Downloaded 10 times














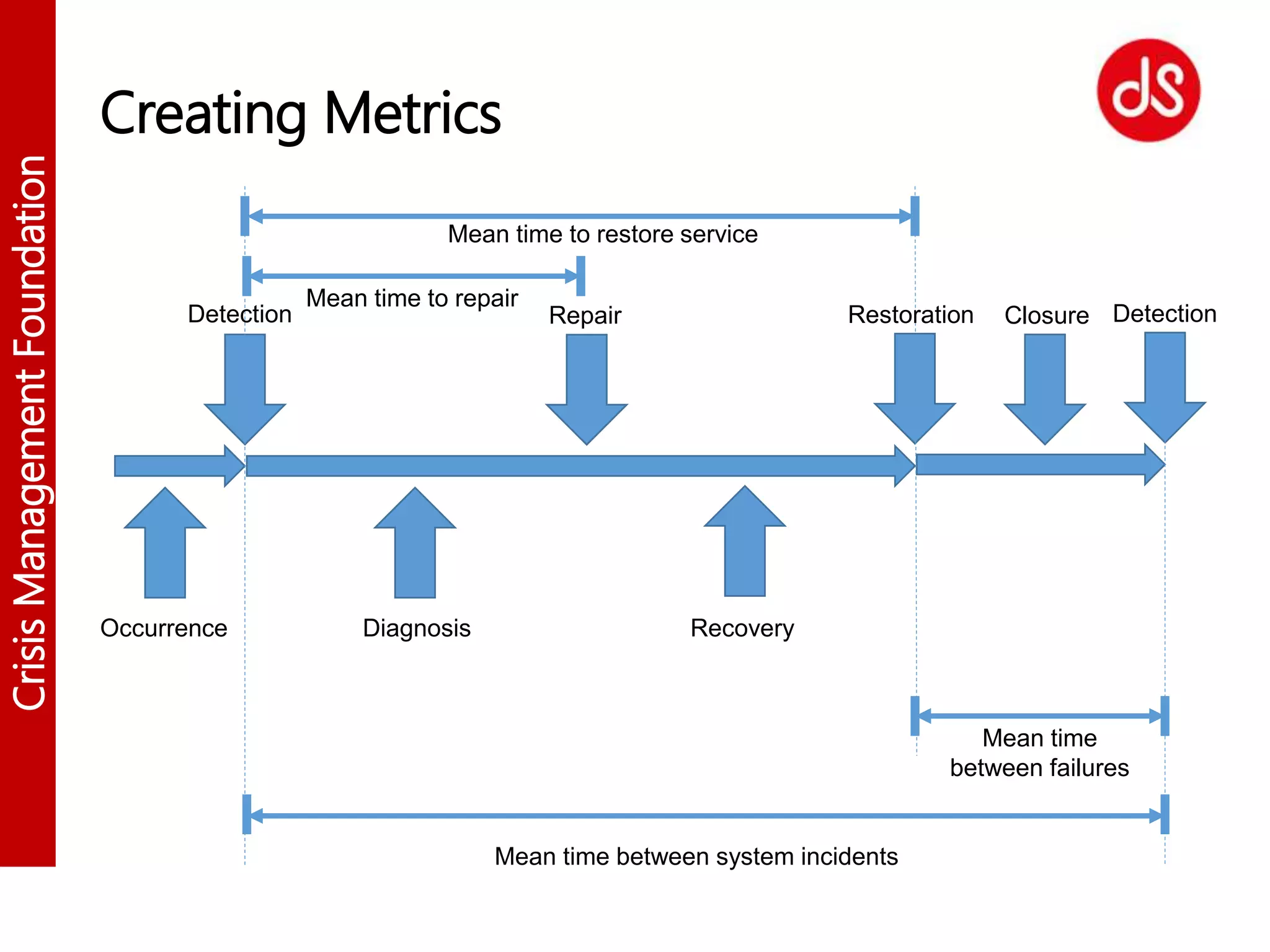

































The document outlines the major incident management lifecycle, emphasizing the importance of time recording and analysis to enhance incident detection, diagnosis, repair, recovery, and restoration processes. It discusses the significance of using checklists and historical data to improve operational efficiency and prevent future incidents, as well as tools for effective incident detection and communication. Metrics and statistical measures are provided to assess system availability and guide improvements in crisis management practices.






























































