Download as PDF, PPTX

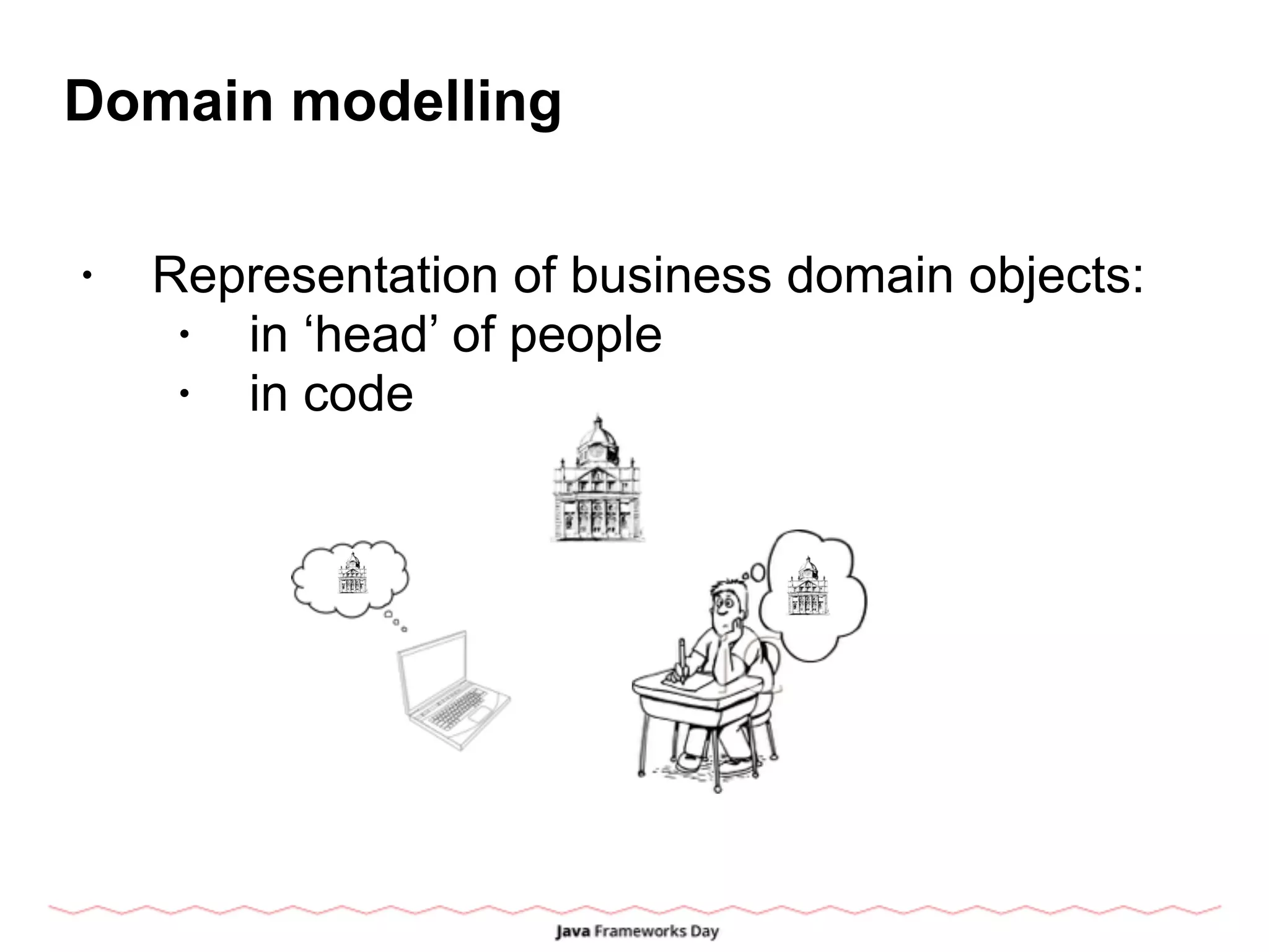

![Domain modelling
• Traditional OO way: have layer of classes,
which corresponds to domain objects.
• Extensibility via inheritance in some
consistent Universal Ontology
• Intensional Equality [identity != attribute]
• Object instance <=> Entity in real world](https://image.slidesharecdn.com/ruslan-150307054551-conversion-gate01/75/Behind-OOD-domain-modelling-in-post-OO-world-4-2048.jpg)



![Traditional OO WAY
• Intensional Equality [ mutability ]
// same identity thought lifecycle](https://image.slidesharecdn.com/ruslan-150307054551-conversion-gate01/75/Behind-OOD-domain-modelling-in-post-OO-world-8-2048.jpg)

![Domain modelling
• Traditional OO way: have layer of classes,
which corresponds to domain objects.
• Extensibility via inheritance in some
consistent Universal Ontology
• Intensional Equality [identity != attribute]
• Object instance <=> Entity in real world](https://image.slidesharecdn.com/ruslan-150307054551-conversion-gate01/75/Behind-OOD-domain-modelling-in-post-OO-world-10-2048.jpg)

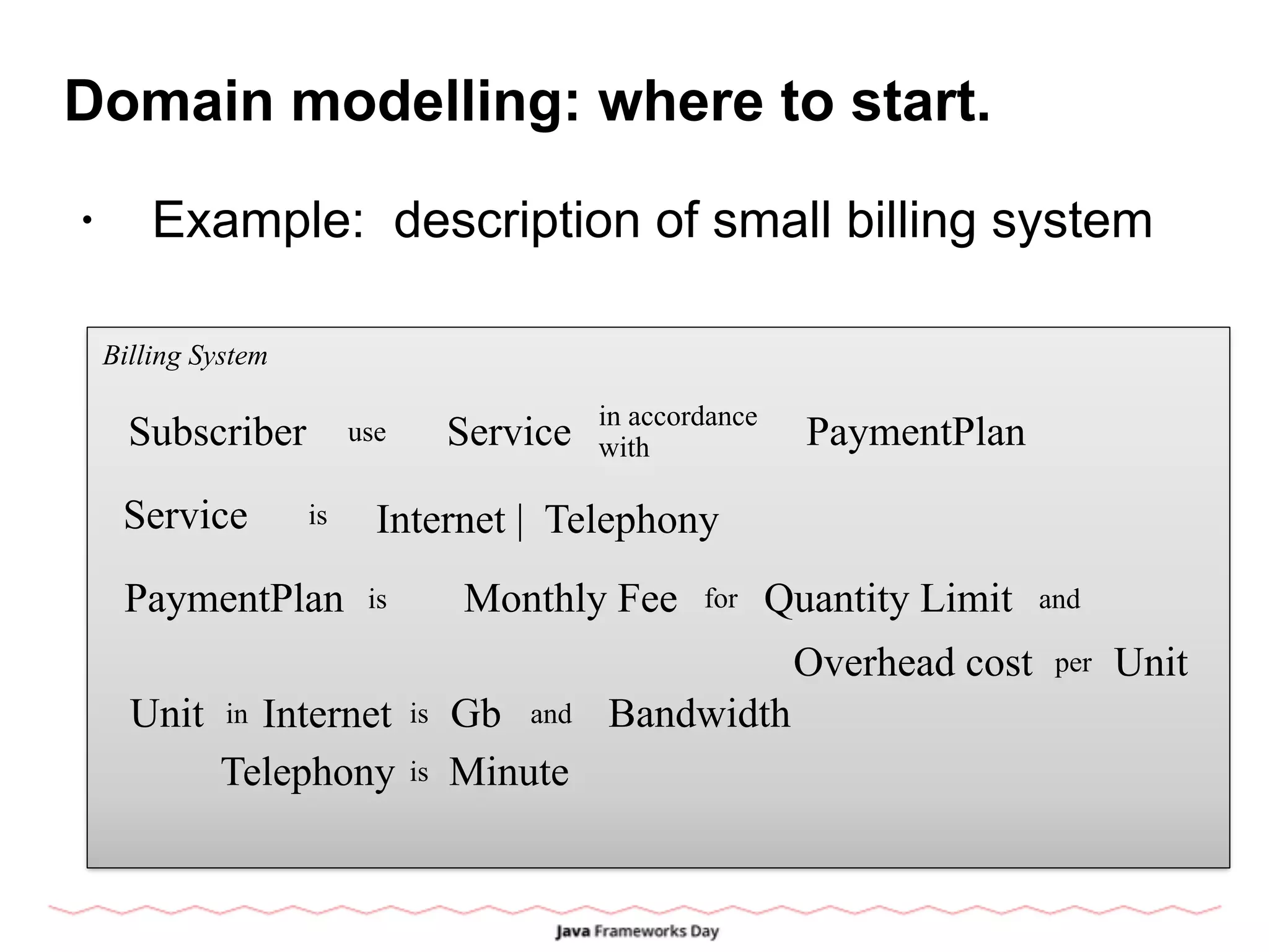
![Domain modelling
• Post OO way: describe limited set of objects
and relationships.
• Algebra instead Ontology
• Existential equality [identity == same
attributes]
• Rules of algebra <=> rules of reality.](https://image.slidesharecdn.com/ruslan-150307054551-conversion-gate01/75/Behind-OOD-domain-modelling-in-post-OO-world-12-2048.jpg)

](https://image.slidesharecdn.com/ruslan-150307054551-conversion-gate01/75/Behind-OOD-domain-modelling-in-post-OO-world-15-2048.jpg)

![adding fields for Subscriber aggregates.
case class Subscriber(id, name,
serviceInfos:Map[Service,SubscriberServiceInfo],
account: BigDecimal, …..
)
case class SubscriberServiceInfo[S<:Service,L<:S#Limits](
service: S, tariffPlan: tariffPlan[S,L], amountUsed:Double
)
trait BillingService
{
def checkServiceAccess(u:Subscriber,s:Service):Boolean =
u.serviceInfos(s).isDefined && u.account > 0
}](https://image.slidesharecdn.com/ruslan-150307054551-conversion-gate01/75/Behind-OOD-domain-modelling-in-post-OO-world-17-2048.jpg)
![adding fields for Subscriber aggregates.
case class Subscriber(id, name,
serviceInfos:Map[Service,SubscriberServiceInfo[_,_]],
account: BigDecimal, …..
)
case class ServiceUsage(service, amount, when)
trait BillingService
{
def rateServiceUsage(u:Subscriber,r:ServiceUsage):Subscriber =
serviceInfo(r.service) match {
case Some(SubscriberServiceInfo(service,plan,amount)) =>
val price = ….
u.copy(account = u.account - price,
serviceInfo = serviceInfo.updated(s,
}](https://image.slidesharecdn.com/ruslan-150307054551-conversion-gate01/75/Behind-OOD-domain-modelling-in-post-OO-world-18-2048.jpg)

![Subscriber aggregates [rate: lastPayedDate]
case class Subscriber(id, name,
serviceInfos:Map[Service,SubscriberServiceInfo[_,_]],
account: BigDecimal,
lastPayedDate: DateTime
)
trait BillingService
{
def ratePeriod(u:Subscriber,date:DateTime):Subscriber =
if (date < u.lastPayedDate) u
else {
val price = …..
subscriber.copy(account = u.account - price,
lastPayedDate = date+1.month)
}
}](https://image.slidesharecdn.com/ruslan-150307054551-conversion-gate01/75/Behind-OOD-domain-modelling-in-post-OO-world-20-2048.jpg)
![Subscriber:
case class Subscriber(
id : Long,
name: String,
serviceInfos:Map[Service,SubscriberServiceInfo[_,_]],
account: BigDecimal,
lastPayedDate: DateTime
)
case class SubscriberServiceInfo[S<:Service,L<:S#Limits](
service: S,
tariffPlan: tariffPlan[L],
amountUsed:Double
)](https://image.slidesharecdn.com/ruslan-150307054551-conversion-gate01/75/Behind-OOD-domain-modelling-in-post-OO-world-21-2048.jpg)
![Subscriber:
case class Subscriber(
id : Long,
name: String,
internetServiceInfo: ServiceInfo[Internet,Internet.Limits],
telephonyServiceInfo: ServiceInfo[Telephony,Telephony.Limits],
account: BigDecimal,
lastPayedDate: DateTime
) {
def serviceInfo(s:Service):SubscriberServiceInfo[s.type,s.Limits] =
….
def updateServiceInfo[S<:Service,L<:S#Limits](
serviceInfo:SubscriberServiceInfo[S,L]): Subscriber =
…
}](https://image.slidesharecdn.com/ruslan-150307054551-conversion-gate01/75/Behind-OOD-domain-modelling-in-post-OO-world-22-2048.jpg)
![From domain model to implementation. [S1]
Subscriber
Service TariffPlan
Domain Data/ Aggregates Services
SubscriberOperations
TariffPlanOperations
….
Repository
DD — contains only essential data
Services — only functionality
Testable.
No mess with implementation.
Service calls — domain events](https://image.slidesharecdn.com/ruslan-150307054551-conversion-gate01/75/Behind-OOD-domain-modelling-in-post-OO-world-23-2048.jpg)
![From domain model to implementation. [S1]
Improvements/Refactoring space:
• Errors handling
• Deaggregate
• Fluent DSL](https://image.slidesharecdn.com/ruslan-150307054551-conversion-gate01/75/Behind-OOD-domain-modelling-in-post-OO-world-24-2048.jpg)

![Design for failure:
trait BillingService
{
def checkServiceAccess(u:Subscriber,s:Service): Boolean
def rateServiceUsage(u:Subscriber,r:ServiceUsage):Try[Subscriber]
def ratePeriod(u:Subscriber, date: DateTime): Try[Subscriber]
def acceptPayment(u:Subscriber, payment:Payment): Subscriber
}](https://image.slidesharecdn.com/ruslan-150307054551-conversion-gate01/75/Behind-OOD-domain-modelling-in-post-OO-world-26-2048.jpg)
![Design for failure:
sealed trait Try[+X]
case class Success[X](v:X) extends Try[X]
case class Failure(ex:Throwable) extends Try[Nothing]
when use Try / traditional exception handling?
Try — error recovery is a part of business layers.
(i.e. errors is domain-related)
Exception handling — error recovery is a part of infrastructure layer.
(i. e. errors is system-related)](https://image.slidesharecdn.com/ruslan-150307054551-conversion-gate01/75/Behind-OOD-domain-modelling-in-post-OO-world-27-2048.jpg)
![Deaggregation:
trait Repository
{
def create[T](): T
def find[T](id: Id[T]): Try[T]
def save[T](obj: T): Try[Boolean]
}](https://image.slidesharecdn.com/ruslan-150307054551-conversion-gate01/75/Behind-OOD-domain-modelling-in-post-OO-world-28-2048.jpg)
![Deaggregation:
trait Repository
{
def create[T](): T
def find[T](id: Id[T]): Try[T]
def save[T](obj: T) : Try[T]
………..
def subscriberServiceInfo[S<:Service,L<:S#Limits]
(id: Id[Subscriber], s:S): SubscriberServiceInfo[S,L]
def updateSubsriberServiceInfo[S<:Service,L<:S#Limits] (
id: Id[Subscriber],s:S,si:SubscriberServiceInfo[S,L]):
Try[SubscriberServiceInfo[S,L]]
}](https://image.slidesharecdn.com/ruslan-150307054551-conversion-gate01/75/Behind-OOD-domain-modelling-in-post-OO-world-29-2048.jpg)
![Deaggregation:
trait BillingService
{
def checkServiceAccess(r:Repository, uid:Id[Subscriber],
s:Service): Boolean
def rateServiceUsage(r: Repository, uid:Id[Subscriber],
r:ServiceUsage):Try[Subscriber]
…..
}](https://image.slidesharecdn.com/ruslan-150307054551-conversion-gate01/75/Behind-OOD-domain-modelling-in-post-OO-world-30-2048.jpg)
![Deaggregation:
trait BillingService
{
val repository: Repository
def checkServiceAccess(uid:Id[Subscriber], s:Service): Try[Boolean]
def rateServiceUsage(uid:Id[Subscriber], r:ServiceUsage):Try[Subscriber]
…..
}
// BillingService operations interpret repository](https://image.slidesharecdn.com/ruslan-150307054551-conversion-gate01/75/Behind-OOD-domain-modelling-in-post-OO-world-31-2048.jpg)
![Deaggregation. [S2]
Subscriber
Service TariffPlan
Domain Data/ Aggregates Services
SubscriberOperations
TariffPlanOperations
….
Repository
Interpret
- Not for all cases
- Loss
- generality of repository
- simply logic
- Gain
- simple repository operations
- more efficient data access.](https://image.slidesharecdn.com/ruslan-150307054551-conversion-gate01/75/Behind-OOD-domain-modelling-in-post-OO-world-32-2048.jpg)


TariffPlan(100,Limits(1,100),2)
TariffPlan(montlyFee=100,
Internet.Limits(gb=1,bandwidth=100),
2)
100 hrn montly (1 gb) speed 100 excess 2 hrn per 1 gb
// let’s build](https://image.slidesharecdn.com/ruslan-150307054551-conversion-gate01/75/Behind-OOD-domain-modelling-in-post-OO-world-34-2048.jpg)
![TariffPlan: DSL
(100 hrn) montly (1 gb) speed 100 excess (2 hrn) per (1 gb)
trait TariffPlanDSL[S <: Service, L <: S#Limits] {
implicit class ToHrn(v: Int)
{
def hrn = this
def monthly(x: LimitExpression) =
TariffPlan(v, x.limit, 0)
def per(x: QuantityExpression
}
1 hrn = 1.hrn =
new ToHrn(1).hrn
trait LimitExpression{
def limit: L
}
type QuantityExpression
{
def quantity: Int
}](https://image.slidesharecdn.com/ruslan-150307054551-conversion-gate01/75/Behind-OOD-domain-modelling-in-post-OO-world-35-2048.jpg)
![TariffPlan: DSL
(100 hrn) montly (1 gb) speed 100 excess (2 hrn) per (1 gb)
object InternetTariffPlanDSL extends TariffPlanDSL[Internet.type, Internet.Limits]
implicit class Gb(v: Int) extends LimitExpression with QuantityExpression{
def gb = this
def limit = Internet.Limits(v,100)
def quantity = x
}](https://image.slidesharecdn.com/ruslan-150307054551-conversion-gate01/75/Behind-OOD-domain-modelling-in-post-OO-world-36-2048.jpg)

![TariffPlan: DSL
(100 hrn) montly (1 gb) speed 100 excess ((2 hrn) per (1 gb))
trait TariffPlanDSL[S,L]
case class PerExpression(money: ToHrn, quantity: QuantityExpression)
trait RichTariffPlan(p: TariffPlan[L]) {
def excess(x: PerExpression) = p.copy(excessCost=x.v)
}
((100.hrn).montly(1.gb) speed 100).excess((2 hrn) per (1 gb))](https://image.slidesharecdn.com/ruslan-150307054551-conversion-gate01/75/Behind-OOD-domain-modelling-in-post-OO-world-38-2048.jpg)
![TariffPlan: DSL
(100 hrn) montly (1 gb) speed 100 excess ((2 hrn) per (1 gb))
object InternetTariffPlanDSL[S,L]
trait RichTariffPlan(p: TariffPlan[L]) extends super.RichTariffPlan(p) {
def speed(x: Int) = p.copy(
monthlyLimits = p.monthlyLimits.copy(
bandwidth = x)
)
}
((100.hrn).montly(1.gb) speed 100).excess ((2.hrn).per(1.gb))
((100.hrn).montly(1.gb).speed(100)).excess ((2.hrn).per(1.gb))](https://image.slidesharecdn.com/ruslan-150307054551-conversion-gate01/75/Behind-OOD-domain-modelling-in-post-OO-world-39-2048.jpg)
![DSL: (100 hrn) montly (1 gb) speed 100 excess ((2 hrn) per (1 gb))
Internal
External
Need some boilerplate code.
Useful when developers need fluent business
domain object notation.
Internally - combination of builder and interpreter patterns
Useful when external users (non-developers) want to describe
domain objects.
Internally - language-mini-interpreter.
// [scala default library include parser combinators]](https://image.slidesharecdn.com/ruslan-150307054551-conversion-gate01/75/Behind-OOD-domain-modelling-in-post-OO-world-40-2048.jpg)


The document discusses domain modeling approaches in a post-object-oriented world. It outlines issues with traditional OO domain modeling and proposes an alternative approach. This involves: 1. Describing a limited set of domain objects and relationships as an "algebra" rather than a universal ontology. 2. Using existential equality where identity is defined by attributes rather than identity. 3. Building a simple domain model for a toy billing system to demonstrate the approach. 4. Discussing how the domain model can be implemented and improved, including handling errors, deaggregating components, and using internal domain-specific languages.










































![Embedding Generic Monadic Transformer into Scala. [Tfp2022]](https://cdn.slidesharecdn.com/ss_thumbnails/tfp2022-220317101745-thumbnail.jpg?width=640&height=640&fit=bounds)
























