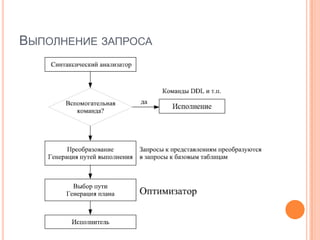
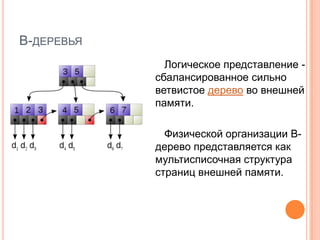
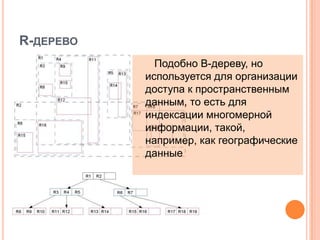
Документ содержит рекомендации и методы оптимизации скорости выполнения запросов в реляционных системах управления базами данных (РСУБД), включая использование правильных индексов, анализ планов выполнения и профилирование запросов. Обсуждаются ошибки при написании SQL-запросов и проектировании схем, а также важность нормализации и денормализации данных. В заключение, документ актуализирует различные аспекты управления производительностью баз данных и включает ссылки на профильную литературу.













![Запретить использование неподходящего индексаСоздать простейшее выражение при упоминании индексируемого столбца:O.Regino_ID+ 0 = 137Подсказки:table_name[[AS] alias] [index_hint] USE INDEX (index_list) GNORE INDEX (index_list) FORCE INDEX(index_list)](https://image.slidesharecdn.com/01-100207170514-phpapp01/85/Query-perfomance-tuning-14-320.jpg)









![ViewsCREATE [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}] VIEWMERGE – при обращении к представлению добавляет в использующийся оператор соответствующие части из определения представления и выполняет получившийся операторTEMPTABLE - заносит содержимое представления во временную таблицу, над которой затем выполняется оператор обращенный к представлению](https://image.slidesharecdn.com/01-100207170514-phpapp01/85/Query-perfomance-tuning-24-320.jpg)








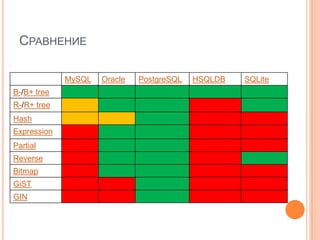

![ДругиеНормализация\ДенормализацияБольшое количество соединений таблицРасчетные значенияДлинные поляTemporarytableCREATE [TEMPORARY] TABLE …Блокировки\Транзакции](https://image.slidesharecdn.com/01-100207170514-phpapp01/85/Query-perfomance-tuning-38-320.jpg)
























































