Download as PDF, PPTX






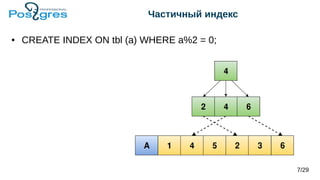

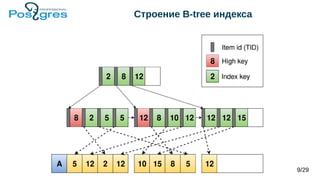

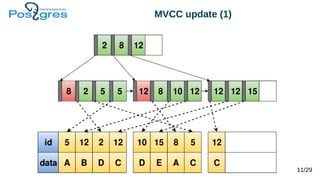

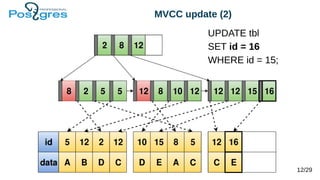

















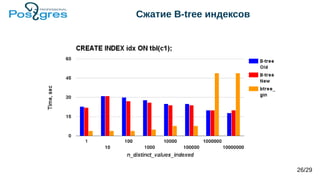




Документ обсуждает архитектуру и новые возможности b-tree индексов в PostgreSQL, включая их использование для ускорения запросов, поддержание целостности данных и методы оптимизации. Рассматриваются различные типы индексов, такие как уникальные, составные, частичные и индексы по выражению, а также их влияние на производительность операций вставки и обновления. Также представлены новые функции, включая индексы с включенными столбцами и техники сжатия индексов.









































































