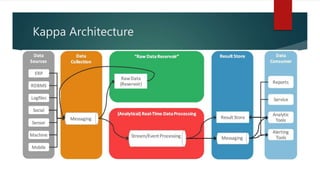
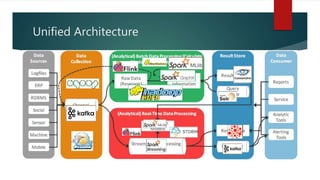
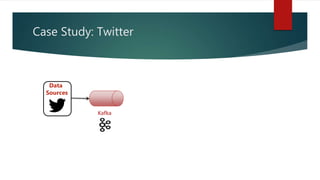
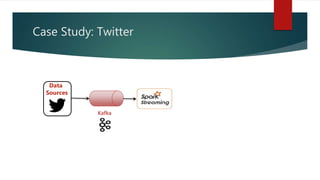
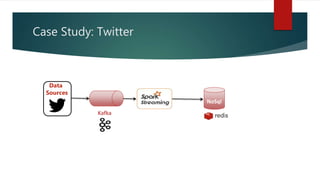
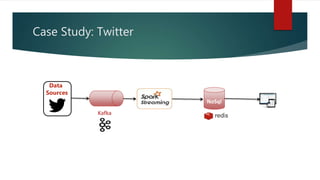
This document discusses real-time data and real-time systems. It defines real-time systems as systems where the correctness depends on both the logical result and the time the result is produced. Real-time systems must respond to events in a fast and predictable way. The document discusses soft, firm, and hard deadlines and gives examples of hard real-time systems like nuclear reactor control. It also discusses challenges in validating that a real-time system can meet all its timing constraints and potential solutions like real-time operating systems and distributed systems.


































































![RTOS [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/rtosautosaved-230324171425-3bb3b10a-thumbnail.jpg?width=640&height=640&fit=bounds)













































