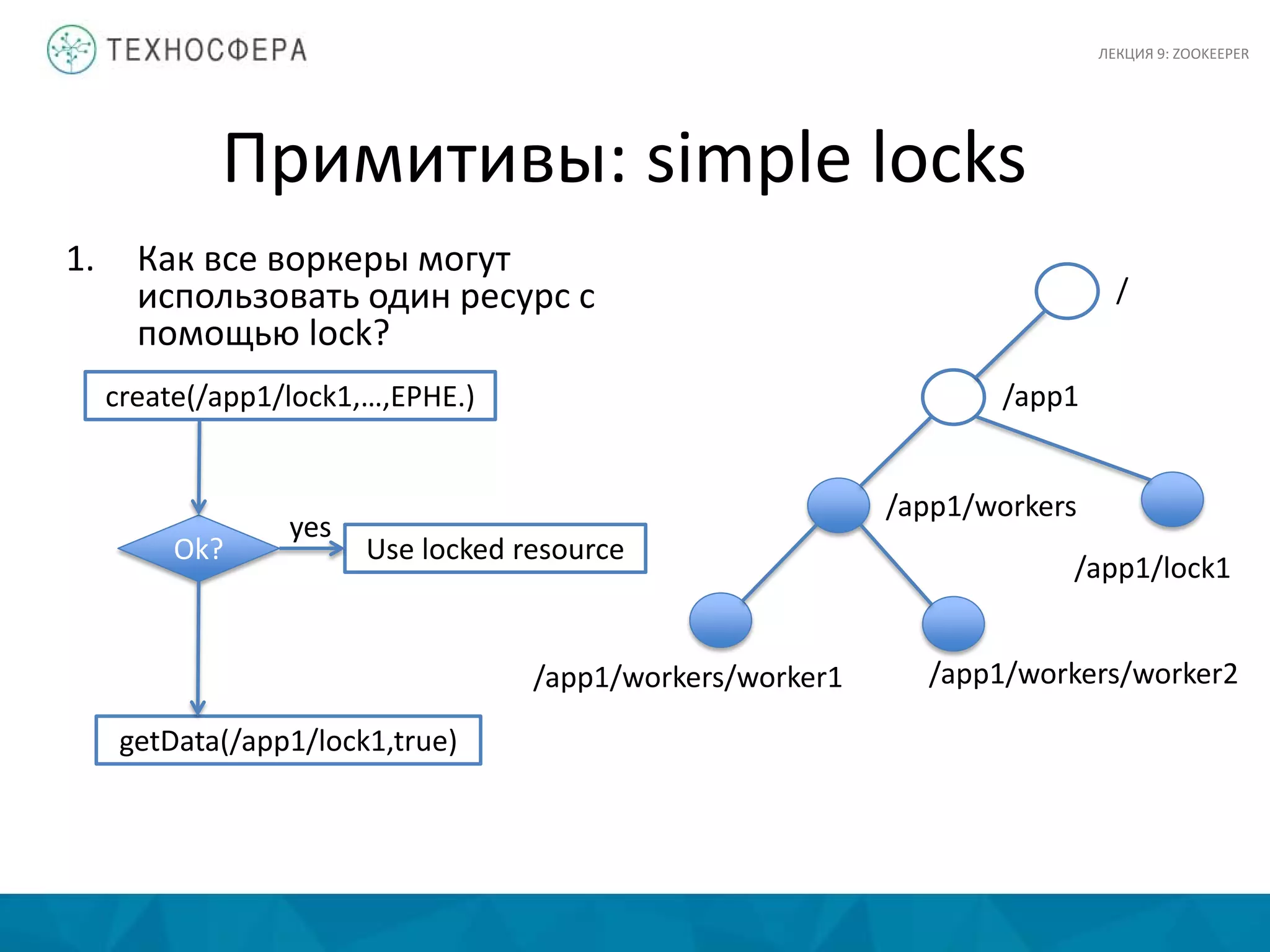
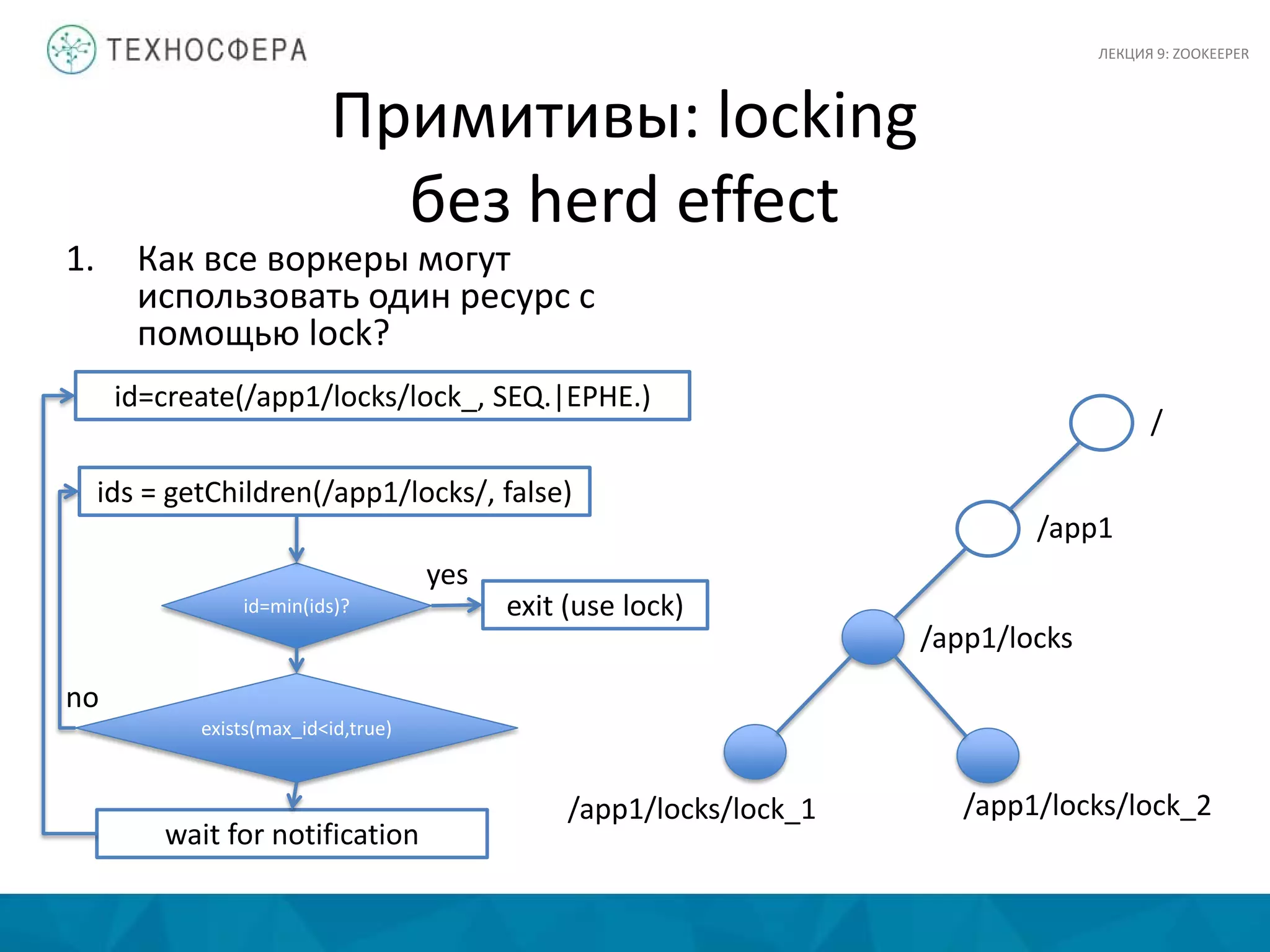
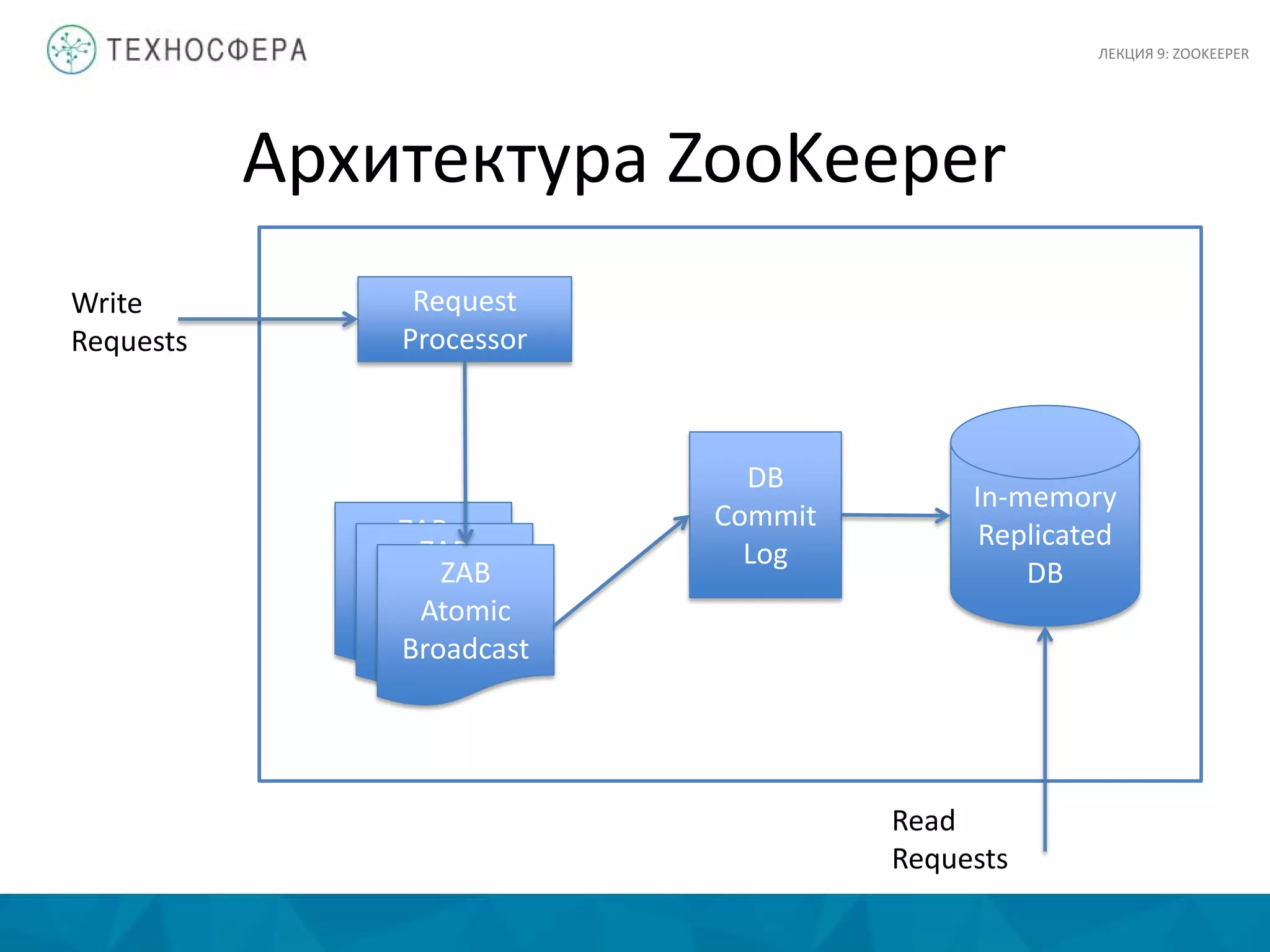
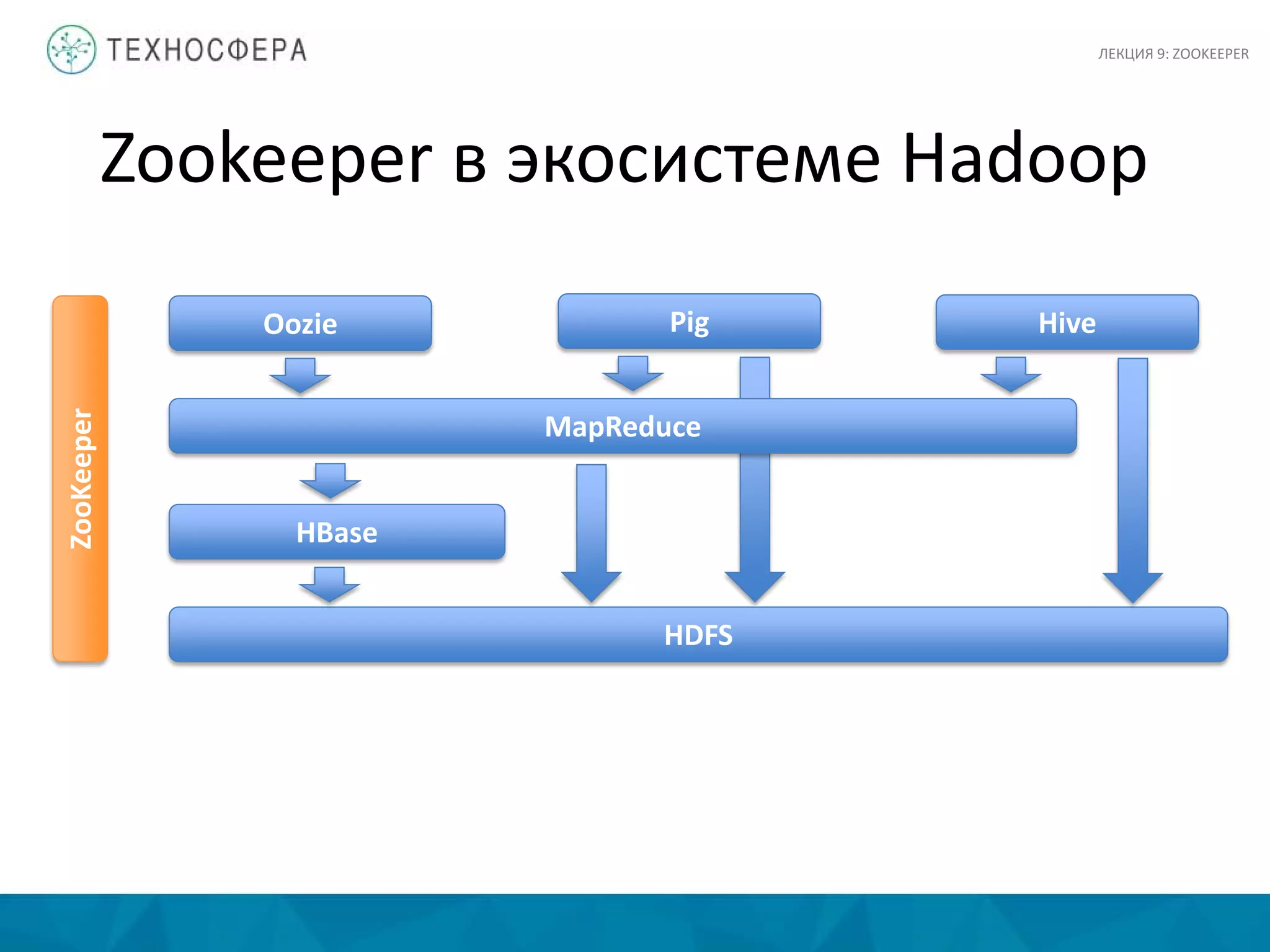
Документ представляет лекцию о Zookeeper, сервисе для координации распределенных приложений в экосистеме Hadoop, разработанном в Yahoo! Research. Основные аспекты включают сложности координации, принципы проектирования, модель данных и детали API. Zookeeper предлагает инструменты для обработки частичных сбоев и управления такими задачами, как выбор лидера и доступ к критическим ресурсам.


















![ЛЕКЦИЯ 9: ZOOKEEPER
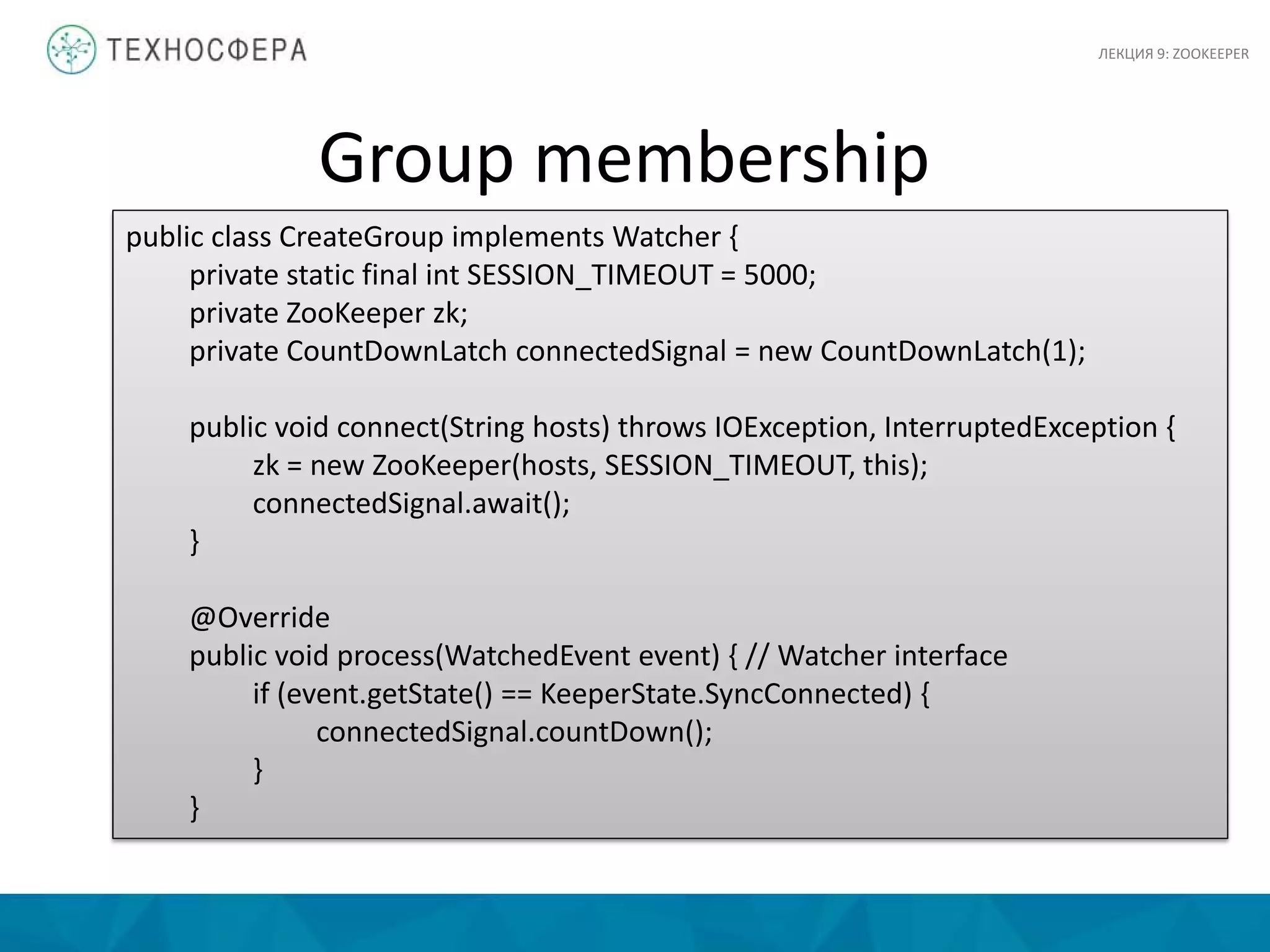
public void create(String groupName) throws KeeperException,
InterruptedException {
String path = "/" + groupName;
String createdPath = zk.create(path, null/*data*/, Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
System.out.println("Created " + createdPath);
}
public void close() throws InterruptedException {
zk.close();
}
public static void main(String[] args) throws Exception {
CreateGroup createGroup = new CreateGroup();
createGroup.connect(args[0]);
createGroup.create(args[1]);
createGroup.close();
}
}
Group membership](https://image.slidesharecdn.com/lecture09-150516065415-lva1-app6892/75/9-ZooKeeper-27-2048.jpg)