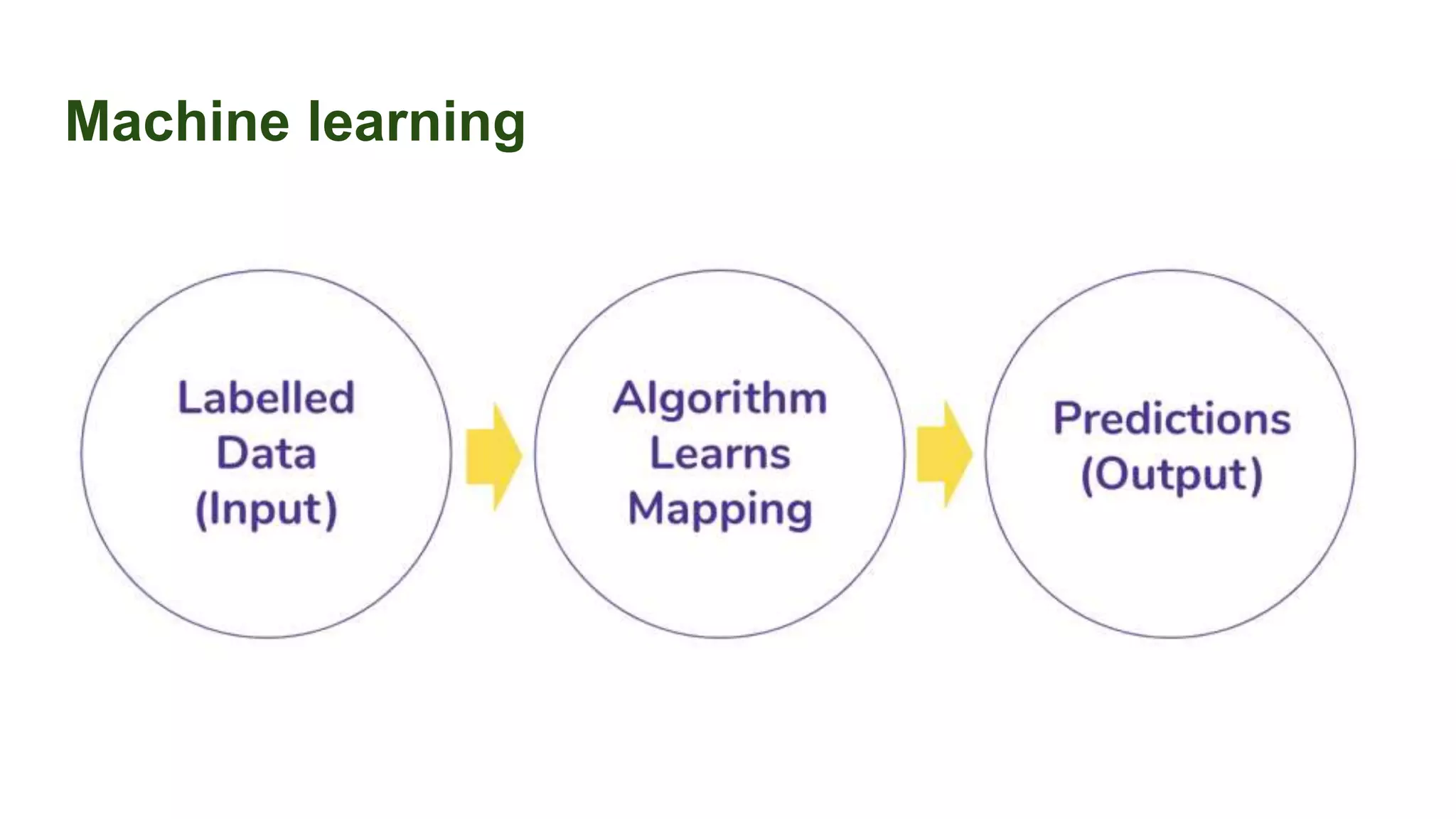
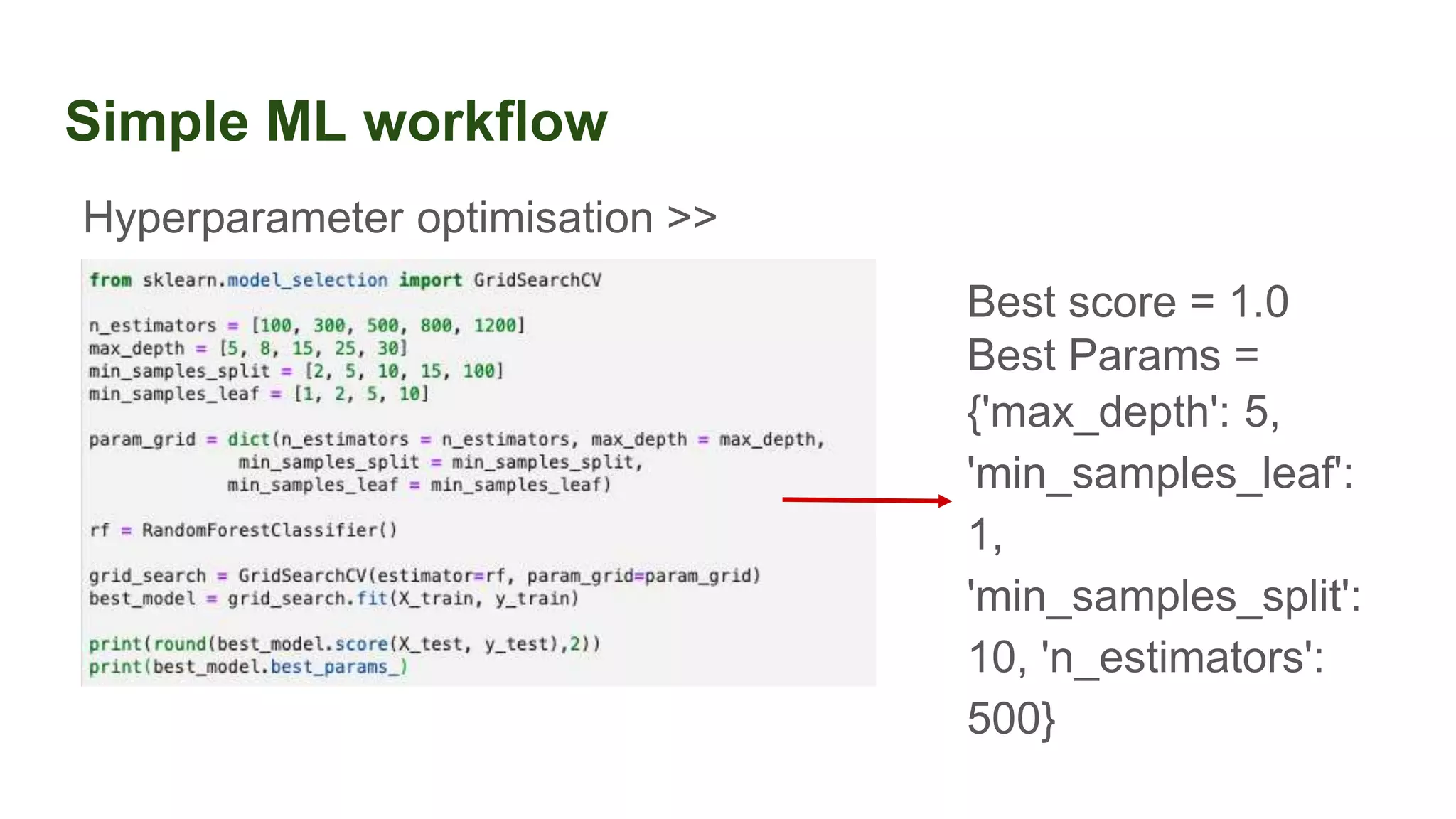
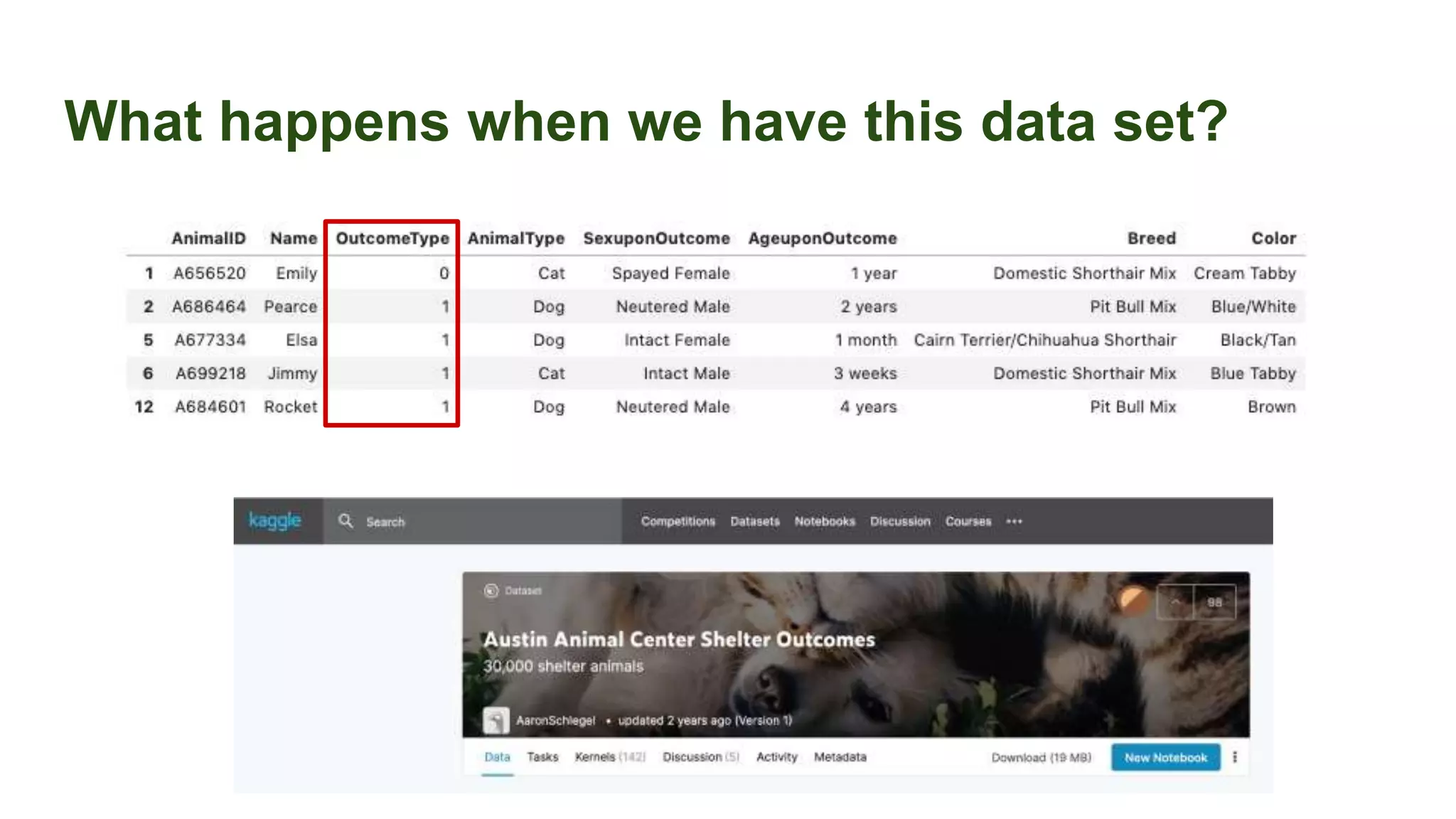
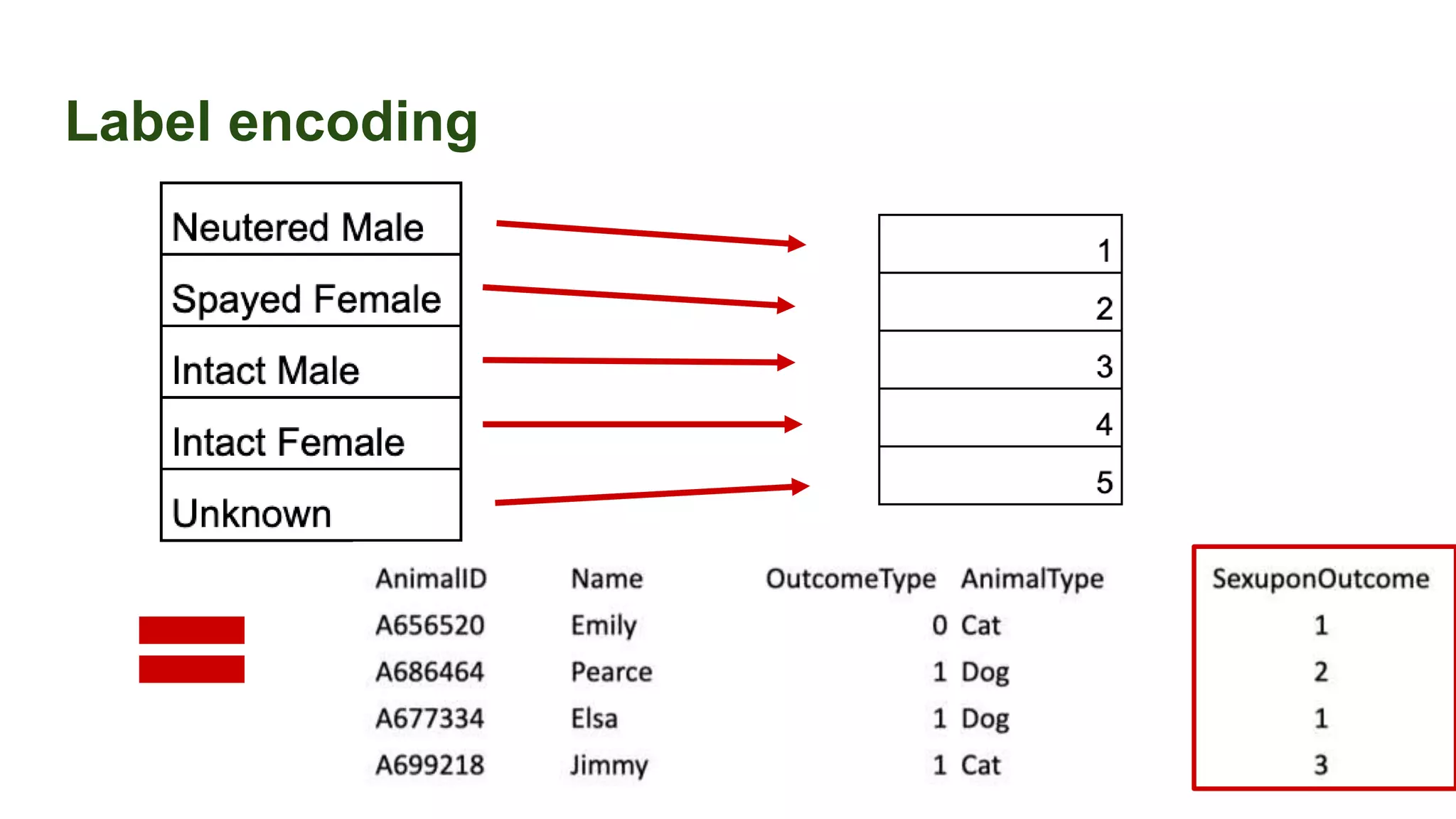
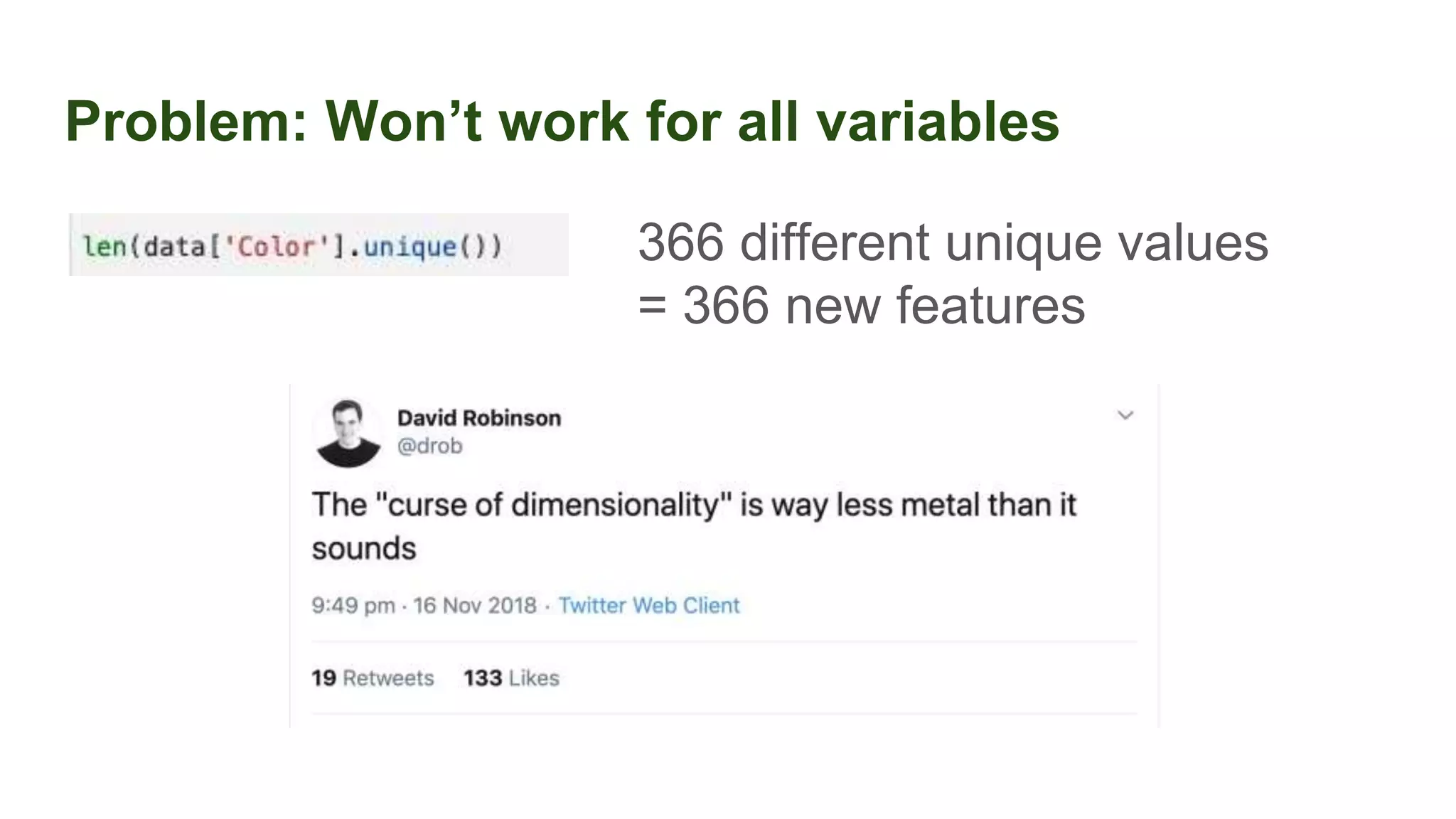
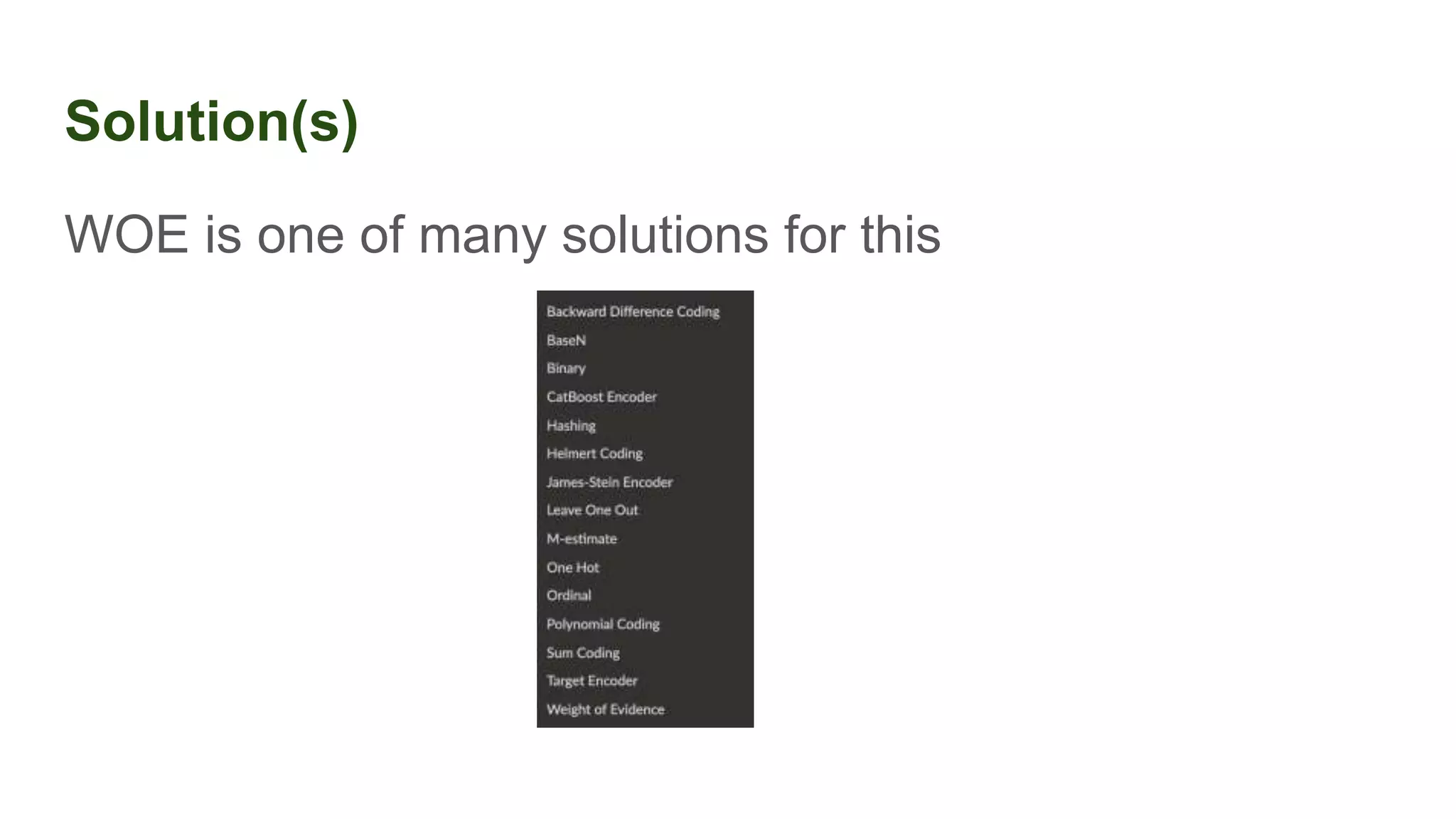
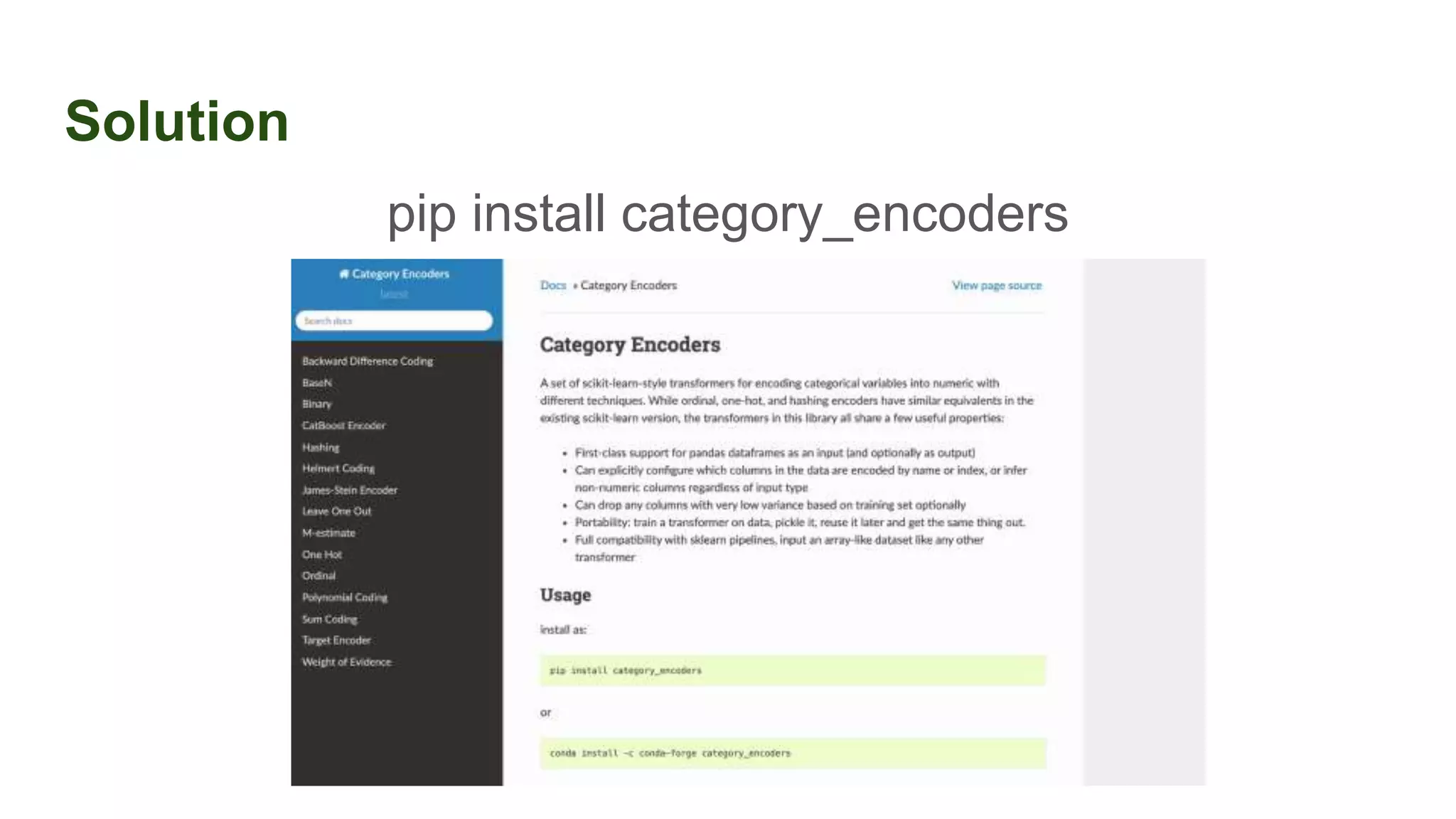
This document discusses the importance of data preparation for machine learning models. It outlines the typical machine learning workflow of getting data, preparing it through tasks like feature engineering, building baseline models, selecting the best model, and tuning hyperparameters. Specific challenges in data preparation like label encoding, one-hot encoding, and handling categorical variables with many values are described. Solutions to these challenges through techniques like weight of evidence and scikit-learn pipelines are also presented. The document emphasizes that much of a machine learning project's time should be spent on data preparation to develop high-quality inputs that allow models to learn effectively from the data.