CONTENTS
2
인공지능 – 빅데이터연구센터 사용 배경인공지능 – 빅데이터 연구센터 사용 배경
1
분석 시스템분석 시스템
2
클러스터 관리클러스터 관리
3
사용 예시사용 예시
4
3.
SCP 소개
3
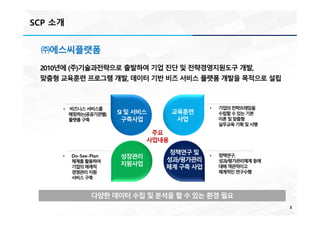
㈜에스씨플랫폼
2010년에 (주)기술과전략으로출발하여 기업 진단 및 전략경영지원도구 개발,
맞춤형 교육훈련 프로그램 개발, 데이터 기반 비즈 서비스 플랫폼 개발을 목적으로 설립
교육훈련
사업
정책연구 및
성과/평가관리
체계 구축 사업
• 비즈니스서비스를
매칭하는(공공기관별)
플랫폼구축
• 기업의전략프레임을
수립할수있는기본
이론및맞춤형
실무교육기획및시행
• 정책연구,
성과/평가관리체계등에
대해객관적이고
체계적인연구수행
• Do-See-Plan
체계를활용하여
기업의체계적
경영관리지원
서비스구축
주요
사업내용
SI 및 서비스
구축사업
성장관리
지원사업
다양한 데이터 수집 및 분석을 할 수 있는 환경 필요
4.
4
수집 자동화 시스템/ 분석 시스템 구축
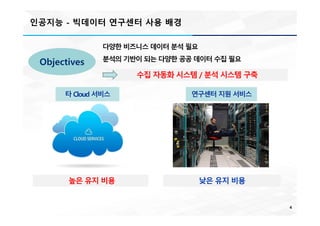
다양한 비즈니스 데이터 분석 필요
분석의 기반이 되는 다양한 공공 데이터 수집 필요
Objectives
타 Cloud 서비스 연구센터 지원 서비스
높은 유지 비용 낮은 유지 비용
인공지능 - 빅데이터 연구센터 사용 배경
5.
분석 시스템
5
기존 기술로처리시 많은 비용 발생
빅데이터
(Big Data)
q 데이터 분석 이슈
q 다수의 사용자들이 RDBMS 의존 분석 수행: 서버 비용
q RDBMS 라이선스 문제: 라이선스 비용
q TB급 데이터 EDA(탐색적 자료 분석) / ML(머신 러닝) 어려움: 시간 비용
성능향상
Scale-out
• 다수의사용자사용
(2018년9월3일기준
분석팀12명)
• 기존분석프로세스
보다빠르고효율적인
분석
• 서버수의증가에따른
성능향상
• 서버이용자의
원할한서버사용
서버 분석
환경
자원관리
낮은
학습곡선
6.
분석 시스템 -Scale-up & Scale out
6
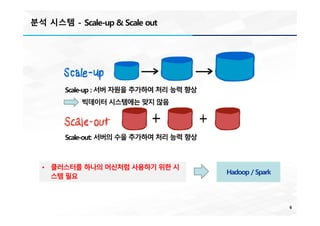
Scale-up : 서버 자원을 추가하여 처리 능력 향상
빅데이터 시스템에는 맞지 않음
Scale-out: 서버의 수을 추가하여 처리 능력 향상
• 클러스터를 하나의 머신처럼 사용하기 위한 시
스템 필요
Hadoop / Spark
7.
분석 시스템 -Apache Hadoop, Redis
7
q Yarn
q Resource Manager: 클러스터 전체의 자원 관리
q Node Manager: 서버 각각의 자원 관리
q hdfs
q 읽기, 쓰기, 삭제만 가능
q Datanode: 다중(일반적으로 3중) 분산 저장
q Namenode: 파일 저장 위치 관리
q 데이터가 있는 곳으로 코드 전송 후 분석
q Hadoop은 HA(high availability) 구성
q SPOF(Single point of failure) 회피
q Redis
q 매우 빠른 Read/Write 보장
8.
분석 시스템 -Spark
8
q Spark
q 빅데이터 분석을 위한 대표적인 프레임워크
q 데이터 분석에 드는 비용이 세계에서 가장 적음
q 자사 Benchmark 기준: RDBMS 5시간 à
Apache Spark 10분
q 1/30의 시간
q 낮은 학습 곡선
q SQL, Python, Java, Scala, R
q 세계적으로 많은 사용자: Stack overflow
q 다수의 선도적인 기업이 사용
q 페이스북, 넷플릭스, SKT 외 다수
Facebook Latency Test
[Spark 도입 전후 분석 시간 차이]
9.
클러스터 관리
9
클러스터 관리시스템 필요
Hadoop 기반 아키텍쳐 도입으로 분석 속도 향상 / 서버 부하 분산
Objectives
Nagios Netdata
• 비 정상적인 상황을 자동으로 인지 / 경고
• 이메일 / 메신저(슬랙)를 통한 경고 전달
• 실시간 자원 사용률 모니터링
• 시스템 자원 사용률을 실시간으로 확인할 수 있어야 함
• 시스템 health (정상 작동 여부) 실시간 체크 및 비정상 상황에 대한 경고
10.
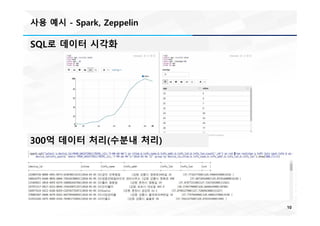
사용 예시 -Spark, Zeppelin
10
SQL로 데이터 시각화
300억 데이터 처리(수분내 처리)
11.
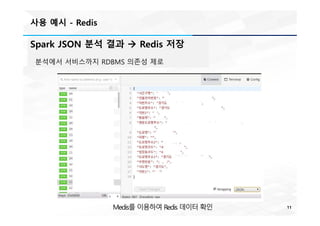
사용 예시 -Redis
11
Spark JSON 분석 결과 à Redis 저장
분석에서 서비스까지 RDBMS 의존성 제로
Medis를 이용하여 Redis 데이터 확인
12.
인공지능 - 빅데이터연구센터 이용 성과
12
오픈 소스 기반
분석 클러스터 구축
→
타 클라우드 대비
비용 절감
분석 자원 증가
→
분석 - 서비스 개발 기간
단축
대용량빅데이터분석에들어가는시간감소
21
인공지능 – 빅데이터 연구센터 도입 후의 성과?
Q




![분석 시스템 - Spark
8
q Spark
q 빅데이터 분석을 위한 대표적인 프레임워크
q 데이터 분석에 드는 비용이 세계에서 가장 적음
q 자사 Benchmark 기준: RDBMS 5시간 à
Apache Spark 10분
q 1/30의 시간
q 낮은 학습 곡선
q SQL, Python, Java, Scala, R
q 세계적으로 많은 사용자: Stack overflow
q 다수의 선도적인 기업이 사용
q 페이스북, 넷플릭스, SKT 외 다수
Facebook Latency Test
[Spark 도입 전후 분석 시간 차이]](https://image.slidesharecdn.com/6-180918045307/85/slide-8-320.jpg)

![[중소기업형 인공지능/빅데이터 기술 심포지엄] 데이터 전처리 기법 및 도구](https://cdn.slidesharecdn.com/ss_thumbnails/2-180918044401-thumbnail.jpg?width=640&height=640&fit=bounds)







![인공지능-빅데이터연구센터[ABRC] 산학협력사례집](https://cdn.slidesharecdn.com/ss_thumbnails/random-171113042049-thumbnail.jpg?width=640&height=640&fit=bounds)








![[2016 데이터 그랜드 컨퍼런스] 5 4(보안,품질). 비투엔 4차산업혁명의성공 데이터품질](https://cdn.slidesharecdn.com/ss_thumbnails/5-4-161125005133-thumbnail.jpg?width=640&height=640&fit=bounds)



![[경북] I'mcloud opensight](https://cdn.slidesharecdn.com/ss_thumbnails/imcloudopensight-151105092004-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)





![[경북] I'mcloud information](https://cdn.slidesharecdn.com/ss_thumbnails/imcloudinformation-151105091525-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)



![[코세나, kosena] 빅데이터 구축 및 제안 가이드](https://cdn.slidesharecdn.com/ss_thumbnails/random-161220075637-thumbnail.jpg?width=640&height=640&fit=bounds)











![[Bespin Global 파트너 세션] 분산 데이터 통합 (Data Lake) 기반의 데이터 분석 환경 구축 사례 - 베스핀 글로벌 장익...](https://cdn.slidesharecdn.com/ss_thumbnails/session5-datalakebaseddataanalyticsenvironmentimplementationcaseexamplebespinglobal-190903082707-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DDC 2018] Metatron 오픈소스화 및 생태계 구축 (SKT 이정룡, 김지호)](https://cdn.slidesharecdn.com/ss_thumbnails/ddc2018session1-181126012837-thumbnail.jpg?width=640&height=640&fit=bounds)

![[2018 Bigdata win-win conference] 4](https://cdn.slidesharecdn.com/ss_thumbnails/4-181127005320-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018 Bigdata win-win conference] 5](https://cdn.slidesharecdn.com/ss_thumbnails/bigdatawin-winconference5-181126075632-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018 Bigdata win-win conference] 3](https://cdn.slidesharecdn.com/ss_thumbnails/bigdatawin-winconference3-181126075308-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018 Bigdata win-win conference] 2](https://cdn.slidesharecdn.com/ss_thumbnails/bigdatawin-winconference2-181126075214-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018 Bigdata win win conference] 1](https://cdn.slidesharecdn.com/ss_thumbnails/bigdatawin-winconference1-181126075052-thumbnail.jpg?width=640&height=640&fit=bounds)
![[중소기업형 인공지능/빅데이터 기술 심포지엄] 온라인 고객 리뷰 빅데이터 신뢰도,방향성 분석 시스템](https://cdn.slidesharecdn.com/ss_thumbnails/7-180918045439-thumbnail.jpg?width=640&height=640&fit=bounds)
![[중소기업형 인공지능/빅데이터 기술 심포지엄] 머신러닝 기반 군 전력장비 수리부속/장비수요 예측시스템](https://cdn.slidesharecdn.com/ss_thumbnails/5-180918045000-thumbnail.jpg?width=640&height=640&fit=bounds)
![[중소기업형 인공지능/빅데이터 기술 심포지엄] LSTM기반 가스 배관 안전도 예측 시스템](https://cdn.slidesharecdn.com/ss_thumbnails/4-180918044844-thumbnail.jpg?width=640&height=640&fit=bounds)
![[중소기업형 인공지능/빅데이터 기술 심포지엄] 워드벡터를 활용한 관광지 리뷰 분석시스템](https://cdn.slidesharecdn.com/ss_thumbnails/3-180918044635-thumbnail.jpg?width=640&height=640&fit=bounds)
![[중소기업형 인공지능/빅데이터 기술 심포지엄] 국내 인공지능-빅데이터 산업의 문제점 및 해결방안](https://cdn.slidesharecdn.com/ss_thumbnails/1-180918043612-thumbnail.jpg?width=640&height=640&fit=bounds)




