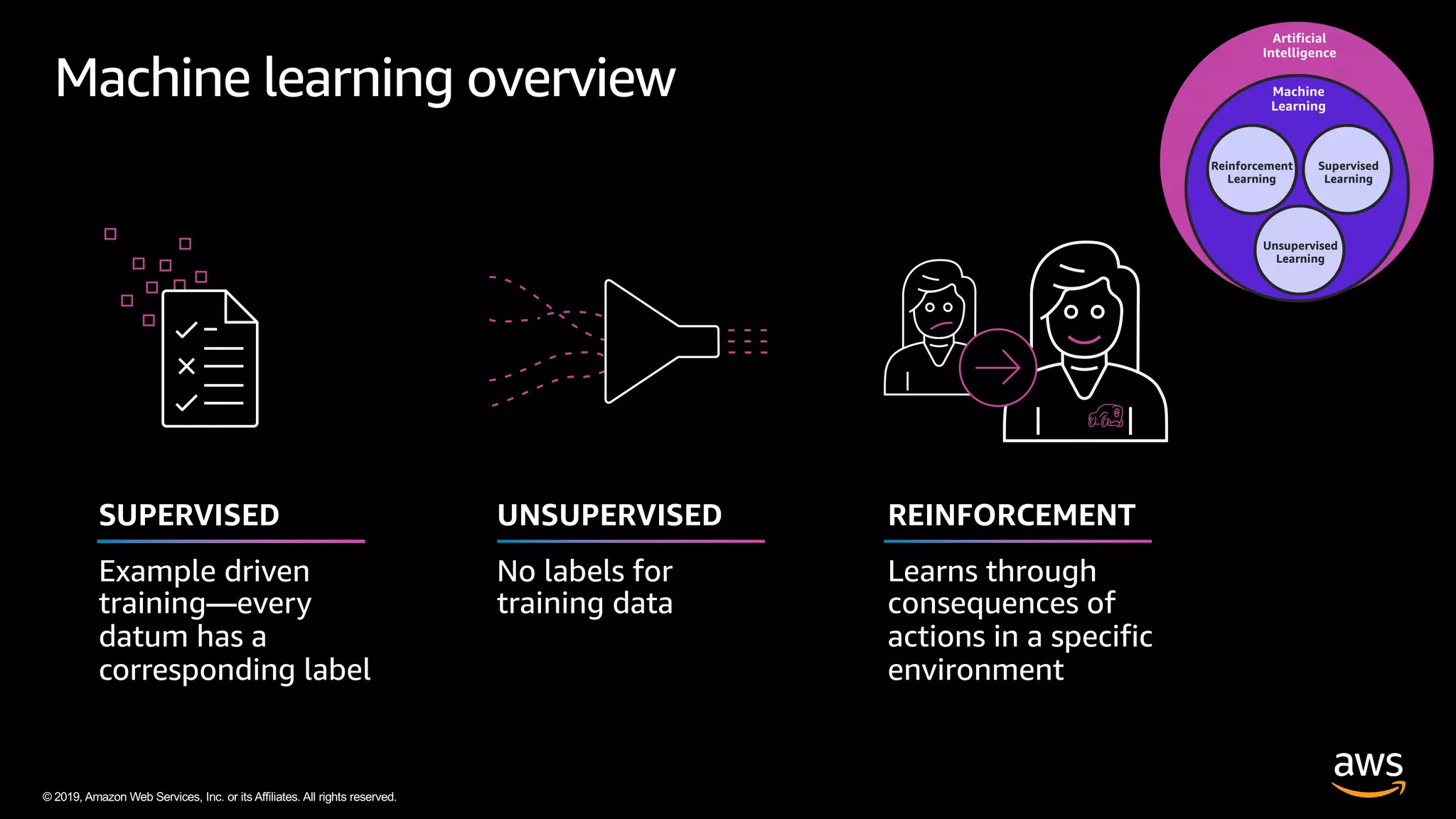
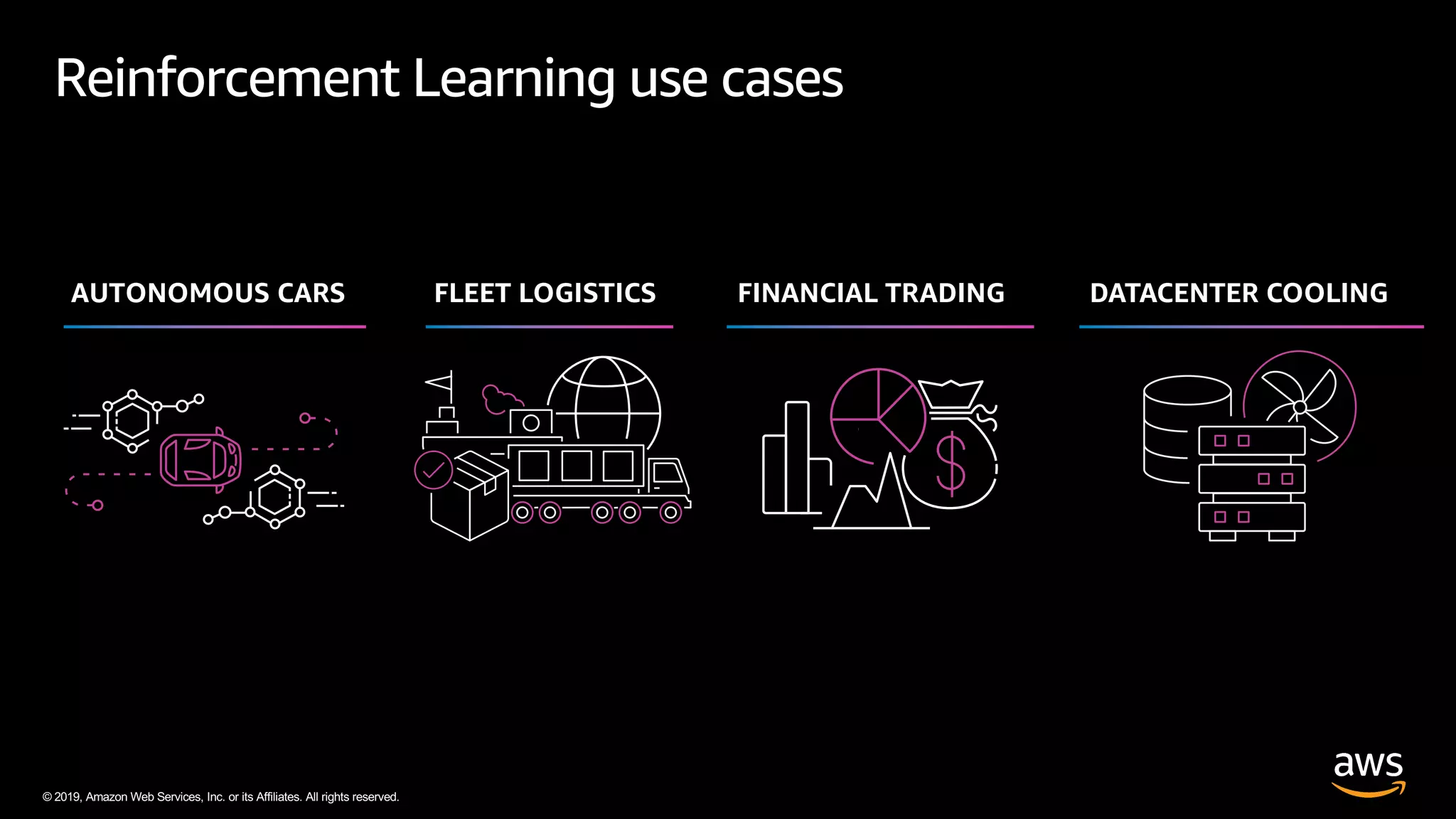
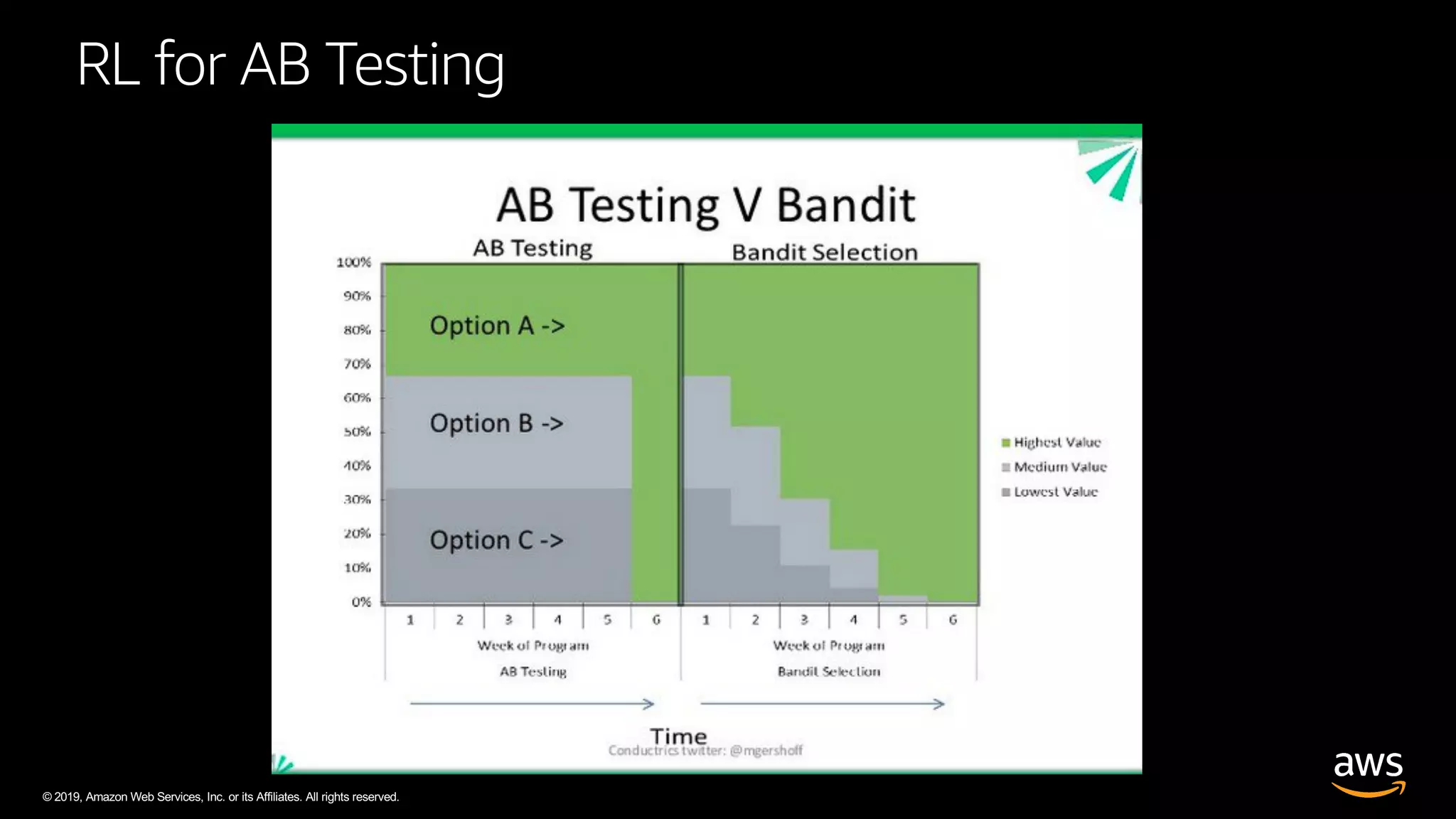
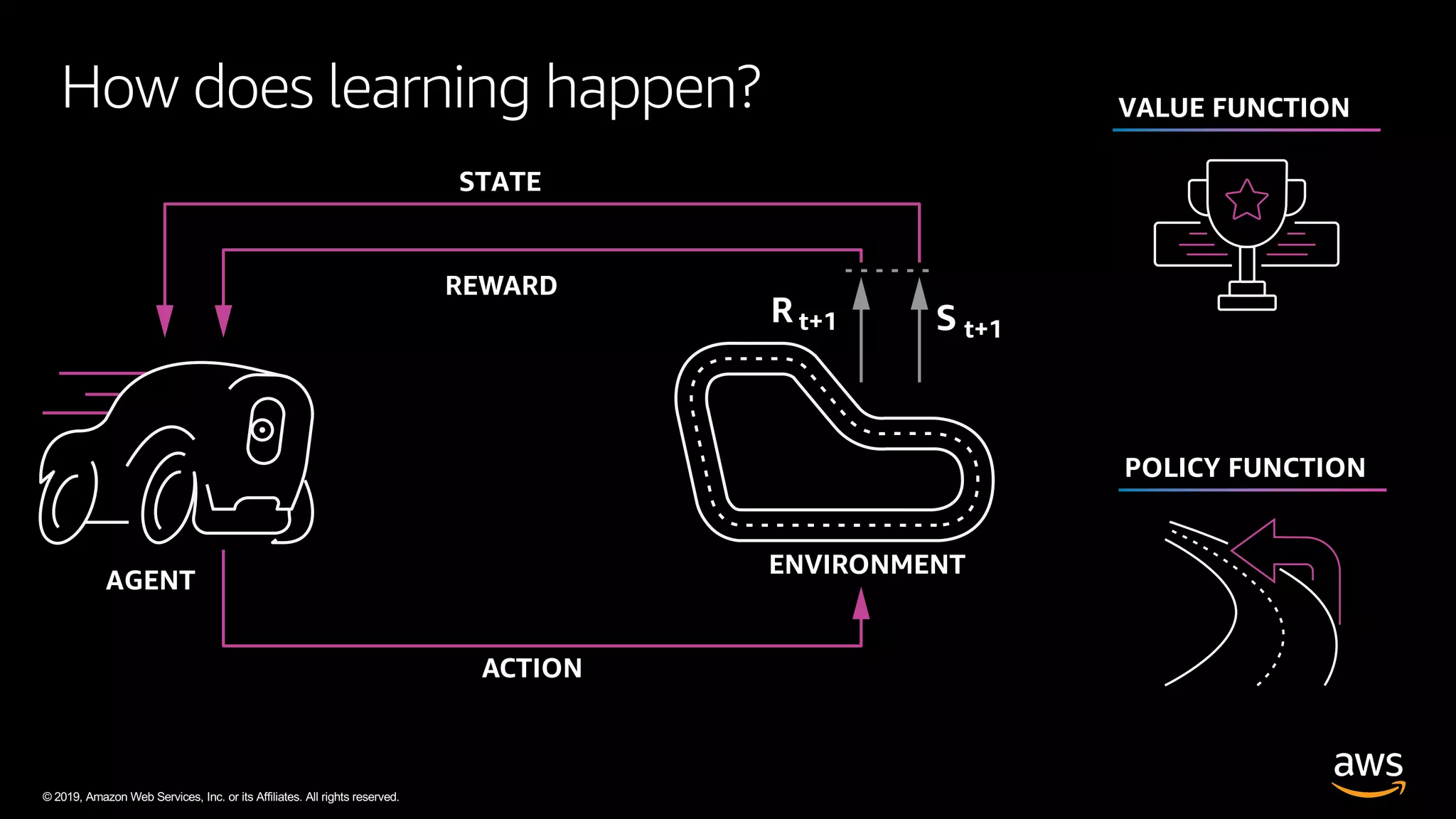
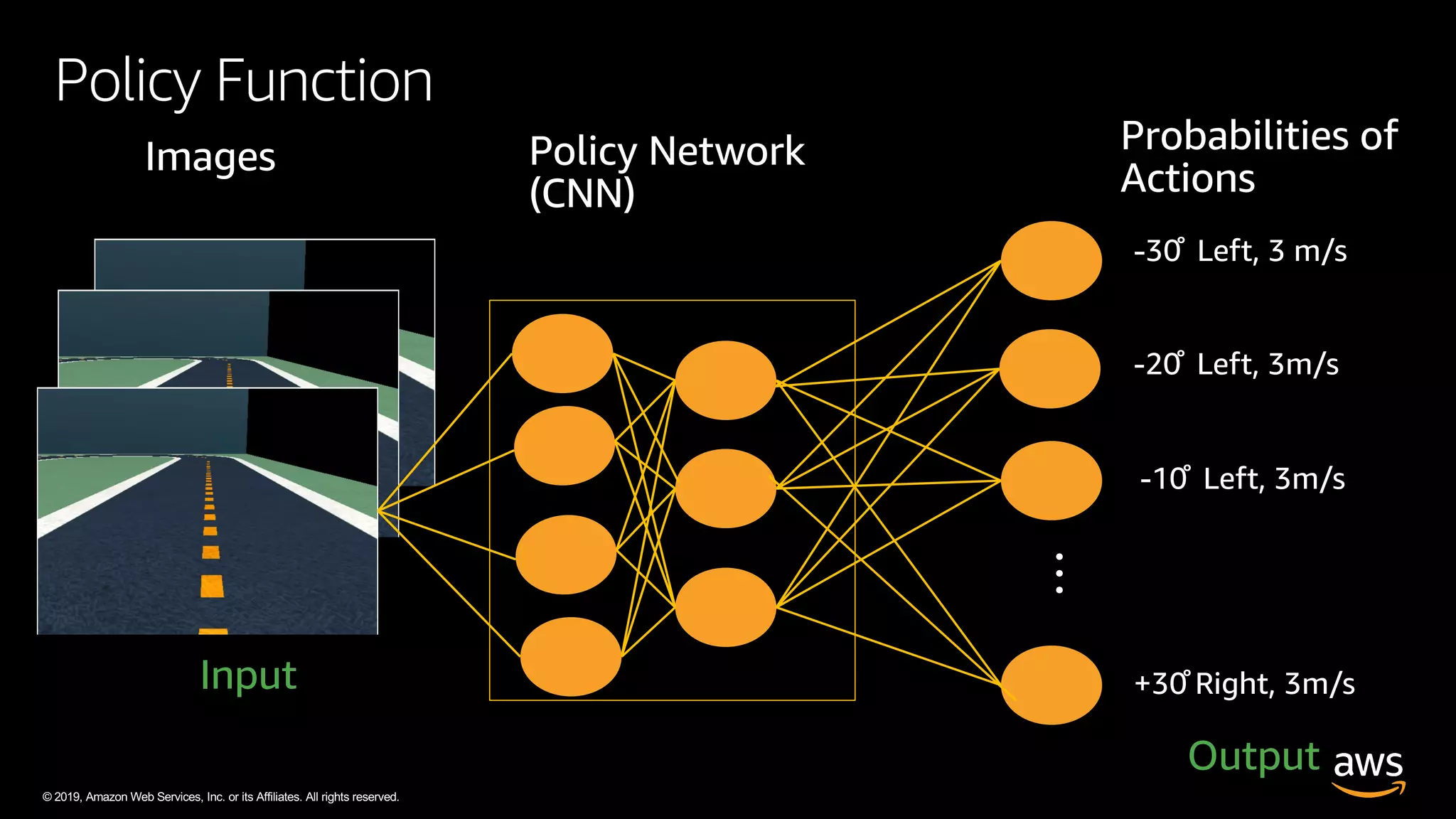
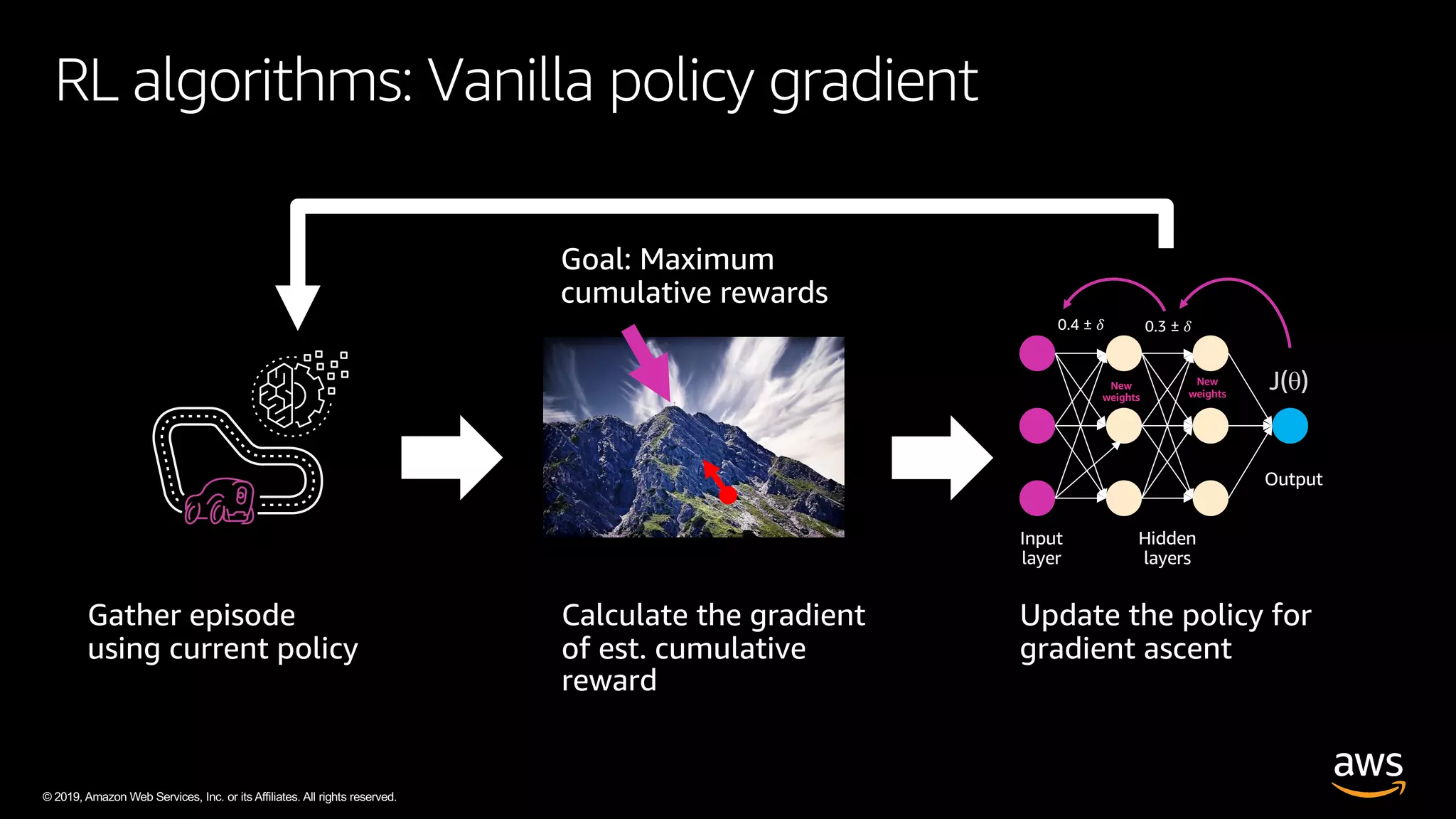
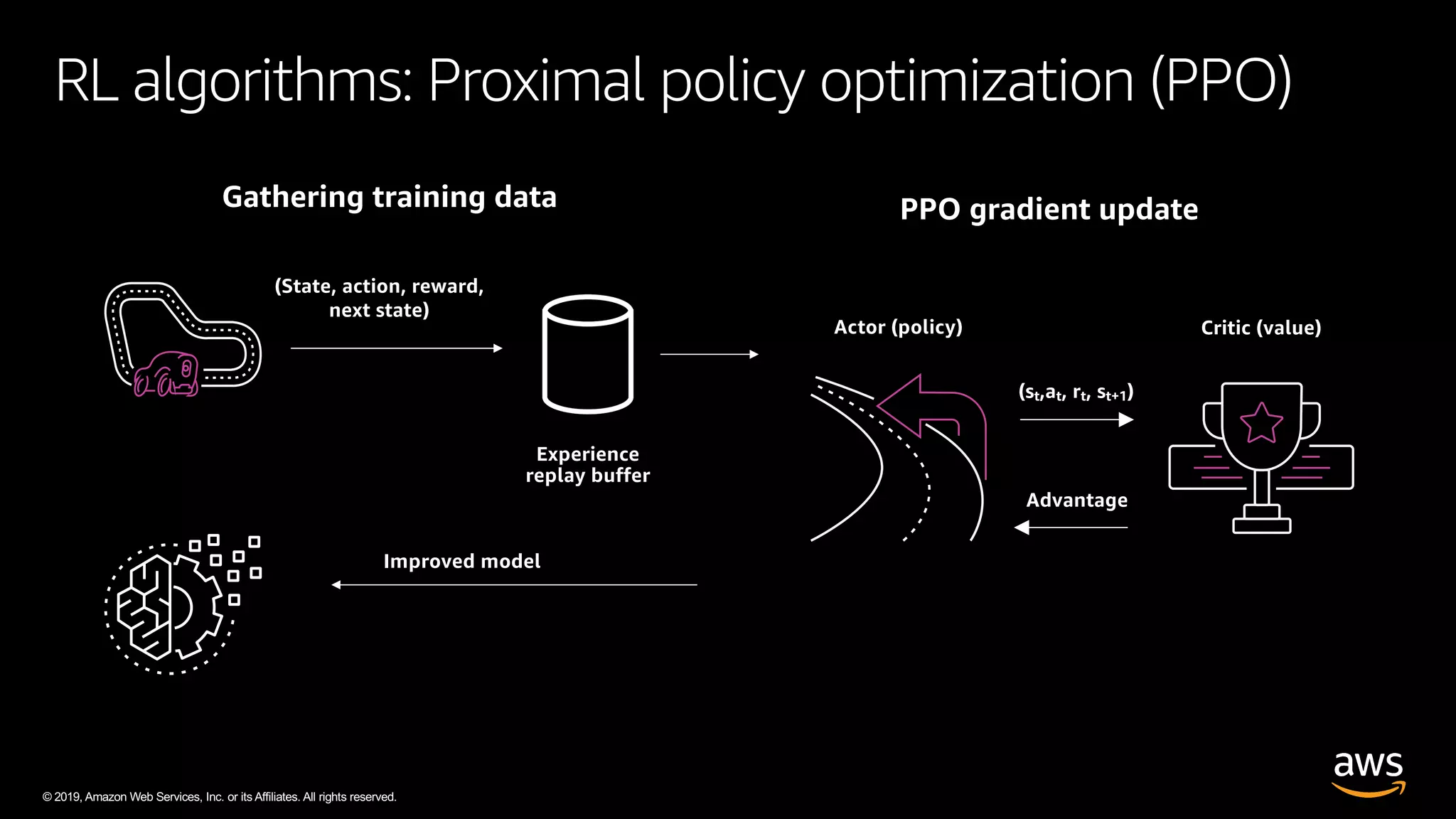
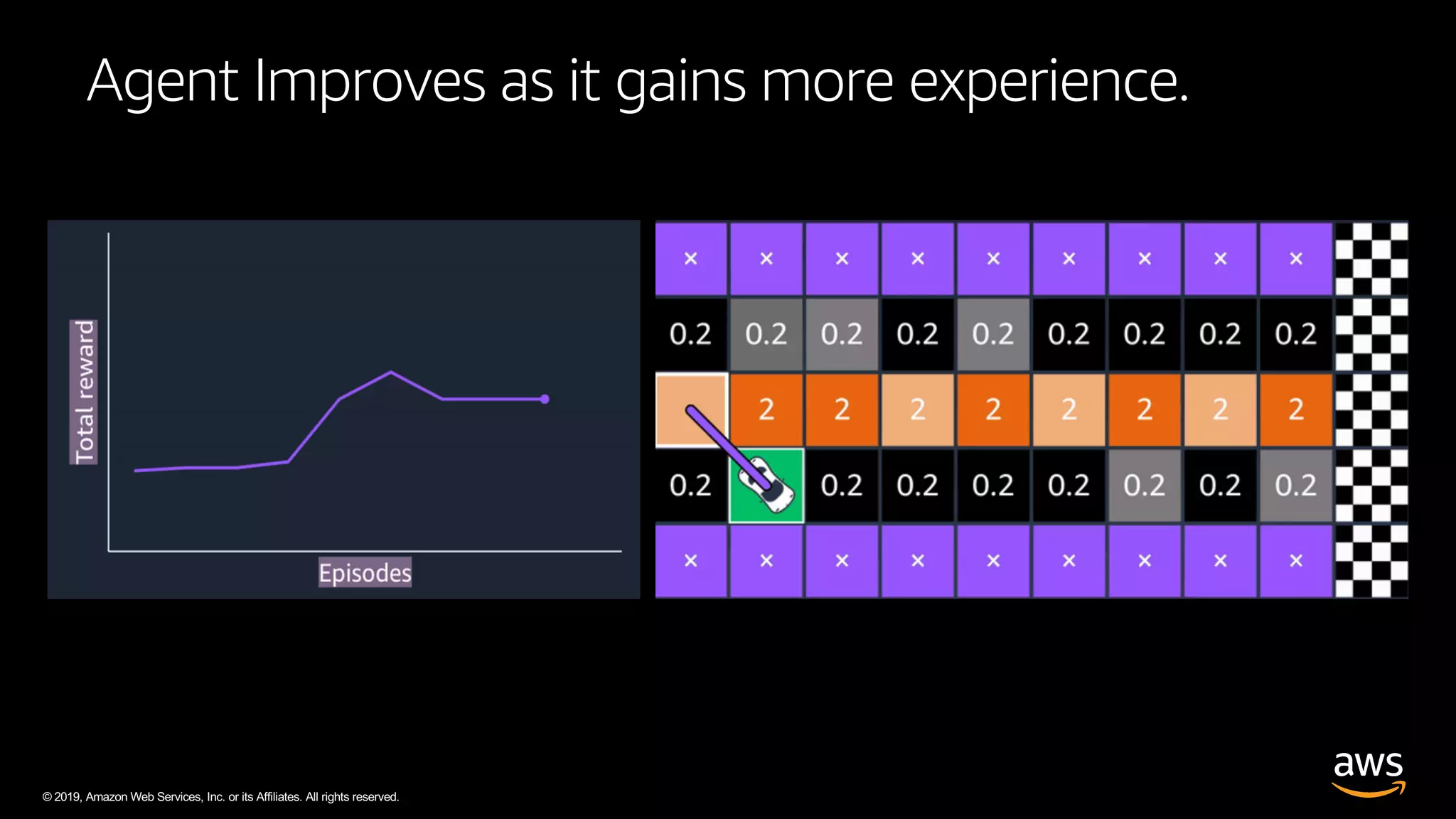
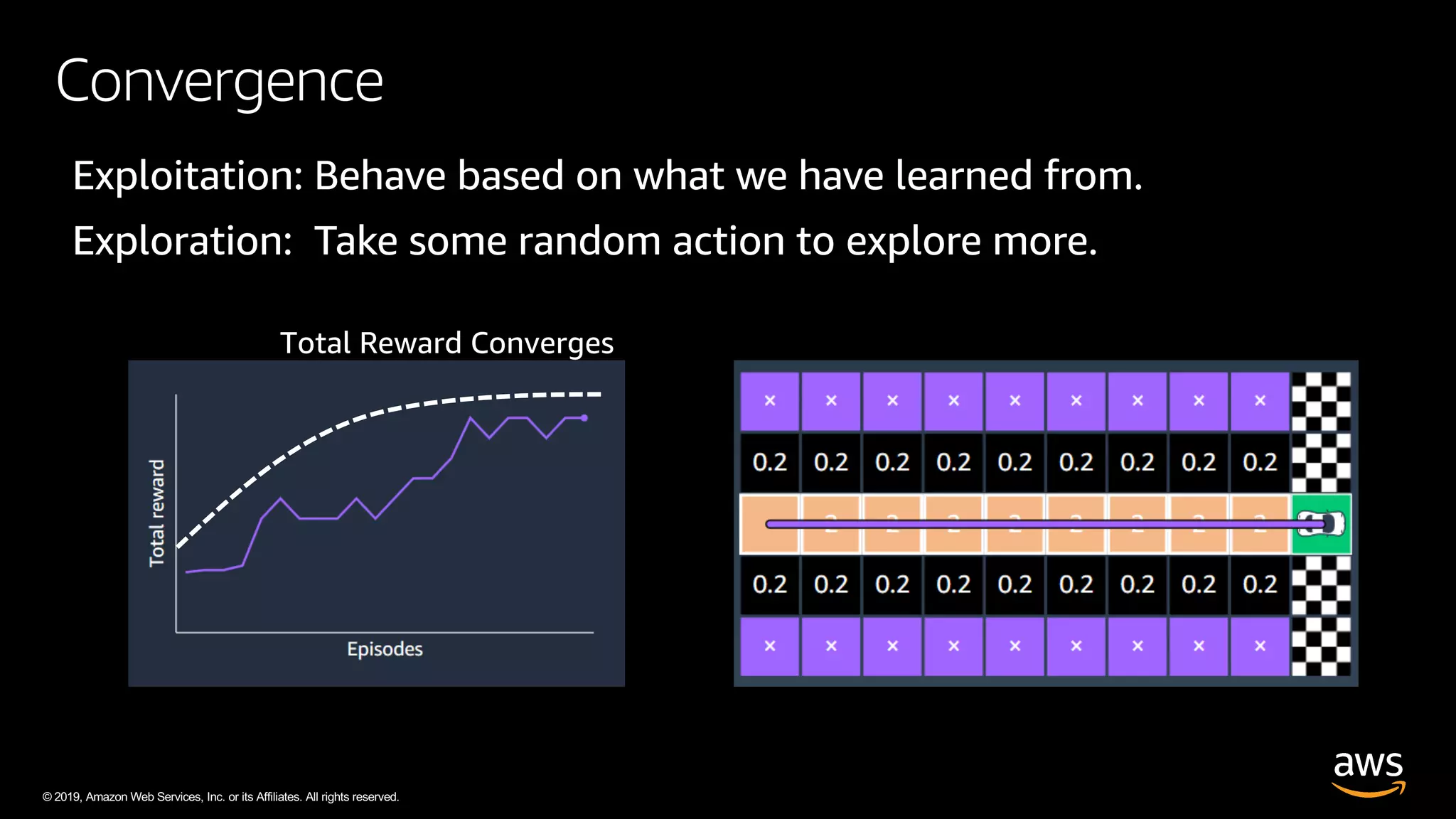
The document discusses AWS DeepRacer, a platform using reinforcement learning to enable developers to create and train autonomous racing cars. It outlines the concepts of reinforcement learning, including the roles of agents and environments, and emphasizes the importance of experience in model training. The document also covers the application of reinforcement learning in various fields such as autonomous vehicles and financial trading.





































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)


















