는 별도의 코드 작성 필요 트랜잭션 지원: 시스템이 알아서 처리
VS.
22.
Amazon DynamoDB Transactions(GA)
ACID 트랜잭션 지원으로 규모에 따른 비즈니스 크리티컬 애플리케이션 구축 가능
간단한 애플리케이션
코드로 ACID 보장
대규모 워크로드에
트랜잭션 지원
레거시 마이그레이션
가속화
23.
Amazon DocumentDB
빠르고 확장가능하며 가용성이 뛰어난 MongoDB 호환 데이터베이스
완전 관리형
하드웨어 프로비저닝, 패치
작업, 설정, 구성 또는 백업과
같은 데이터베이스 관리 작업
자동화
뛰어난 가용성 및 성능
3개의 가용 영역에 걸쳐 6개의
데이터 사본 복제,
손쉽게 노드 추가 가능,
자가 복구 분산 스토리지 시스템,
클러스터당 최대 64TB까지 확장
MongoDB 호환 가능
MongoDB 3.6 API로 구현하여
기존 MongoDB 드라이버 및 도구
사용 가능
높은 보안성
VPC를 통한 네트워크 격리,
저장 및 전송 데이터 암호화 비롯
여러 수준의 보안 제공
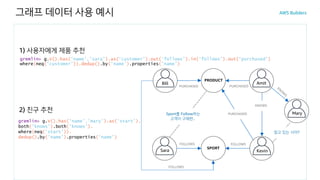
그래프 데이터 사용예시
알고 있는 사이?
Sport를 Follow하는
고객이 구매한..
gremlin> V().has(‘name’,’sara’).as(‘customer’).out(‘follows’).in(‘follows’).out(‘purchased’)
( (‘customer’)).dedup() (‘name’) ('name')
PURCHASED PURCHASED
FOLLOWS
PURCHASED
KNOWS
PRODUCT
SPORT
FOLLOWS
FOLLOWS
2) 친구 추천
gremlin> g.V().has('name','mary').as(‘start’).
both('knows').both('knows’).
where(neq(‘start’)).
dedup().by('name').properties('name')
1) 사용자에게 제품 추천
27.
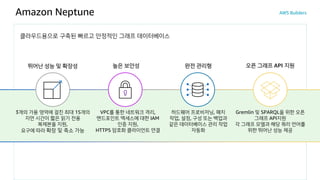
Amazon Neptune
클라우드용으로 구축된빠르고 안정적인 그래프 데이터베이스
완전 관리형
하드웨어 프로비저닝, 패치
작업, 설정, 구성 또는 백업과
같은 데이터베이스 관리 작업
자동화
뛰어난 성능 및 확장성
3개의 가용 영역에 걸친 최대 15개의
지연 시간이 짧은 읽기 전용
복제본을 지원,
요구에 따라 확장 및 축소 가능
오픈 그래프 API 지원
Gremlin 및 SPARQL을 위한 오픈
그래프 API지원
각 그래프 모델과 해당 쿼리 언어를
위한 뛰어난 성능 제공
높은 보안성
VPC를 통한 네트워크 격리,
엔드포인트 액세스에 대한 IAM
인증 지원,
HTTPS 암호화 클라이언트 연결
시계열 데이터
시간 간격을두고 기록되는
일련의 데이터
시간이
데이터 모델의 주요 축
• 시계열 데이터는 어떤 것인가?
• 시계열 데이터의 특징은 무엇인가?
31.
시계열 데이터의 예시
IoT센서 데이터
데브옵스 데이터
Humidity
% WATER VAPOR
91.094.086.093.0
애플리케이션 데이터
32.
시계열: 가장 빠르게성장하는 데이터베이스 영역
https://db-engines.com/
https://www.influxdata.com/time-series-database/
33.
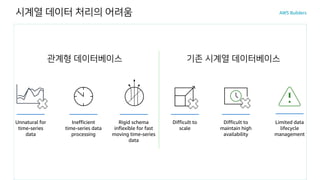
시계열 데이터 처리의어려움
기존 시계열 데이터베이스관계형 데이터베이스
Difficult to
maintain high
availability
Difficult to
scale
Limited data
lifecycle
management
Inefficient
time-series data
processing
Unnatural for
time-series
data
Rigid schema
inflexible for fast
moving time-series
data
34.
Amazon Timestream Preview
빠르고확장 가능한 완전관리형 시계열 데이터베이스
1/10의 비용으로 1000배 빠른 속도
초당 수백만 개의 데이터를
처리할 수 있는 속도
(10M/second)
시간 간격에 따라 구성된
데이터는 시계열 검색에
최적화, 별도 처리 계층에서
삽입 및 쿼리를 실행하기 하여
리소스 경합 없어 성능 향상
시계열 분석
시계열 분석에 필요한
함수(interpolation,
smoothing, approximation)
기본 탑재
서버리스
서버 프로비저닝, 소프트웨어 패치,
설정, 구성의 자동화
자동으로 확장 또는 축소되면서
용량 및 성능을 조절
원장 처리의 어려움
불필요한복잡성
추가
블록체인RDBMS – 감사 테이블
유지 관리의
어려움
사용이 어렵고
느리다
구축의 어려움
트리거 혹은 저장 프로시저를
이용한 사용자 정의 감사 기능 구현
필요
검증의 어려움
sysadmins에 의해 변경된
데이터를 확인할 방법이 없음
38.
Amazon Quantum LedgerDatabase (QLDB) Preview
투명하고 변경 불가능하며 암호화 방식으로 검증 가능한 트랜잭션 로그를 제공하는 완전관리형 원장 데이터베이스
변경 불가능 및 투명성
각 애플리케이션 데이터의 변경 사항
추적 가능, 시간이 지나도 순차적인
모든 변경 내역을 유지 관리하는
저널 사용, 저널의 데이터는 삭제
또는 수정 불가
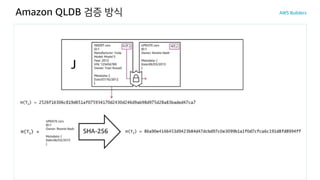
암호화 방식으로 검증 가능
암호화 해시 함수(SHA-
256)를 사용하여 데이터
변경 내역에 대한 보안 출력
파일을 생성하여 이를 통해
데이터 변경의 무결성 검증
사용 편의성
SQL과 비슷한 API에서 익숙한
SQL 연산자를 이용, 데이터
조회 및 변경 가능
뛰어난 확장성
일반적인 블록체인
프레임워크에서 원장보다
2~3배 더 많은 트랜잭션 실행
가능
39.
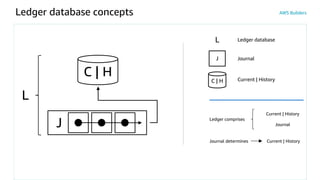
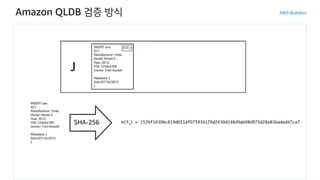
Ledger database concepts
C| H
J Journal
C | H Current | History
Current | History
Journal
Ledger comprises
J
L
Ledger databaseL
Journal determines Current | History
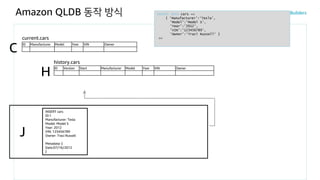
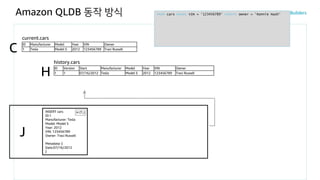
Amazon QLDB 동작방식
ID Manufacturer Model Year VIN Owner
ID Version Start Manufacturer Model Year VIN Owner
J
history.cars
H
current.cars
C
42.
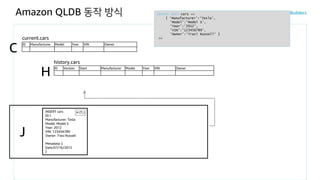
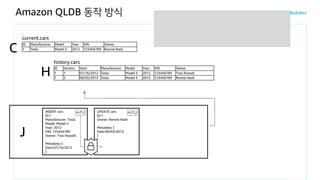
Amazon QLDB 동작방식
ID Manufacturer Model Year VIN Owner
ID Version Start Manufacturer Model Year VIN Owner
J
history.cars
H
INSERT INTO cars <<
{ 'Manufacturer':'Tesla',
'Model':'Model S',
'Year':'2012',
'VIN':'123456789',
'Owner':'Traci Russell' }
>>current.cars
C
43.
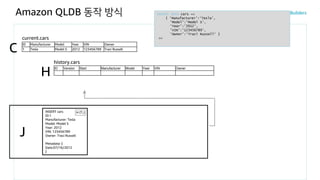
Amazon QLDB 동작방식
ID Manufacturer Model Year VIN Owner
ID Version Start Manufacturer Model Year VIN Owner
J
history.cars
H
INSERT INTO cars <<
{ 'Manufacturer':'Tesla',
'Model':'Model S',
'Year':'2012',
'VIN':'123456789',
'Owner':'Traci Russell' }
>>current.cars
C
INSERT cars
ID:1
Manufacturer: Tesla
Model: Model S
Year: 2012
VIN: 123456789
Owner: Traci Russell
Metadata: {
Date:07/16/2012
}
44.
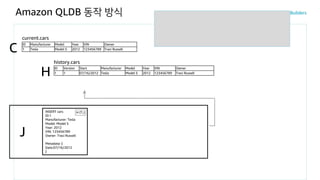
Amazon QLDB 동작방식
ID Manufacturer Model Year VIN Owner
ID Version Start Manufacturer Model Year VIN Owner
J
history.cars
H
INSERT INTO cars <<
{ 'Manufacturer':'Tesla',
'Model':'Model S',
'Year':'2012',
'VIN':'123456789',
'Owner':'Traci Russell' }
>>current.cars
C
INSERT cars
ID:1
Manufacturer: Tesla
Model: Model S
Year: 2012
VIN: 123456789
Owner: Traci Russell
Metadata: {
Date:07/16/2012
}
H (T1)
45.
Amazon QLDB 동작방식
ID Version Start Manufacturer Model Year VIN Owner
J
history.cars
H
INSERT INTO cars <<
{ 'Manufacturer':'Tesla',
'Model':'Model S',
'Year':'2012',
'VIN':'123456789',
'Owner':'Traci Russell' }
>>current.cars
C
INSERT cars
ID:1
Manufacturer: Tesla
Model: Model S
Year: 2012
VIN: 123456789
Owner: Traci Russell
Metadata: {
Date:07/16/2012
}
H (T1)
ID Manufacturer Model Year VIN Owner
1 Tesla Model S 2012 123456789 Traci Russell
46.
Amazon QLDB 동작방식
J
history.cars
H
INSERT INTO cars <<
{ 'Manufacturer':'Tesla',
'Model':'Model S',
'Year':'2012',
'VIN':'123456789',
'Owner':'Traci Russell' }
>>current.cars
C
INSERT cars
ID:1
Manufacturer: Tesla
Model: Model S
Year: 2012
VIN: 123456789
Owner: Traci Russell
Metadata: {
Date:07/16/2012
}
H (T1)
ID Manufacturer Model Year VIN Owner
1 Tesla Model S 2012 123456789 Traci Russell
ID Version Start Manufacturer Model Year VIN Owner
1 1 07/16/2012 Tesla Model S 2012 123456789 Traci Russell
47.
Amazon QLDB 동작방식
J
history.cars
H
current.cars
C
INSERT cars
ID:1
Manufacturer: Tesla
Model: Model S
Year: 2012
VIN: 123456789
Owner: Traci Russell
Metadata: {
Date:07/16/2012
}
H (T1)
ID Manufacturer Model Year VIN Owner
1 Tesla Model S 2012 123456789 Traci Russell
ID Version Start Manufacturer Model Year VIN Owner
1 1 07/16/2012 Tesla Model S 2012 123456789 Traci Russell
48.
Amazon QLDB 동작방식
J
history.cars
H
current.cars
C
INSERT cars
ID:1
Manufacturer: Tesla
Model: Model S
Year: 2012
VIN: 123456789
Owner: Traci Russell
Metadata: {
Date:07/16/2012
}
H (T1)
ID Manufacturer Model Year VIN Owner
1 Tesla Model S 2012 123456789 Traci Russell
ID Version Start Manufacturer Model Year VIN Owner
1 1 07/16/2012 Tesla Model S 2012 123456789 Traci Russell
FROM cars WHERE VIN = '123456789' UPDATE owner = 'Ronnie Nash'
49.
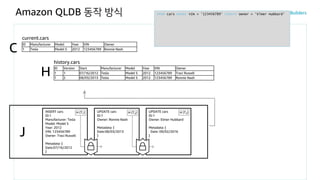
Amazon QLDB 동작방식
J
history.cars
H
current.cars
C
INSERT cars
ID:1
Manufacturer: Tesla
Model: Model S
Year: 2012
VIN: 123456789
Owner: Traci Russell
Metadata: {
Date:07/16/2012
}
H (T1)
ID Manufacturer Model Year VIN Owner
1 Tesla Model S 2012 123456789 Traci Russell
ID Version Start Manufacturer Model Year VIN Owner
1 1 07/16/2012 Tesla Model S 2012 123456789 Traci Russell
FROM cars WHERE VIN = '123456789' UPDATE owner = 'Ronnie Nash'
UPDATE cars
ID:1
Owner: Ronnie Nash
Metadata: {
Date:08/03/2013
}
H (T2)
50.
Amazon QLDB 동작방식
J
history.cars
H
current.cars
C
INSERT cars
ID:1
Manufacturer: Tesla
Model: Model S
Year: 2012
VIN: 123456789
Owner: Traci Russell
Metadata: {
Date:07/16/2012
}
H (T1)
ID Manufacturer Model Year VIN Owner
1 Tesla Model S 2012 123456789 Traci Russell
ID Version Start Manufacturer Model Year VIN Owner
1 1 07/16/2012 Tesla Model S 2012 123456789 Traci Russell
FROM cars WHERE VIN = '123456789' UPDATE owner = 'Ronnie Nash'
UPDATE cars
ID:1
Owner: Ronnie Nash
Metadata: {
Date:08/03/2013
}
H (T2)
51.
Amazon QLDB 동작방식
J
history.cars
H
current.cars
C
INSERT cars
ID:1
Manufacturer: Tesla
Model: Model S
Year: 2012
VIN: 123456789
Owner: Traci Russell
Metadata: {
Date:07/16/2012
}
H (T1)
ID Manufacturer Model Year VIN Owner
1 Tesla Model S 2012 123456789 Ronnie Nash
ID Version Start Manufacturer Model Year VIN Owner
1 1 07/16/2012 Tesla Model S 2012 123456789 Traci Russell
FROM cars WHERE VIN = '123456789' UPDATE owner = 'Ronnie Nash'
UPDATE cars
ID:1
Owner: Ronnie Nash
Metadata: {
Date:08/03/2013
}
H (T2)
52.
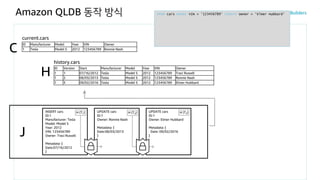
Amazon QLDB 동작방식
J
history.cars
H
current.cars
C
INSERT cars
ID:1
Manufacturer: Tesla
Model: Model S
Year: 2012
VIN: 123456789
Owner: Traci Russell
Metadata: {
Date:07/16/2012
}
H (T1)
ID Manufacturer Model Year VIN Owner
1 Tesla Model S 2012 123456789 Ronnie Nash
ID Version Start Manufacturer Model Year VIN Owner
1 1 07/16/2012 Tesla Model S 2012 123456789 Traci Russell
1 2 08/03/2013 Tesla Model S 2012 123456789 Ronnie Nash
FROM cars WHERE VIN = '123456789' UPDATE owner = 'Ronnie Nash'
UPDATE cars
ID:1
Owner: Ronnie Nash
Metadata: {
Date:08/03/2013
}
H (T2)
53.
Amazon QLDB 동작방식
J
history.cars
H
current.cars
C
INSERT cars
ID:1
Manufacturer: Tesla
Model: Model S
Year: 2012
VIN: 123456789
Owner: Traci Russell
Metadata: {
Date:07/16/2012
}
H (T1)
ID Manufacturer Model Year VIN Owner
1 Tesla Model S 2012 123456789 Ronnie Nash
ID Version Start Manufacturer Model Year VIN Owner
1 1 07/16/2012 Tesla Model S 2012 123456789 Traci Russell
1 2 08/03/2013 Tesla Model S 2012 123456789 Ronnie Nash
UPDATE cars
ID:1
Owner: Ronnie Nash
Metadata: {
Date:08/03/2013
}
H (T2)
54.
Amazon QLDB 동작방식
J
history.cars
H
current.cars
C
INSERT cars
ID:1
Manufacturer: Tesla
Model: Model S
Year: 2012
VIN: 123456789
Owner: Traci Russell
Metadata: {
Date:07/16/2012
}
H (T1)
ID Manufacturer Model Year VIN Owner
1 Tesla Model S 2012 123456789 Ronnie Nash
ID Version Start Manufacturer Model Year VIN Owner
1 1 07/16/2012 Tesla Model S 2012 123456789 Traci Russell
1 2 08/03/2013 Tesla Model S 2012 123456789 Ronnie Nash
UPDATE cars
ID:1
Owner: Ronnie Nash
Metadata: {
Date:08/03/2013
}
H (T2)
FROM cars WHERE VIN = '123456789' UPDATE owner = 'Elmer Hubbard'
55.
Amazon QLDB 동작방식
J
history.cars
H
current.cars
C
INSERT cars
ID:1
Manufacturer: Tesla
Model: Model S
Year: 2012
VIN: 123456789
Owner: Traci Russell
Metadata: {
Date:07/16/2012
}
H (T1)
ID Manufacturer Model Year VIN Owner
1 Tesla Model S 2012 123456789 Ronnie Nash
ID Version Start Manufacturer Model Year VIN Owner
1 1 07/16/2012 Tesla Model S 2012 123456789 Traci Russell
1 2 08/03/2013 Tesla Model S 2012 123456789 Ronnie Nash
UPDATE cars
ID:1
Owner: Ronnie Nash
Metadata: {
Date:08/03/2013
}
H (T2)
FROM cars WHERE VIN = '123456789' UPDATE owner = 'Elmer Hubbard'
UPDATE cars
ID:1
Owner: Elmer Hubbard
Metadata: {
Date: 09/02/2016
}
H (T3)
56.
Amazon QLDB 동작방식
J
history.cars
H
current.cars
C
INSERT cars
ID:1
Manufacturer: Tesla
Model: Model S
Year: 2012
VIN: 123456789
Owner: Traci Russell
Metadata: {
Date:07/16/2012
}
H (T1)
ID Manufacturer Model Year VIN Owner
1 Tesla Model S 2012 123456789 Ronnie Nash
ID Version Start Manufacturer Model Year VIN Owner
1 1 07/16/2012 Tesla Model S 2012 123456789 Traci Russell
1 2 08/03/2013 Tesla Model S 2012 123456789 Ronnie Nash
1 3 09/02/2016 Tesla Model S 2012 123456789 Elmer Hubbard
UPDATE cars
ID:1
Owner: Ronnie Nash
Metadata: {
Date:08/03/2013
}
H (T2)
FROM cars WHERE VIN = '123456789' UPDATE owner = 'Elmer Hubbard'
UPDATE cars
ID:1
Owner: Elmer Hubbard
Metadata: {
Date: 09/02/2016
}
H (T3)
57.
Amazon QLDB 조회
TraditionalSQL QLDB
SELECT *
FROM orders AS o, addresses AS a
WHERE a.state = ‘WA’
AND o.shipping_address_id = a.id
SELECT *
FROM orders AS o
WHERE o.shipping_address.state = ‘WA’
예) 워싱턴 주에서 출발한 모든 오더 찾기
Amazon QLDB 사용사례
중앙집중식 통제 기능을 갖춘 원장 관리가 필요한 경우
보험
전체 트랜잭션 내의 클레임
내역을 정확히 유지 관리
애플리케이션이 데이터 입력
오류 및 조작에 대해 복원성
확보
제조
제품 리콜이 발생할 경우
제품의 전체 생산 및 유통
수명 주기 내역을 쉽게 추적
HR 및 급여
급여, 보너스, 수당, 실적 및
보험과 같은 직원 세부
정보에 대한 레코드를
추적하고 유지
정부 기관
차량 이력 조회
일반적인 데이터 서비스분류 및 사례
Relational
데이터의 무결성
및 트랜잭션 보장
스키마 보장
기존 워크로드
마이그레이션,
ERP 및 CRM
Key-value
높은 처리량, 최소
지연 보장,
유연한 확장
실시간 입찰,
장바구니, SNS,
제품 카탈로그,
고객 정보 설정
Document
문서의 저장 및
모든 속성에 대한
빠른 쿼리 요구
컨텐츠 관리,
모바일,
개인화
In-memory
키를 기반으로 한
마이크로 초
이내의 응답 요구
리더보드,
실시간 분석,
캐싱
Graph
데이터 간
신속하고 간편한
관계 구축 및
탐색
사기 탐지,
소셜 네트워킹,
추천 엔진
Time-series
시간에 따라
데이터 수집,
저장, 처리
IoT 애플리케이션,
이벤트 추척
Ledger
응용프로그램 내
모든 데이터 변경에
대한 완전하고 변경
불가능한 기록 관리
물류배송, 헬스케어,
등록 및 금융과 관련한
시스템
64.
AWS 데이터베이스 서비스
애플리케이션요구사항에 맞는 개별 데이터베이스 선택
Relational Key-value Document In-memory Graph Time-series Ledger
RDS
Aurora CommercialCommunity
DynamoDB DocumentDB ElastiCache Neptune Timestream QLDB
65.
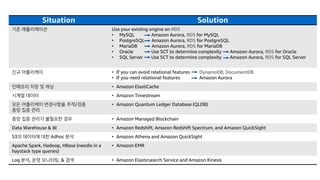
Situation Solution
기존 애플리케이션Use your existing engine on RDS
• MySQL Amazon Aurora, RDS for MySQL
• PostgreSQL Amazon Aurora, RDS for PostgreSQL
• MariaDB Amazon Aurora, RDS for MariaDB
• Oracle Use SCT to determine complexity Amazon Aurora, RDS for Oracle
• SQL Server Use SCT to determine complexity Amazon Aurora, RDS for SQL Server
신규 어플리케이 • If you can avoid relational features DynamoDB, DocumentDB
• If you need relational features Amazon Aurora
인메모리 저장 및 캐싱 • Amazon ElastiCache
시계열 데이터 • Amazon Timestream
모든 어플리케이 변경사항을 추적/검증
중앙 집중 관리
• Amazon Quantum Ledger Database (QLDB)
중앙 집중 관리가 불필요한 경우 • Amazon Managed Blockchain
Data Warehouse & BI • Amazon Redshift, Amazon Redshift Spectrum, and Amazon QuickSight
S3의 데이터에 대한 Adhoc 분석 • Amazon Athena and Amazon QuickSight
Apache Spark, Hadoop, HBase (needle in a
haystack type queries)
• Amazon EMR
Log 분석, 운영 모니터링, & 검색 • Amazon Elasticsearch Service and Amazon Kinesis
66.
더 나은 세미나를위해
여러분의 의견을 남겨주세요!
▶ 질문에 대한 답변 드립니다.
▶ 발표자료/녹화영상을 제공합니다.
http://bit.ly/awskr-webinar



















































![[Games on AWS 2019] AWS 사용자를 위한 만랩 달성 트랙 | Aurora로 게임 데이터베이스 레벨 업! - 김병수 AWS ...](https://cdn.slidesharecdn.com/ss_thumbnails/gamesonaws2019levelupyourgamedatabasewithaurora-191015003557-thumbnail.jpg?width=640&height=640&fit=bounds)
![[AWS Builders] 클라우드 비용, 어떻게 줄일 수 있을까?](https://cdn.slidesharecdn.com/ss_thumbnails/awsbuildersaws101webinarcloudeconomicsbonminkoo-190305081315-thumbnail.jpg?width=640&height=640&fit=bounds)





![[AWS Builders] AWS와 함께하는 클라우드 컴퓨팅](https://cdn.slidesharecdn.com/ss_thumbnails/awsbuildersaws101webinarcloudcomputingchoelkang-190305081301-thumbnail.jpg?width=640&height=640&fit=bounds)



![[2017 AWS Startup Day] 스타트업이 인공지능을 만날 때 : 딥러닝 활용사례와 아키텍쳐](https://cdn.slidesharecdn.com/ss_thumbnails/20171102awsstartupday2017-with-171102040932-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2017 Gaming on AWS] Serverless로 게임 서비스 구현하기](https://cdn.slidesharecdn.com/ss_thumbnails/gamingonawsserverlessholprint1-171030024709-thumbnail.jpg?width=640&height=640&fit=bounds)



![[AWS Builders] AWS 스토리지 서비스 소개 및 사용 방법](https://cdn.slidesharecdn.com/ss_thumbnails/awsbuilders200storageservice-190611112205-thumbnail.jpg?width=640&height=640&fit=bounds)

![[AWS Builders 온라인 시리즈] AWS 서비스를 활용하여 파일 스토리지 빠르게 마이그레이션 하기 - 서지혜, AWS 솔루션즈 아키텍트](https://cdn.slidesharecdn.com/ss_thumbnails/jihye-200313041912-thumbnail.jpg?width=640&height=640&fit=bounds)







![[Games on AWS 2019] AWS 입문자를 위한 초단기 레벨업 트랙 | AWS 레벨업 하기! : 데이터베이스 - 박주연 AWS 솔...](https://cdn.slidesharecdn.com/ss_thumbnails/04gamesonawsawsdatabase-191014082829-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Keynote] 슬기로운 AWS 데이터베이스 선택하기 - 발표자: 강민석, Korea Database SA Manager, WWSO, A...](https://cdn.slidesharecdn.com/ss_thumbnails/d3s01aws-230704014400-3eeae447-thumbnail.jpg?width=640&height=640&fit=bounds)







![[Retail & CPG Day 2019] Amazon.com의 무중단, 대용량 DB패턴과 국내사례 (Lotte e-commerce) - ...](https://cdn.slidesharecdn.com/ss_thumbnails/200-1-191024053915-thumbnail.jpg?width=640&height=640&fit=bounds)














![[D3T1S05] Aurora 혼합 구성 아키텍처를 사용하여 예상치 못한 트래픽 급증 대응하기](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s05aurora-240702042911-c7f3f22d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S04] Aurora PostgreSQL performance monitoring and troubleshooting by use...](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s04aurorapostgresqlperformancemonitoringandtroubleshooting-240702042912-5df626e3-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T2S01] Amazon Aurora MySQL 메이저 버전 업그레이드 및 Amazon B/G Deployments 실습](https://cdn.slidesharecdn.com/ss_thumbnails/d3t2s01amazonaurorabluegreendeployment-240702042226-3ae36566-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S01] Gen AI를 위한 Amazon Aurora 활용 사례 방법](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s01genaiamazonaurora-240702042912-516e67f4-thumbnail.jpg?width=640&height=640&fit=bounds)


![[D3T1S07] AWS S3 - 클라우드 환경에서 데이터베이스 보호하기](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s07-240702042911-cb134cd6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T2S03] Data&AI Roadshow 2024 - Amazon DocumentDB 실습](https://cdn.slidesharecdn.com/ss_thumbnails/d3t2s03documentdbhandson-240702042224-047bbc2c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S06] Neptune Analytics with Vector Similarity Search](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s06neptuneanalyticsvectorsilimliaritysearch-240702042912-94c41309-thumbnail.jpg?width=640&height=640&fit=bounds)

![[D3T1S02] Aurora Limitless Database Introduction](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s02auroralimitlessdatabaseintroduction-240702042911-cb5552b7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S03] Amazon DynamoDB design puzzlers](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s03amazondynamodbdesignpuzzlers-240702042912-ad6df881-thumbnail.jpg?width=640&height=640&fit=bounds)