Downloaded 10 times
















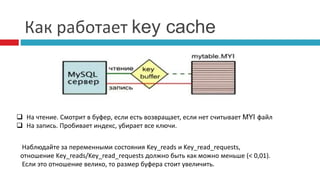






![Что мы должны знать?
SHOW VARIABLES SHOW STATUS
Манипуляция c MySQL сервером осуществляется через System Variables
- mysql> SHOW [GLOBAL|SESSION] VARIABLES [LIKE "string"];
- SET [GLOBAL] <variable>=<value>
- устанавливается через my.cnf
http://dev.mysql.com/doc/refman/5.0/en/server-system-variables.html
SHOW STATUS [like “string”] – показывает чем вообще система занимается, занималась.
http://dev.mysql.com/doc/refman/5.0/en/server-status-variables.html](https://image.slidesharecdn.com/rawanmysql-140923051422-phpapp01/85/MySQL-Optimization-Russian-32-320.jpg)





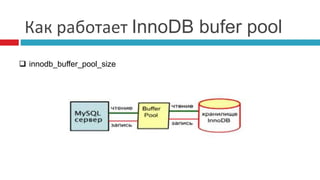
![Procedure ANALYZE()
SELECT ... FROM ... WHERE ... PROCEDURE ANALYSE([max_elements,[max_memory]])](https://image.slidesharecdn.com/rawanmysql-140923051422-phpapp01/85/MySQL-Optimization-Russian-40-320.jpg)



![Настройка мастера
IP мастера - 192.168.1.101, IP реплики - 192.168.1.102
Настроить сервер
Задать права
Мастер:
[mysqld]:
server-id = 1 #уникальный ID сервера
log-bin = /var/lib/mysql/mysql-bin #путь для бинарных логов
replicate-do-db = testdb #имя БД для репликации
mysql@master> GRANT replication slave ON "testdb".* TO "replication"@"192.168.1.102"
IDENTIFIED BY "password";
restart](https://image.slidesharecdn.com/rawanmysql-140923051422-phpapp01/85/MySQL-Optimization-Russian-44-320.jpg)
![Настройка реплики
[mysqld]:
server-id = 2
relay-log = /var/lib/mysql/mysql-relay-bin
relay-log-index = /var/lib/mysql/mysql-relay-bin.index
replicate-do-db = testdb
mysql@replica> CHANGE MASTER TO MASTER_HOST = "192.168.1.101 ",
MASTER_USER = "replication ", MASTER_PASSWORD = "password ",
MASTER_LOG_FILE = "mysql-bin.000003 ", MASTER_LOG_POS = 98;
mysql@replica> start slave;
Значения MASTER_LOG_FILE и MASTER_LOG_POS берем с мастера.](https://image.slidesharecdn.com/rawanmysql-140923051422-phpapp01/85/MySQL-Optimization-Russian-45-320.jpg)

![upstream highload /*myCloudName*/ {
server 192.168.0.1 [weight=3] [max_fails=3] [fail_timeout=60];
server 192.168.0.2 [max_fails=3] [fail_timeout=60];
server 192.168.0.3 [weight=2] [max_fails=3] [fail_timeout=60];
}
server {
listen 89.252.34.107:80;
server_name highload.uk;
location / {
proxy_pass http:// highload/;
proxy_next_upstream error timeout invalid_header http_500 http_503;
}
}](https://image.slidesharecdn.com/rawanmysql-140923051422-phpapp01/85/MySQL-Optimization-Russian-47-320.jpg)


Документ рассматривает оптимизацию производительности MySQL с акцентом на индексы, системные переменные, мониторинг серверов и оптимизацию запросов. Он включает советы по настройке конфигурационных файлов и описывает важные концепции, такие как репликация и партиционирование баз данных. Также затрагиваются инструменты для бенчмаркинга и мониторинга производительности.














































