Downloaded 29 times



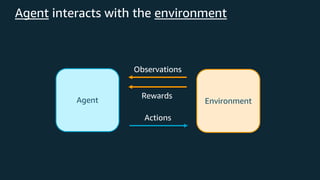
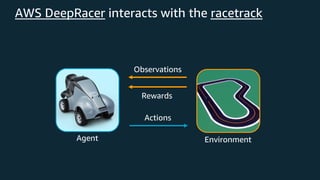





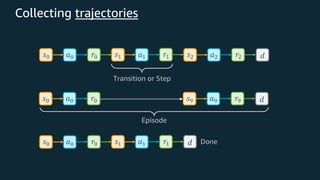





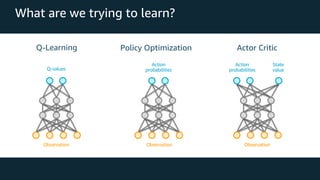

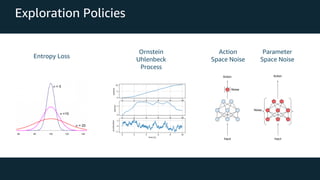





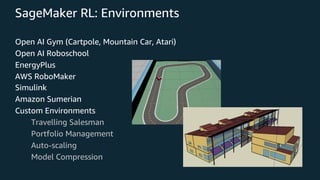
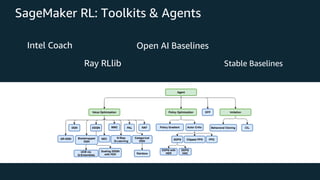

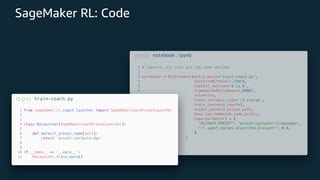




This document provides an overview of reinforcement learning and Amazon SageMaker RL. It discusses key RL concepts like the reinforcement learning loop, exploration vs exploitation, and common algorithms like DQN and PPO. It then introduces SageMaker RL as a way to simplify RL training through prebuilt environments, agents, and tools to train models on complex tasks without having to implement algorithms from scratch. SageMaker RL handles challenges like unstable training, sparse rewards, and hyperparameters through its presets, toolkits, and managed infrastructure for computationally expensive RL training.















































