

























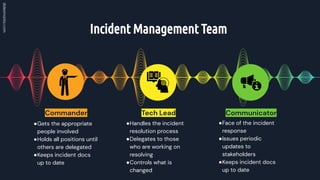




























The document discusses the importance of effective incident management processes when technical issues arise. It emphasizes the need to properly determine if an actual problem exists, communicate the incident to relevant parties, assign roles to responders, document all actions and decisions, provide updates to stakeholders, conduct a post-mortem analysis to identify root causes and preventative measures, and ensure lessons are learned to improve processes. The goal is to resolve incidents quickly while establishing practices that reduce the likelihood of future occurrences and build trust through transparency.



































































