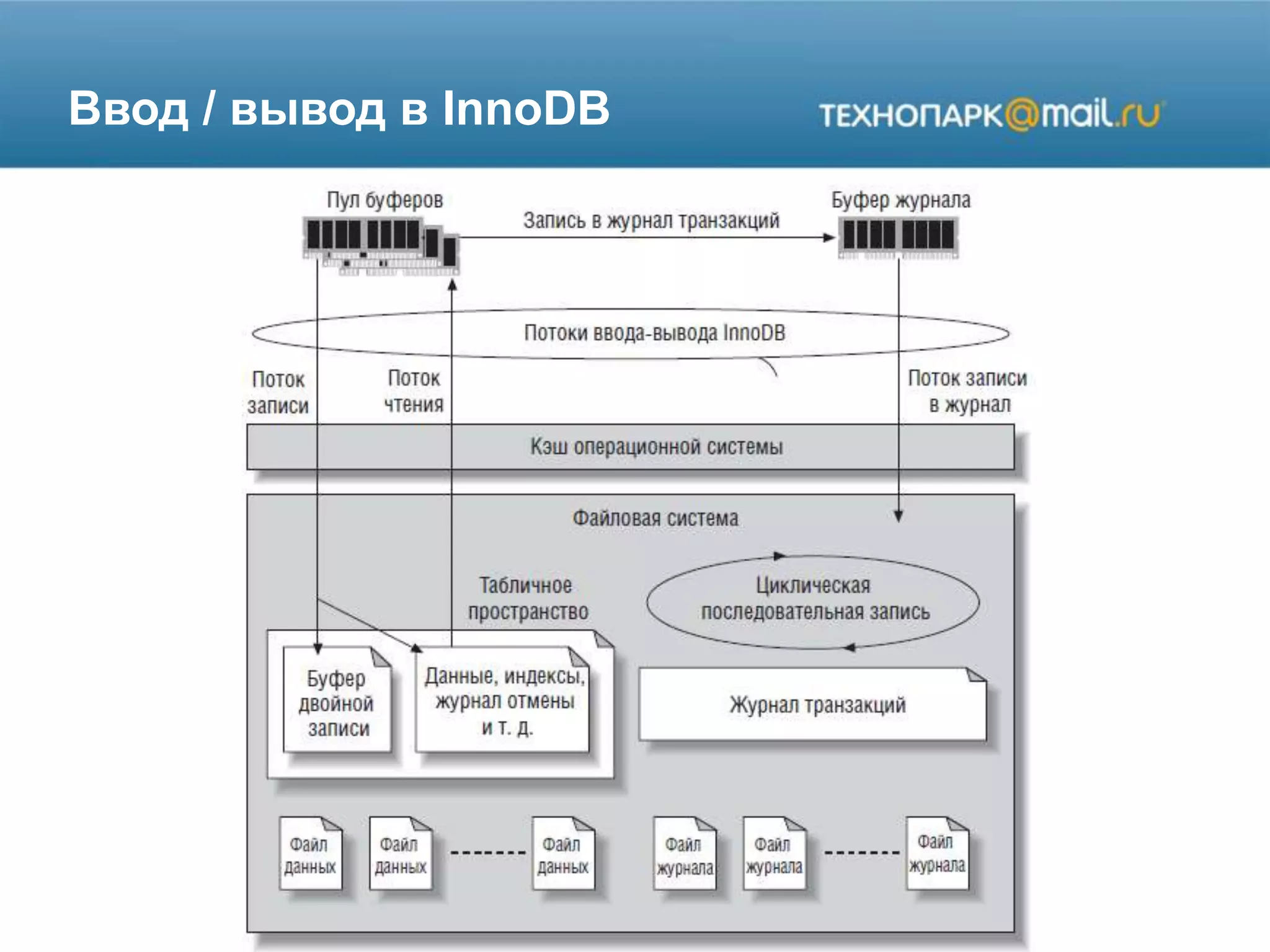
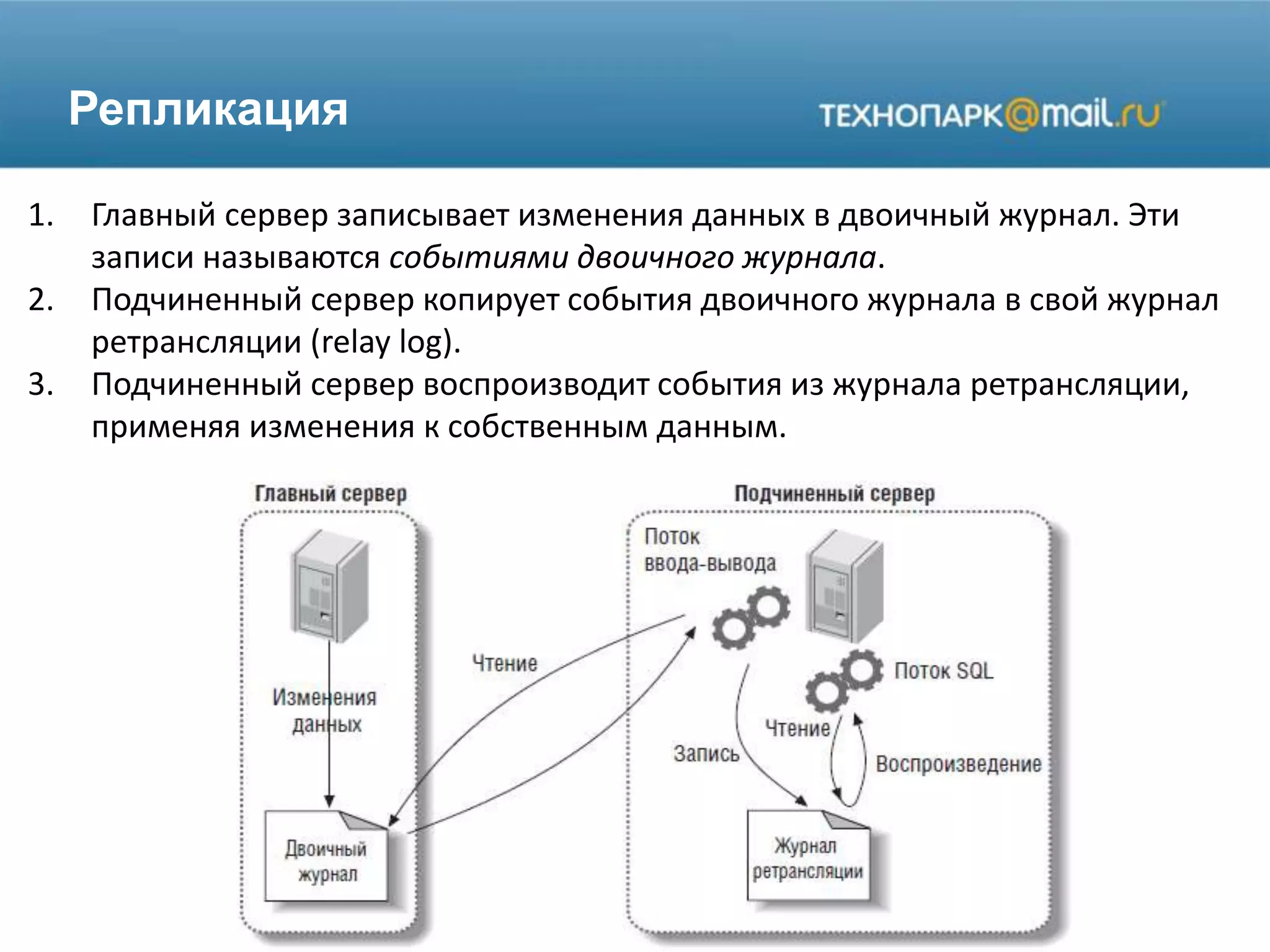
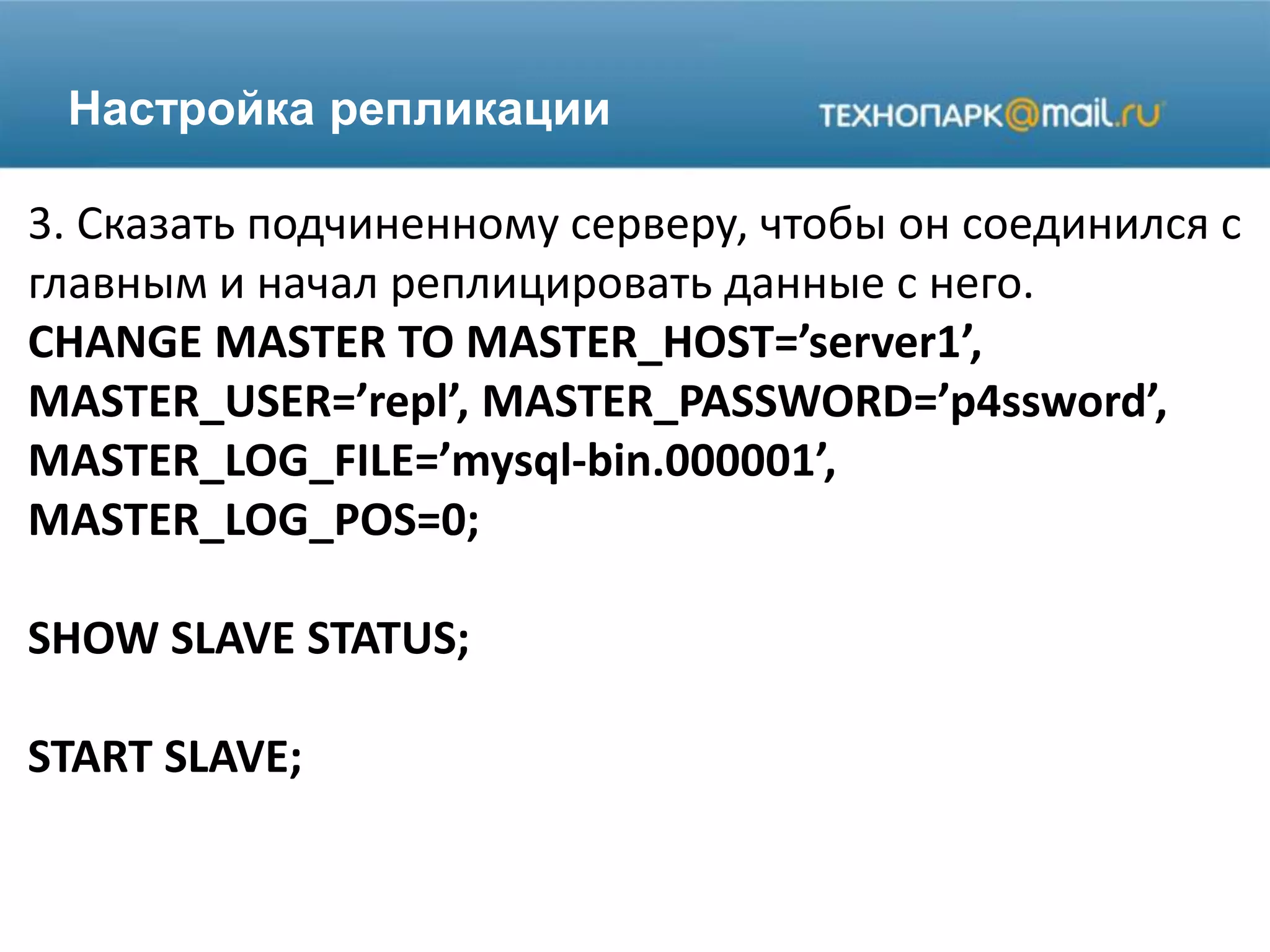
Лекция по конфигурированию MySQL охватывает настройки памяти, переменные, использование кэша и репликацию. Обсуждаются оптимальные параметры для управления кэшами и производительностью, а также стратегии репликации данных для обеспечения высокой доступности и резервного копирования. Представлены примеры команд и конфигураций для настройки системы MySQL.