Download to read offline




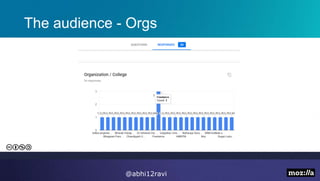
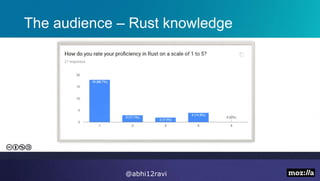
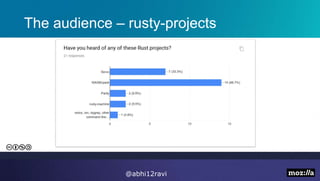



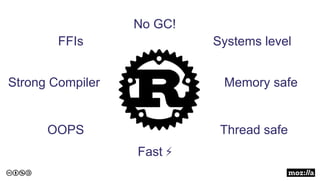











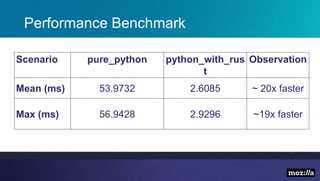




The presentation introduces Rust, highlighting its memory safety, speed, and thread safety. It discusses Rust features like ownership and borrowing for memory management. Examples are given of C++ problems like dangling pointers that Rust prevents. The speaker then demonstrates using Rust for string processing and shows it provides a 20x performance improvement over Python. The presentation concludes that Rust is well-suited for systems programming and innovation due to its speed.



































































