Download as PDF, PPTX

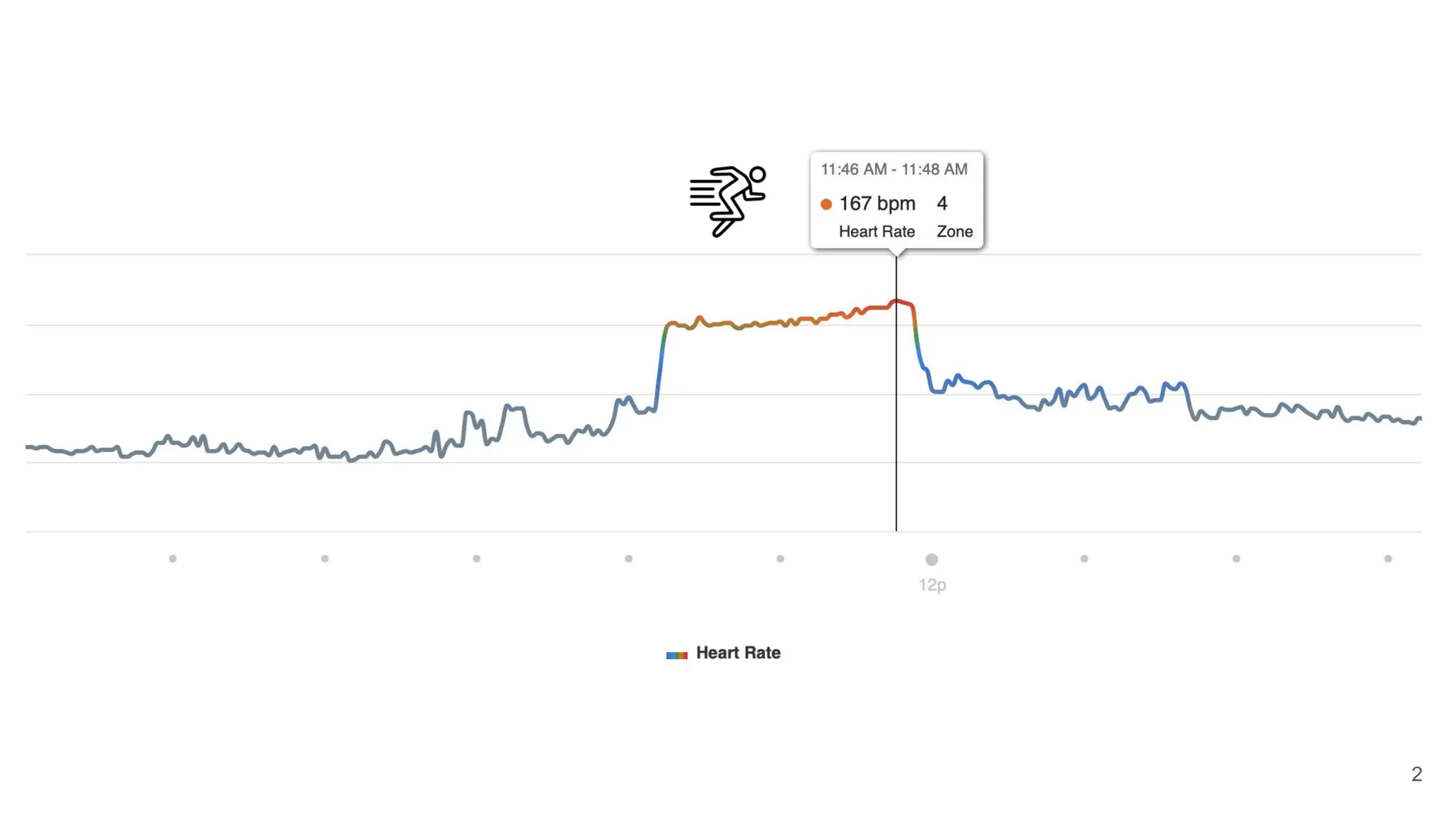
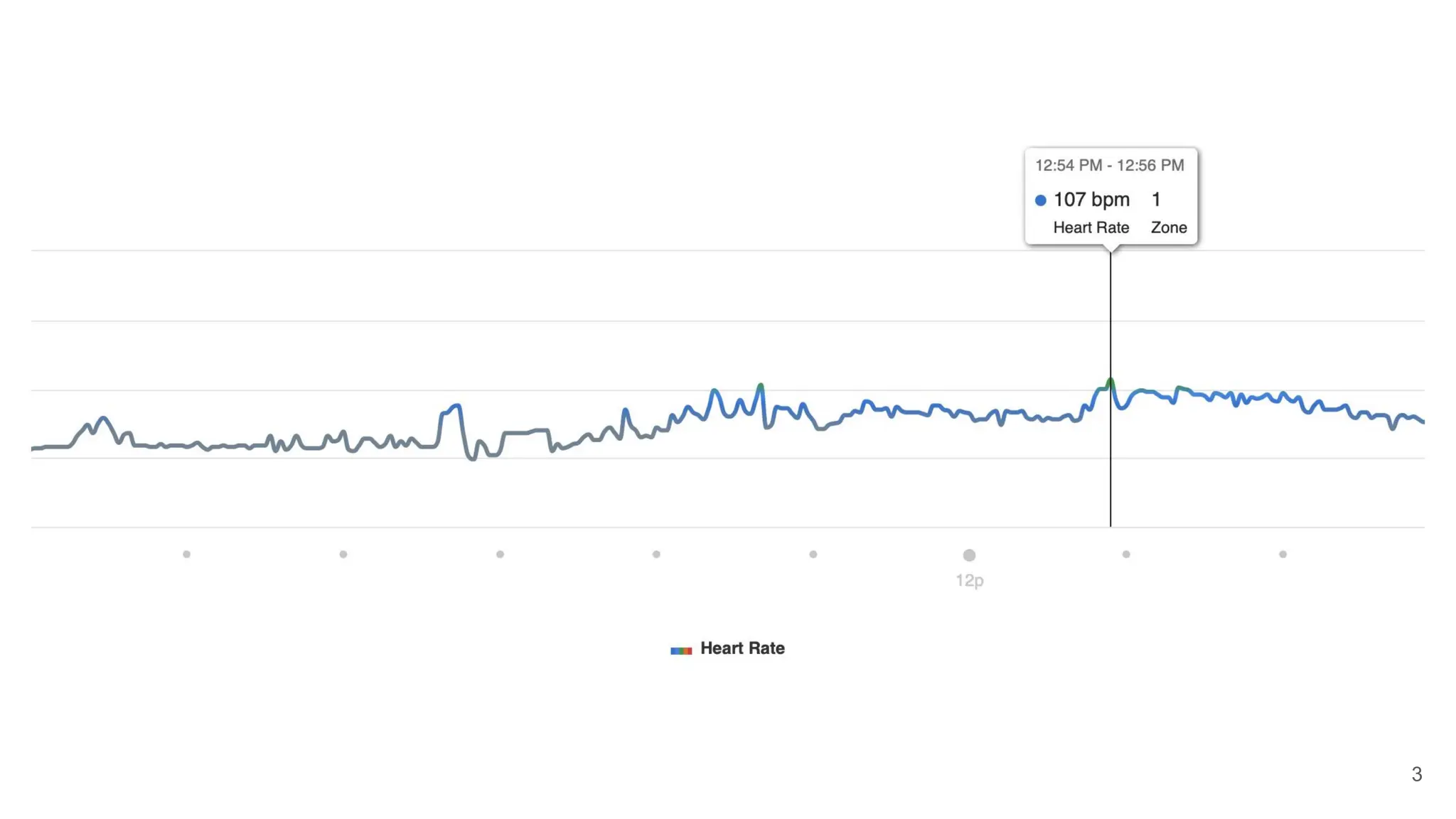
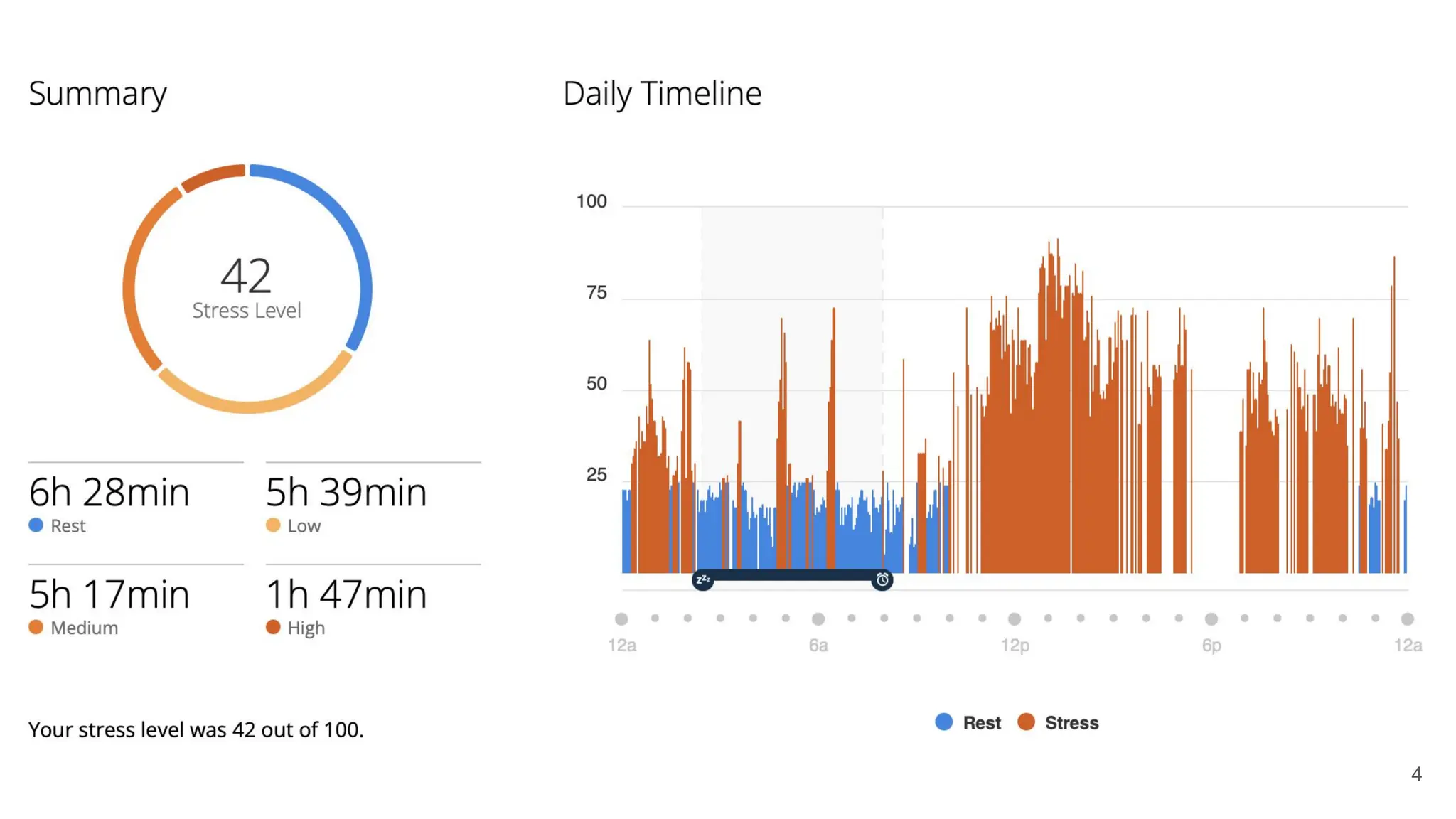















![45
Runbook aka
incident guideline
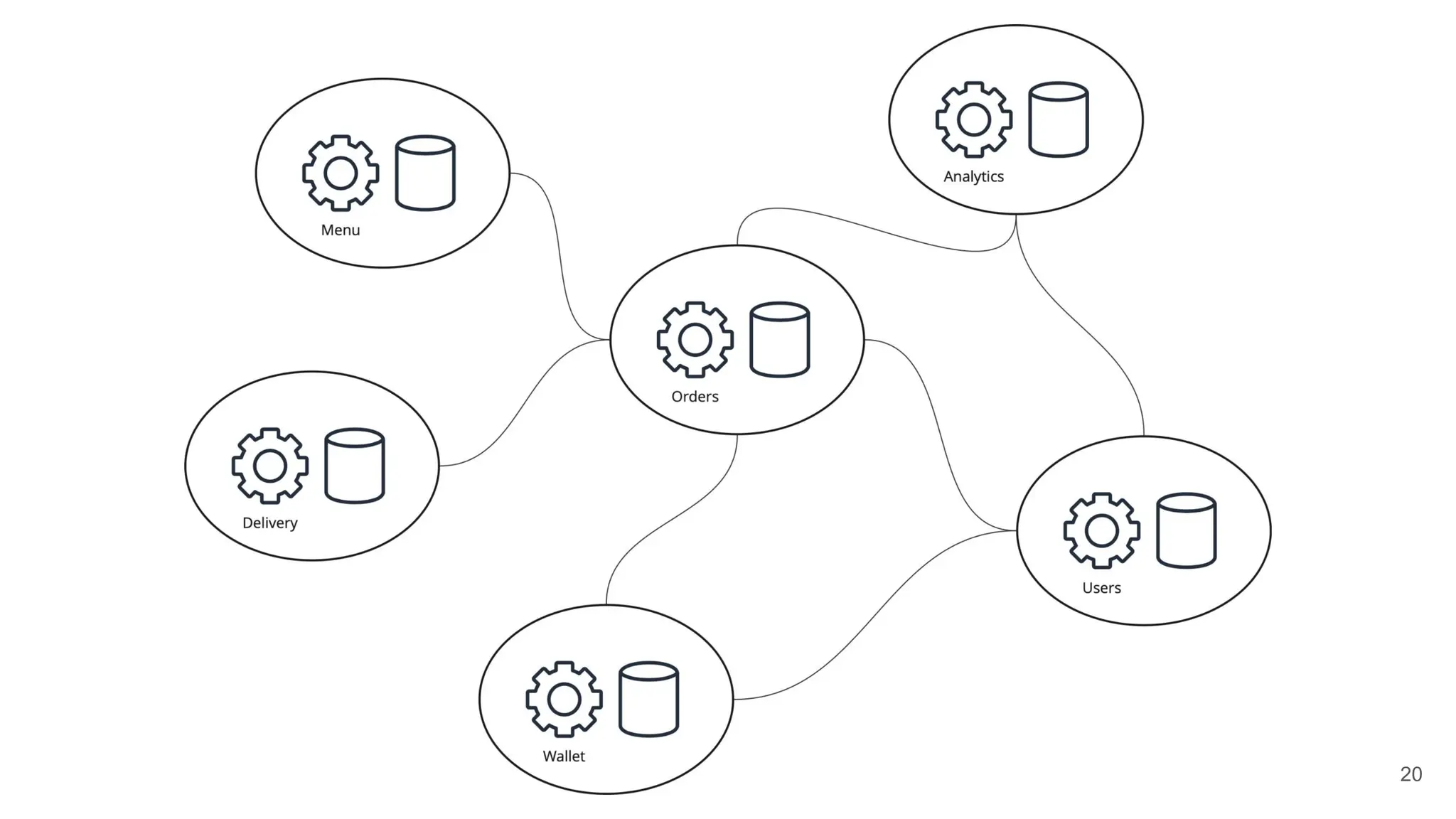
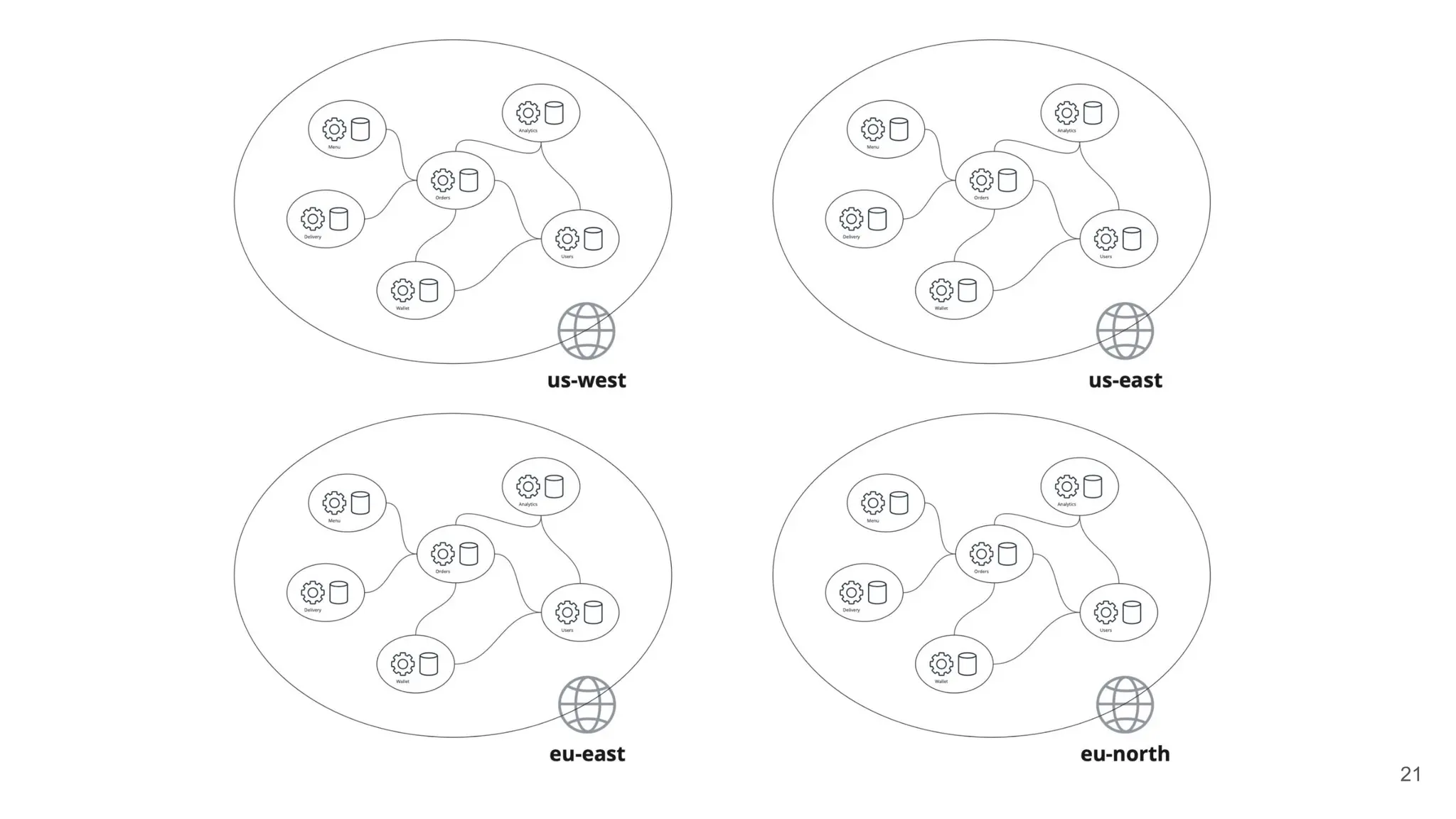
Shared knowledge for the day-to-day IT
operations including incident
management process
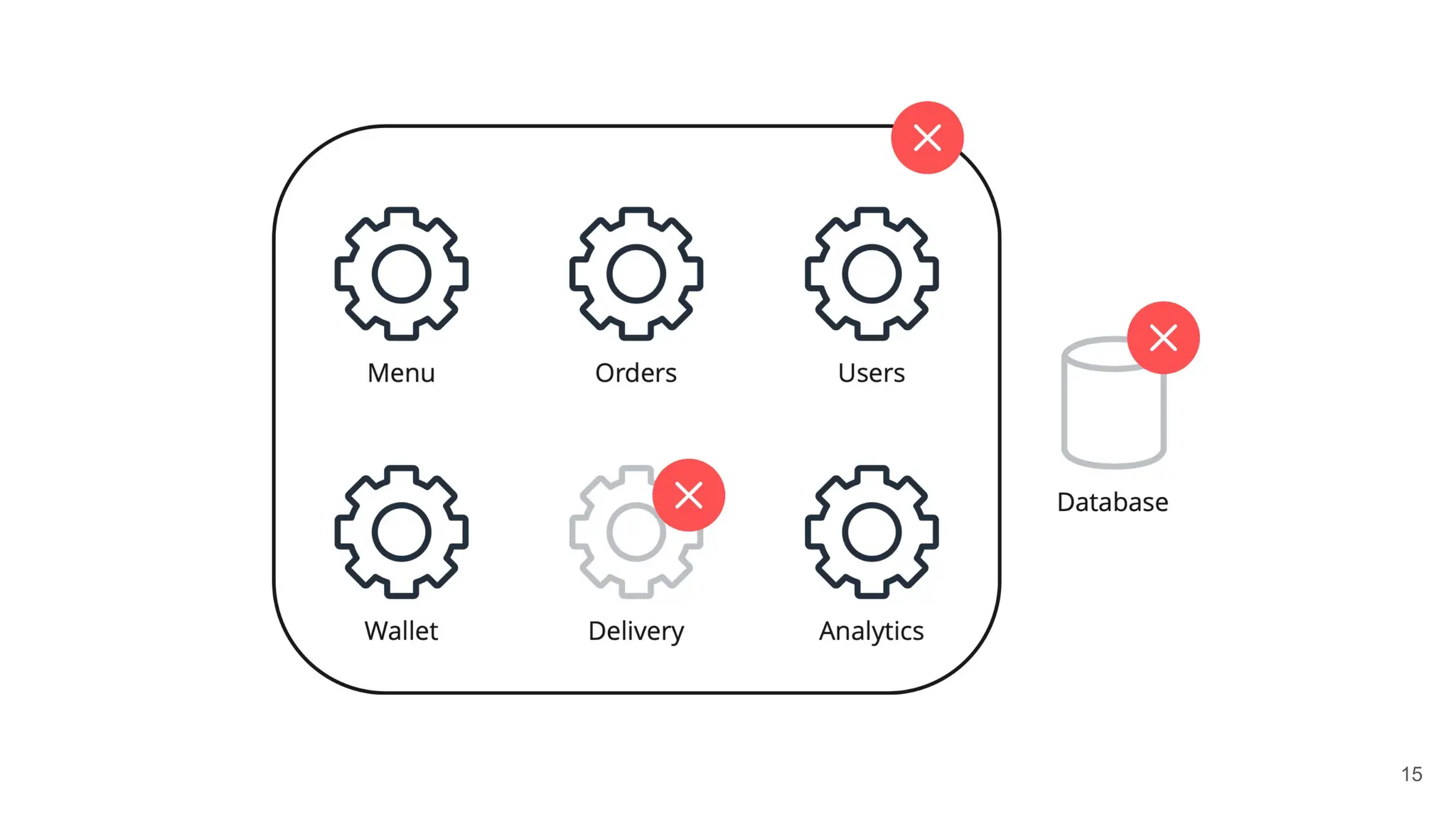
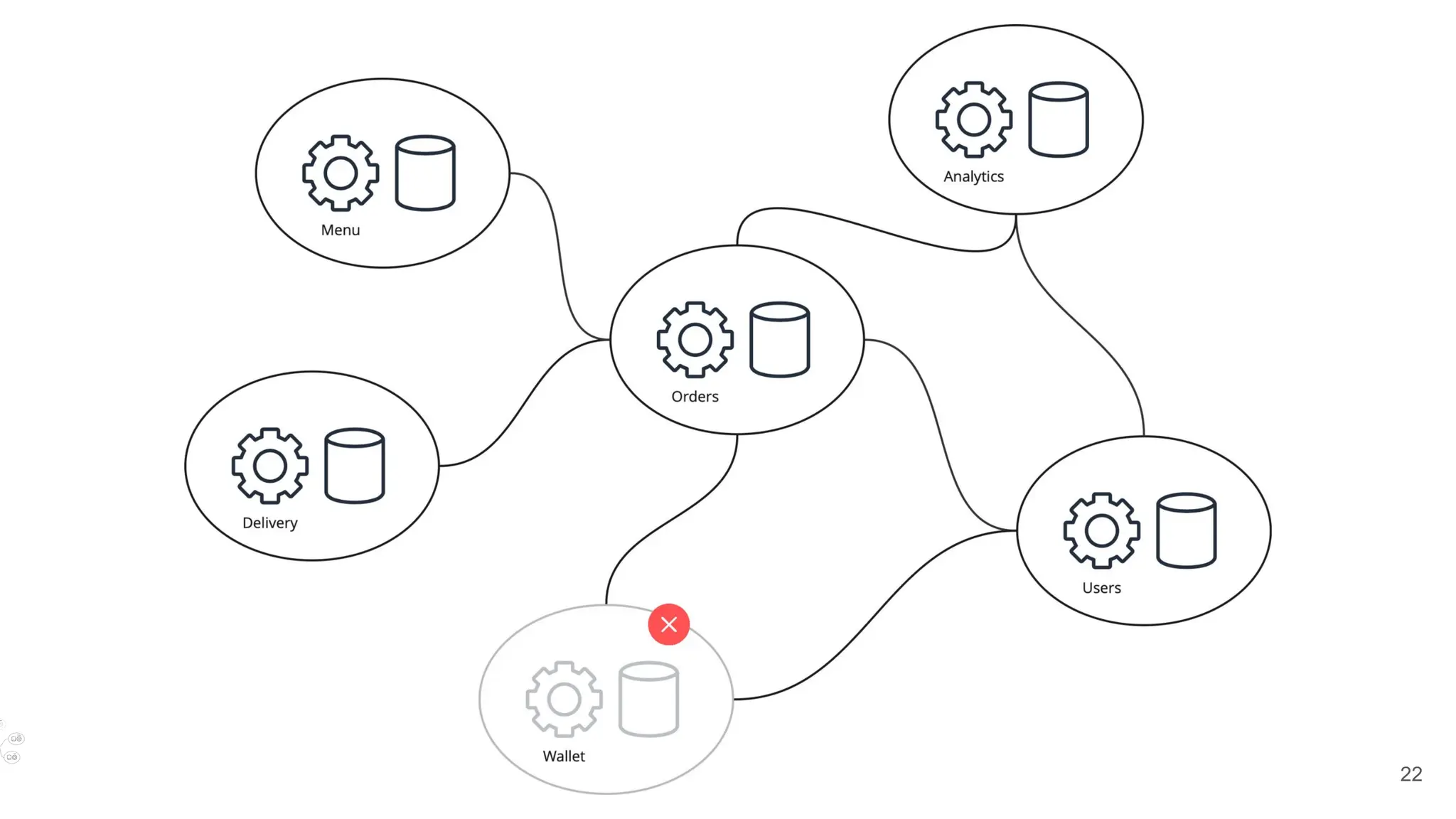
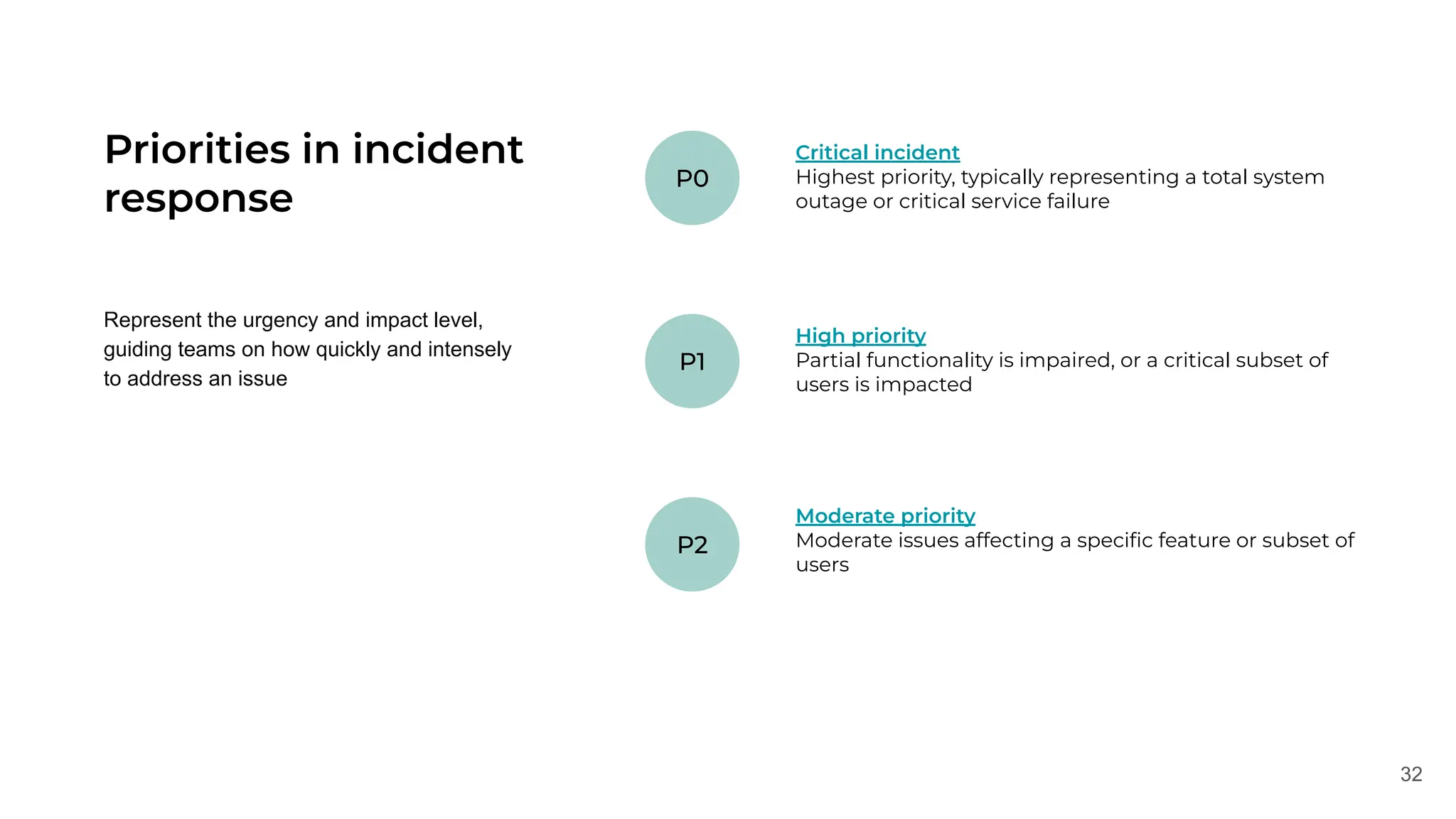
✅Check the priority
If is it critical - create an incident
✅Check the scope
If it is global - escalate according to the policy
✅Start the call
Invite relevant people such as service experts
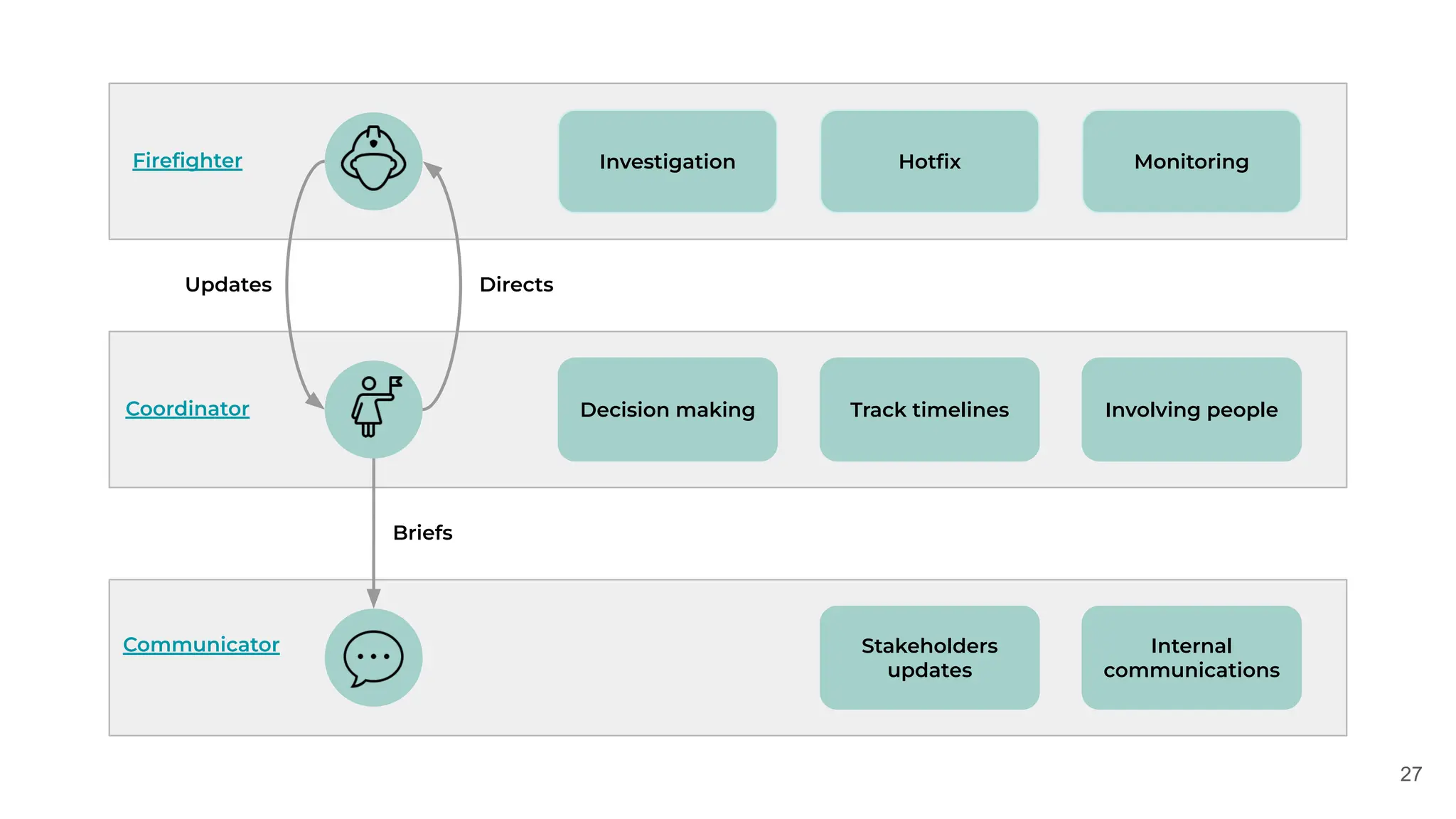
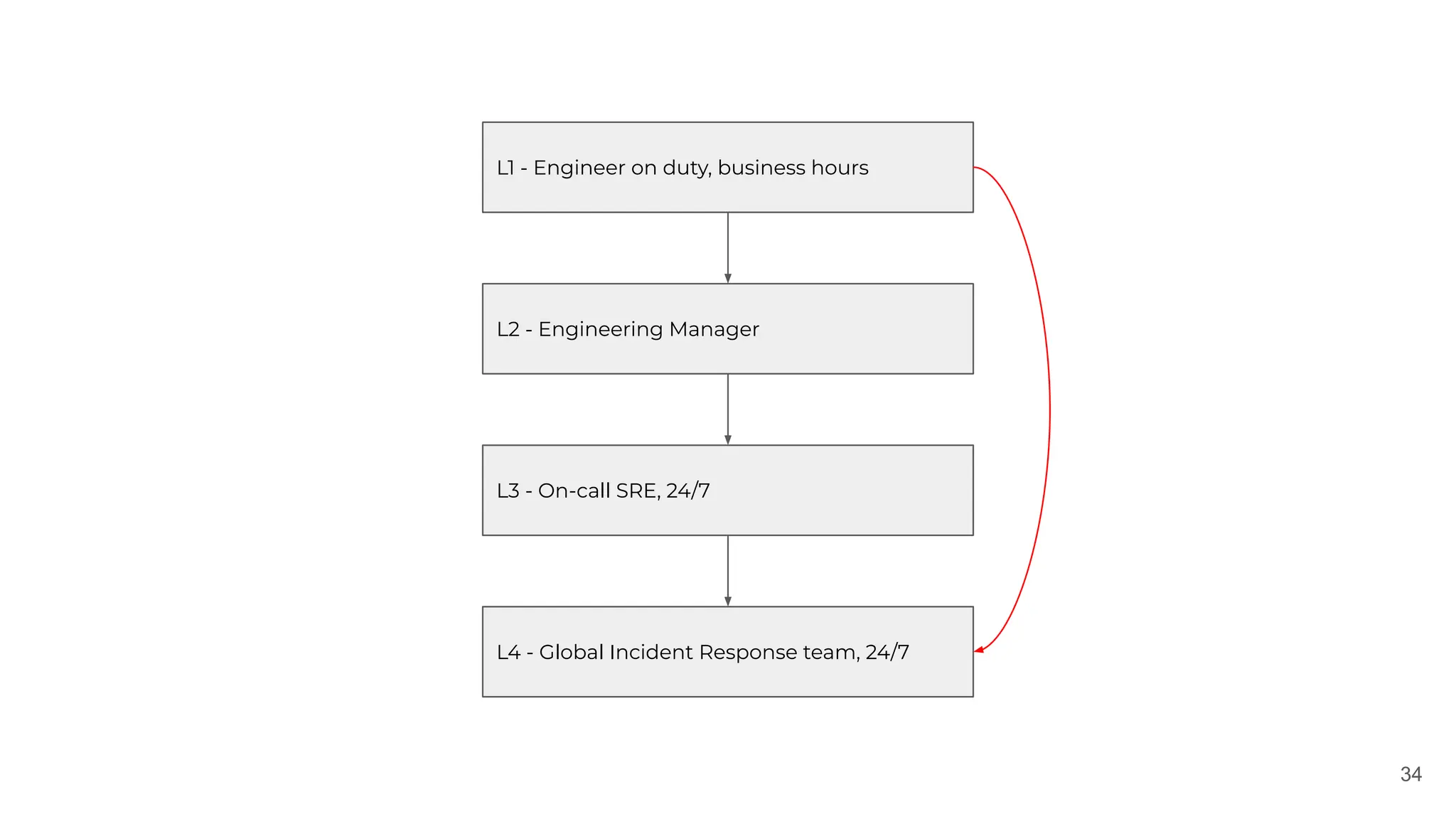
✅Assign roles
Make sure everyone is aware of its responsibility
✅[Communicator] Keep audience updated
Ensure timely updates in public channels
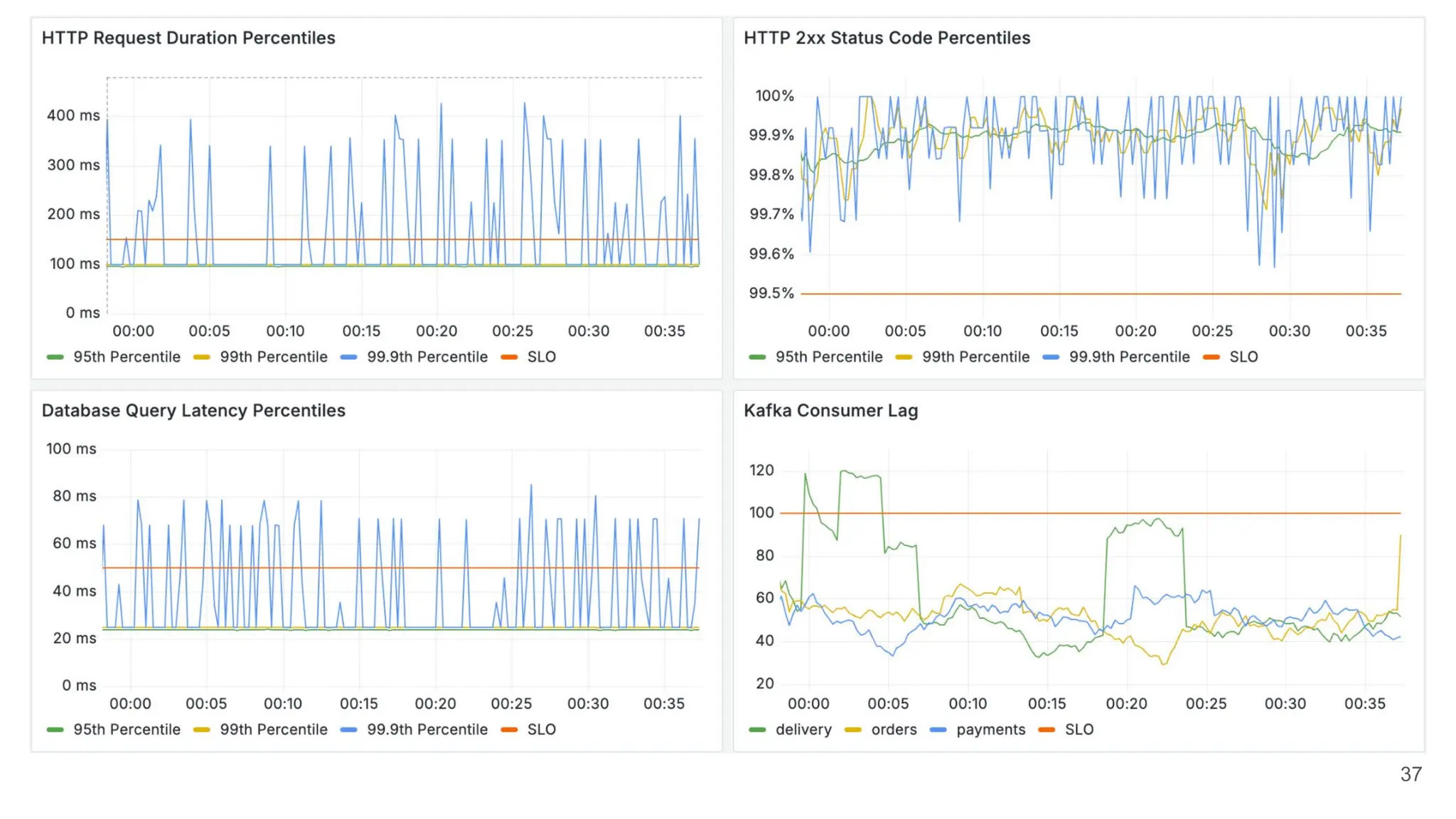
✅[Firefighter] Open firefighting dashboard
It is your entry point to the incident investigation
…
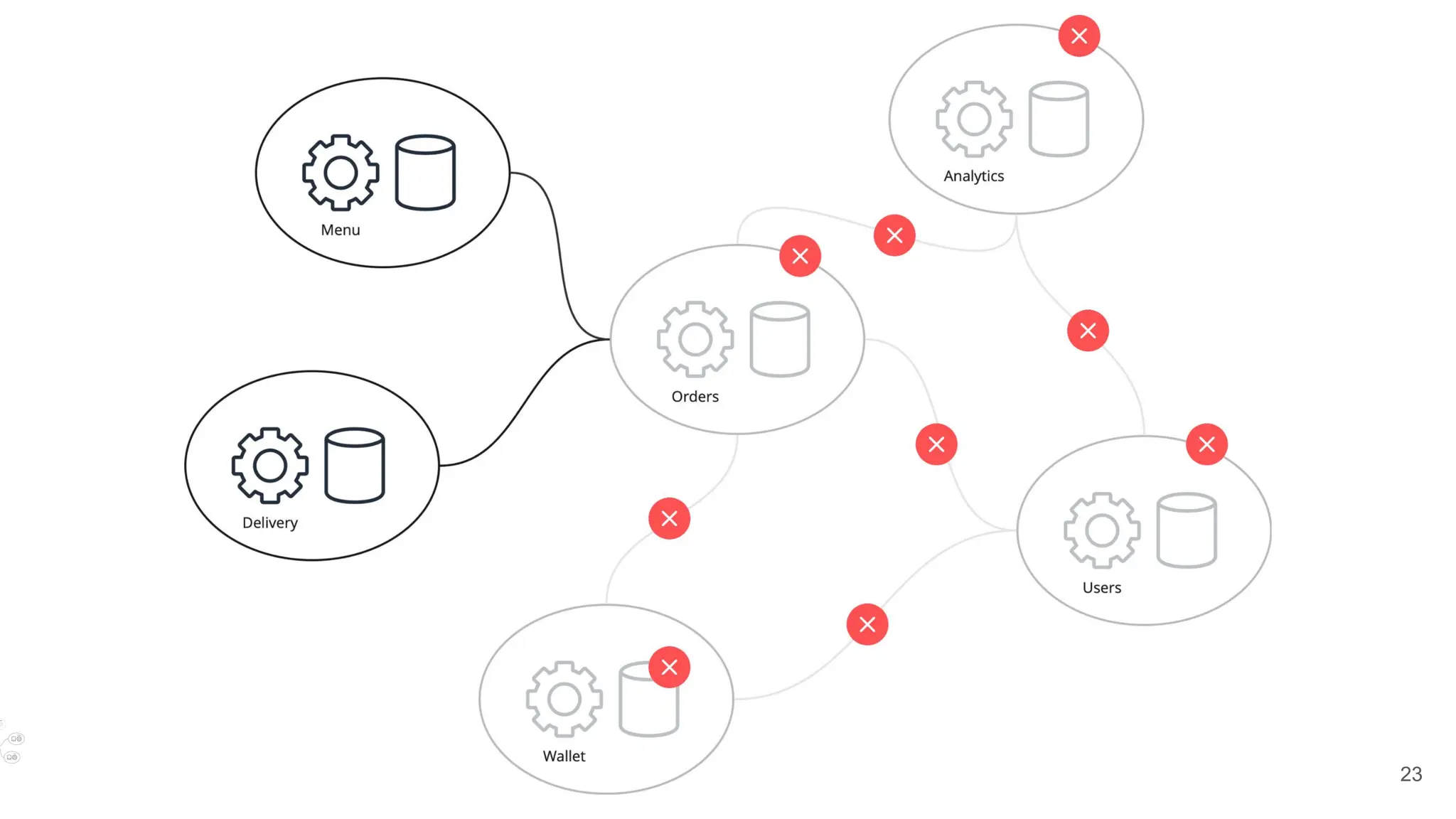
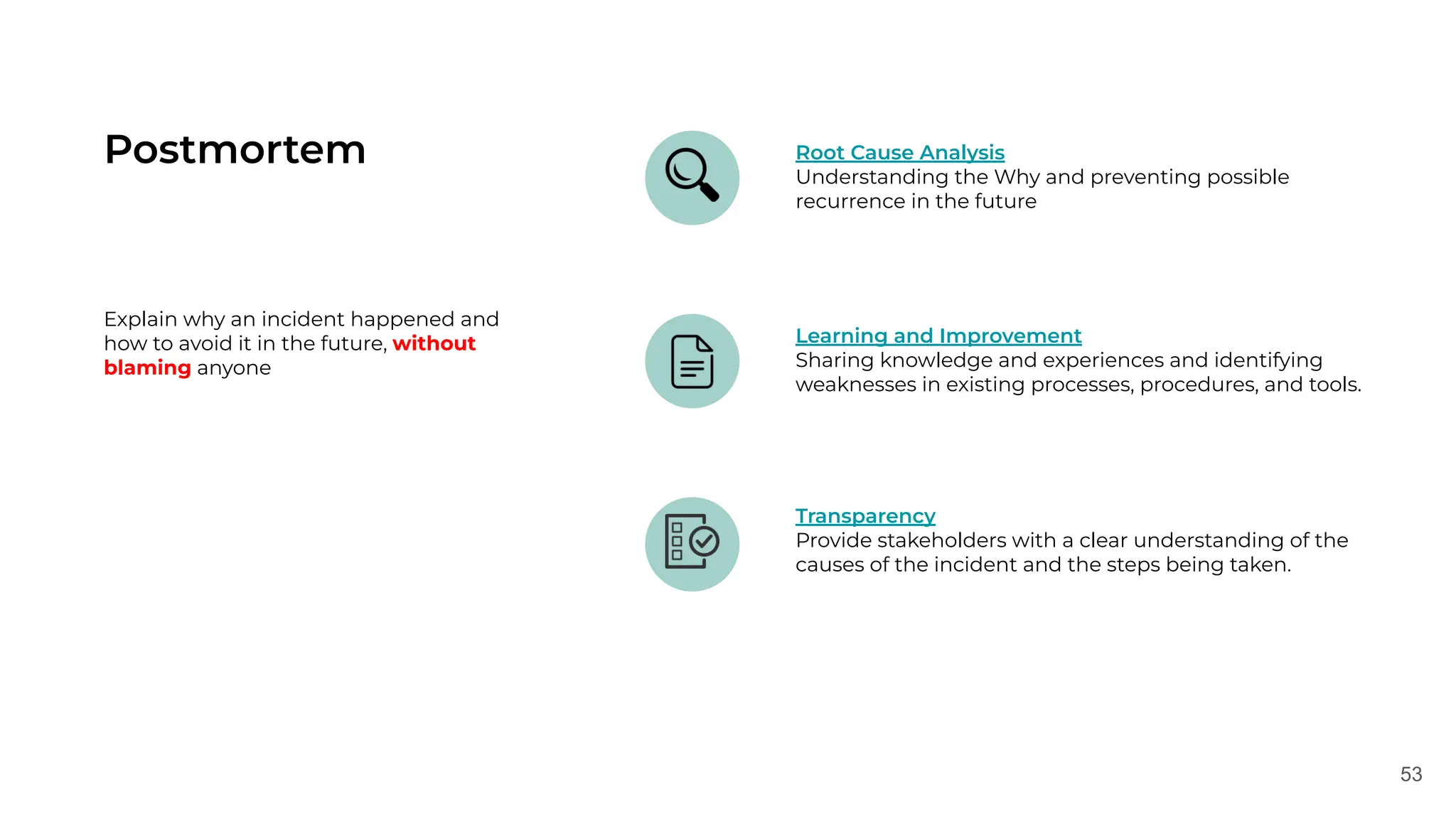
✅Close incident
Update the status and initiate postmortem](https://image.slidesharecdn.com/slidesdaniildoronkin2024-241202140744-dc979e05/75/OSMC-2024-The-story-of-firefighting-learnings-from-the-incident-management-by-Daniil-Doronkin-pdf-45-2048.jpg)
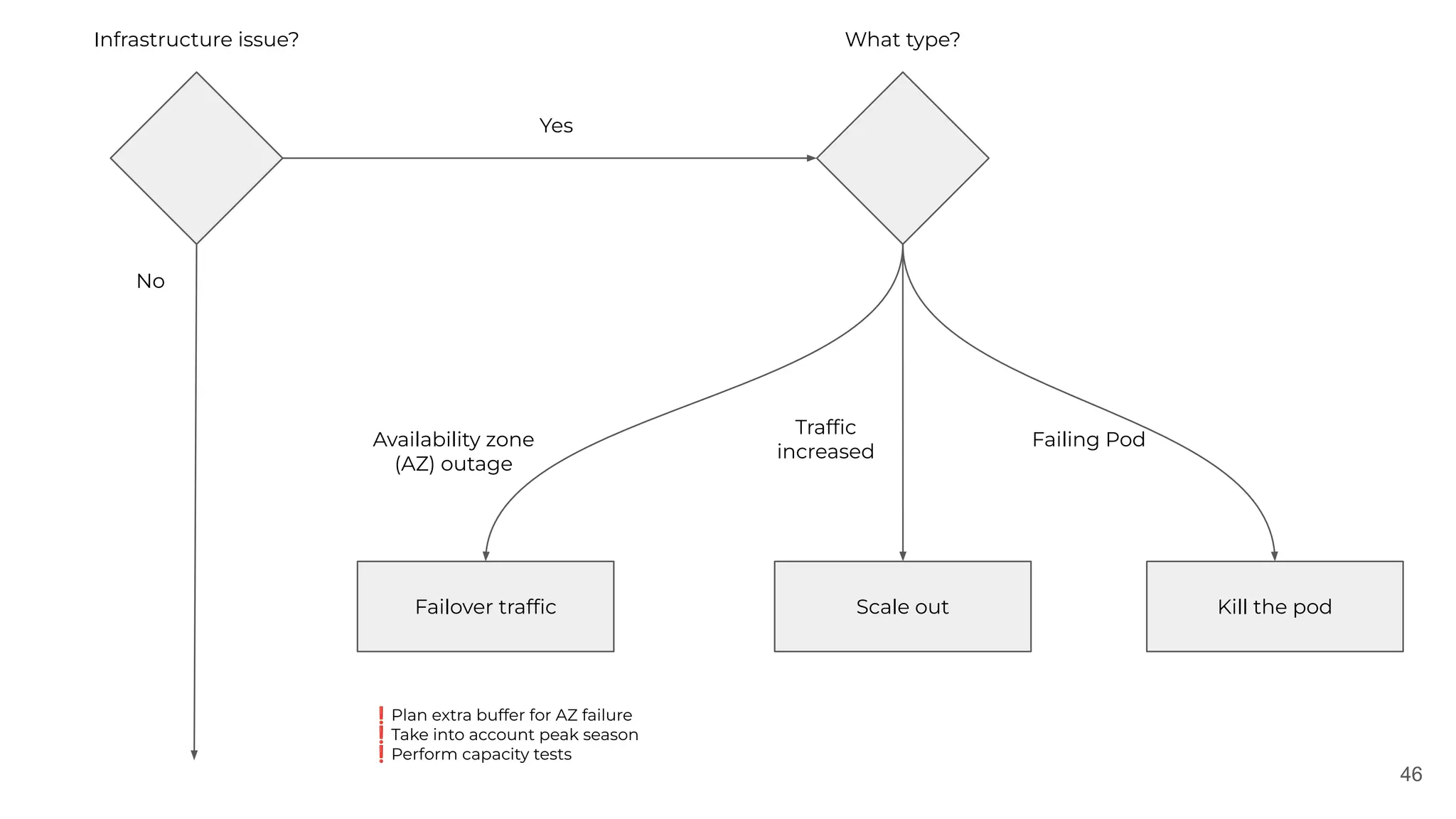
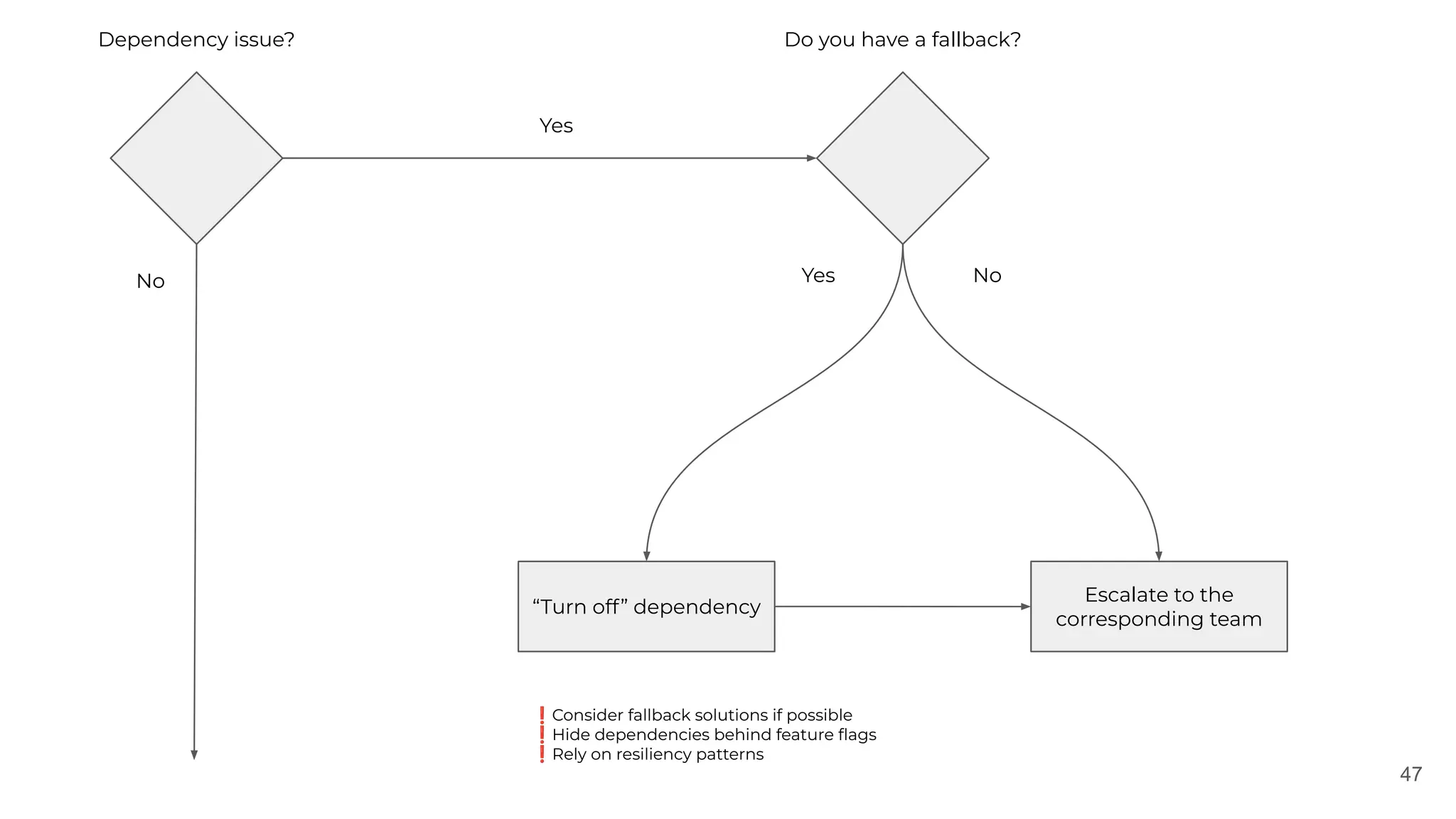
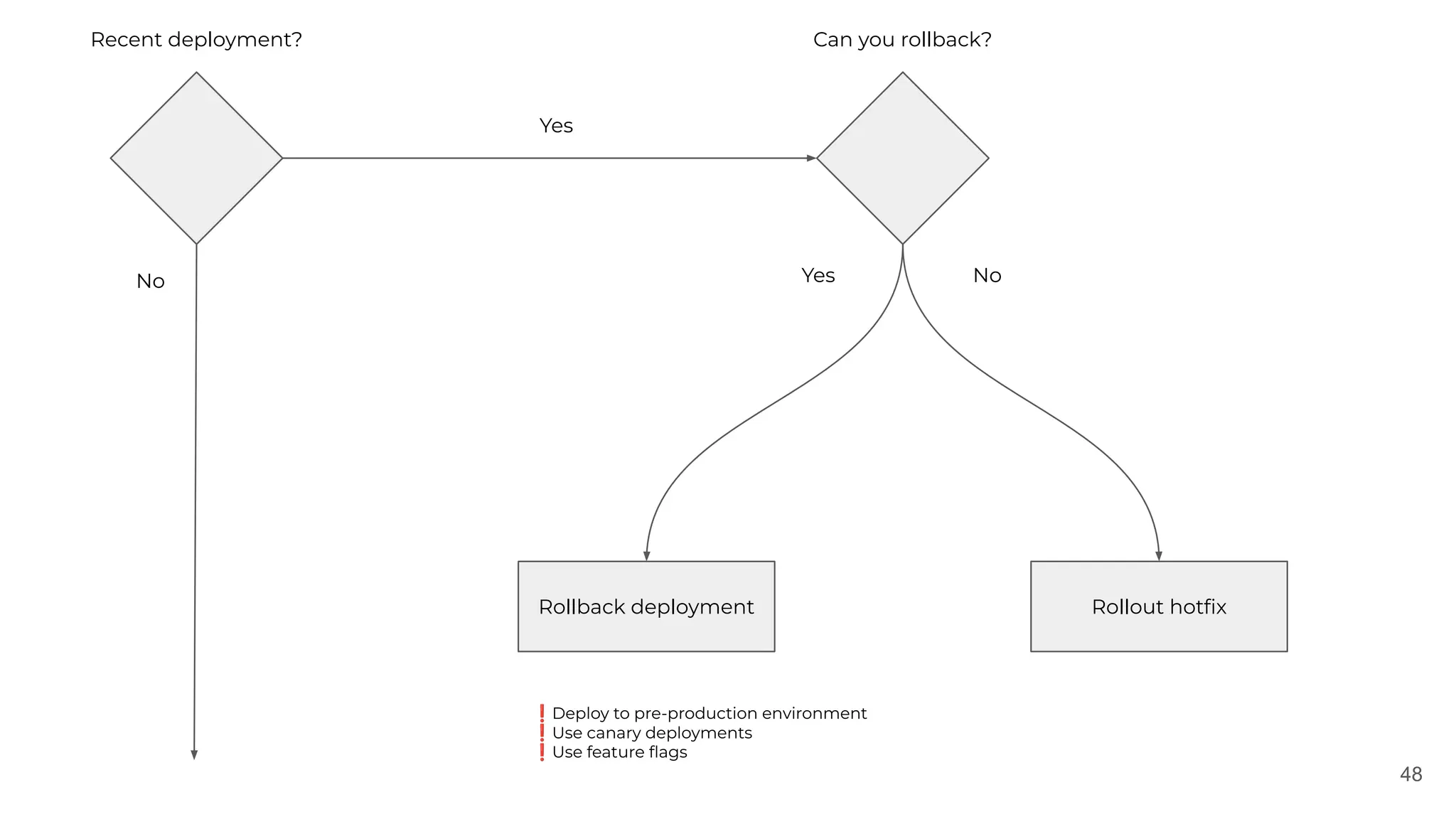
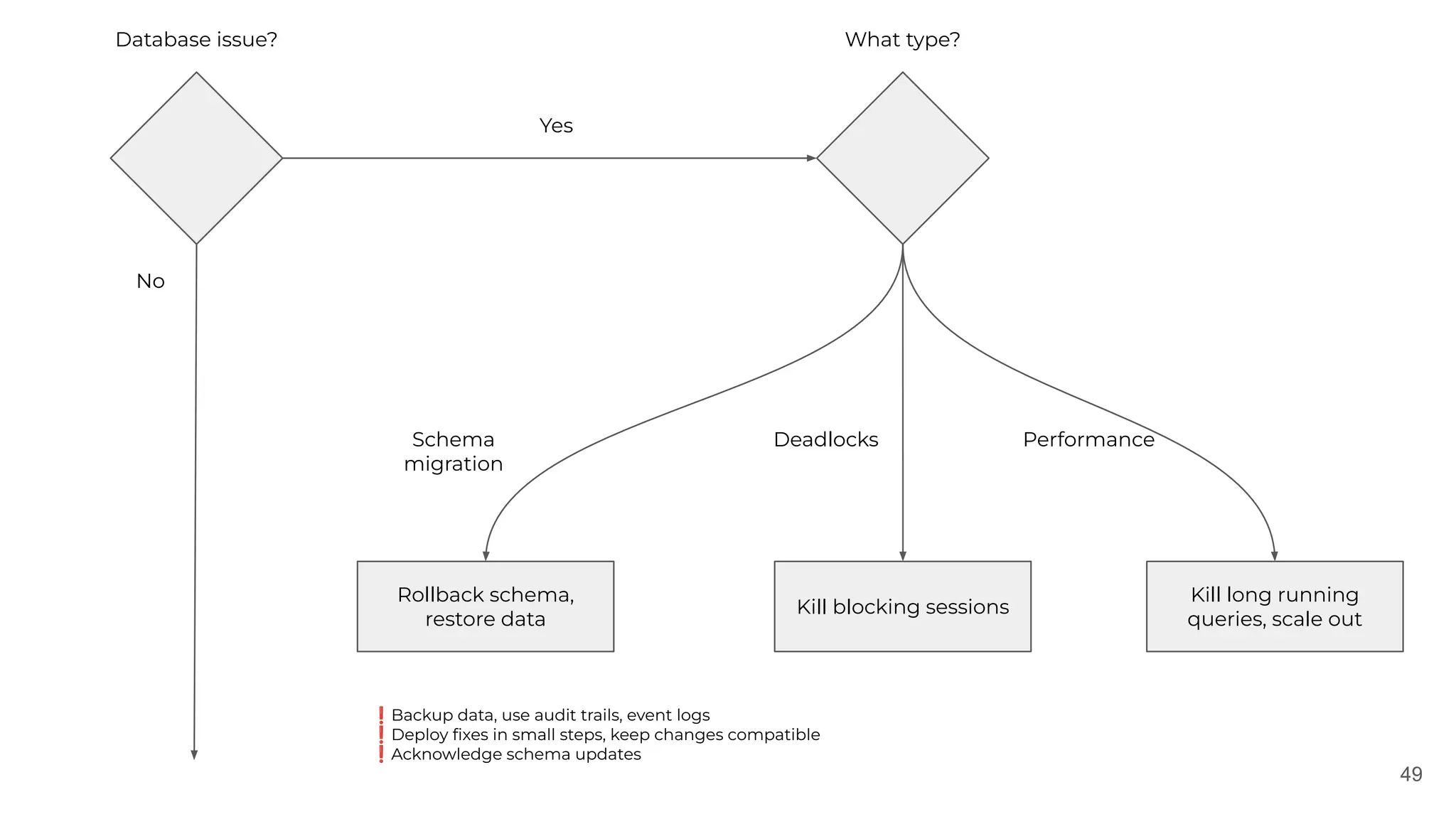










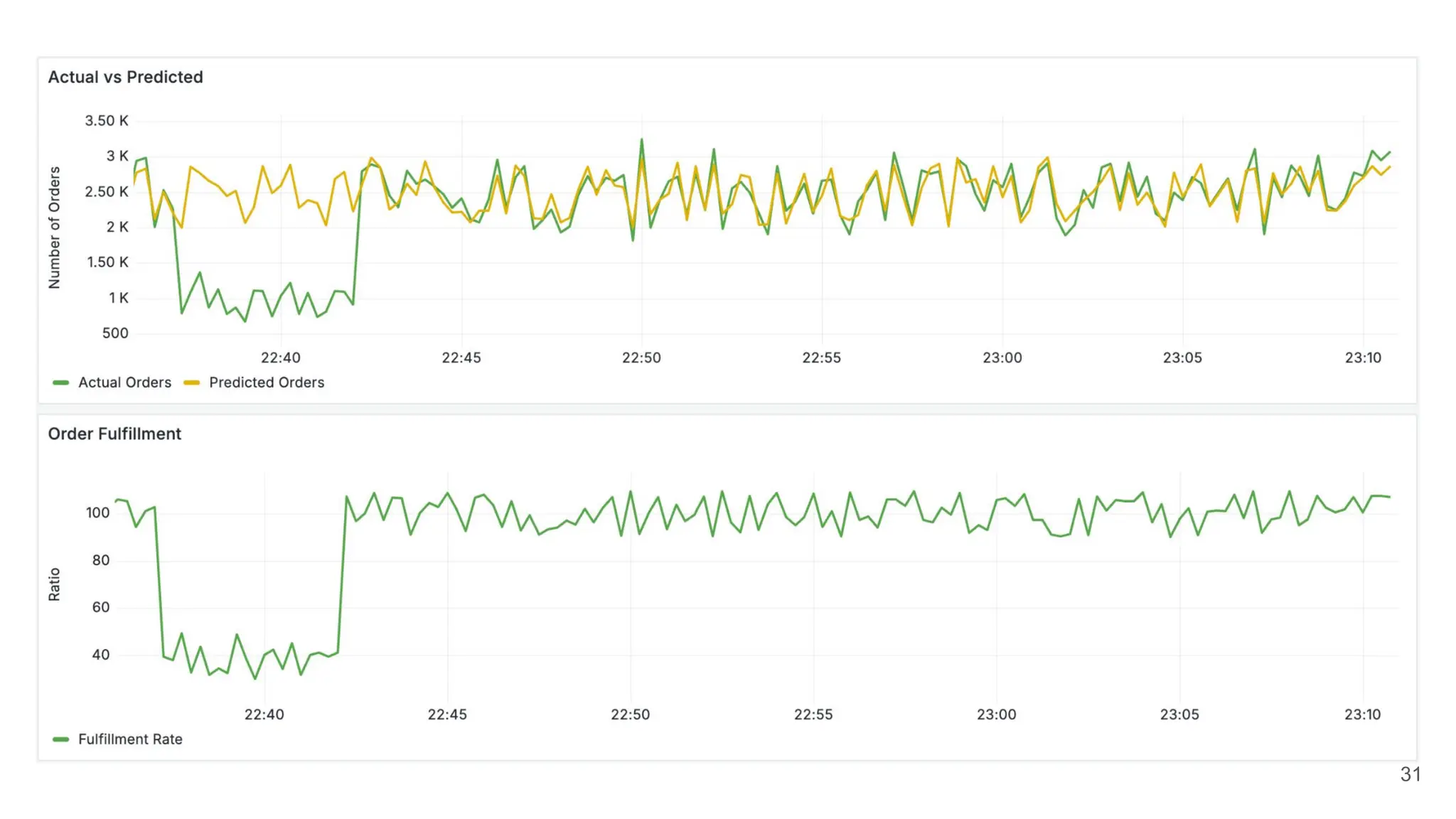
The document discusses the lessons learned from various incident management experiences, emphasizing the inevitability of incidents in technology services and the need for effective response tools and collaboration. It covers key aspects such as incident prioritization, roles during incidents, continuous improvement through postmortems, and the use of AI tools for enhanced incident management. The emphasis is on creating a comfortable, well-equipped environment to facilitate quick and efficient incident resolution while ensuring future incidents are handled better through learnings from past events.















































