Downloaded 65 times



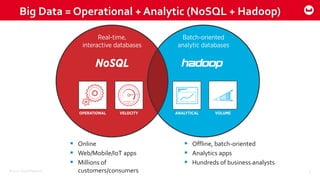





![©2015 Couchbase Inc. 11
User Object
string uid
string firstname
string lastname
int age
array favorite_colors
string email
u::john@couchbase.com
{ “uid”: 123456,
“firstname”: “John”,
“lastname”: “Smith”,
“age”: 22,
“favorite_colors”: [“blue”, “black”],
“email”: “john@couchbase.com”
}
User Object
string uid
string firstname
string lastname
int age
array favorite_colors
string email
u::john@couchbase.com
{ “uid”: 123456,
“firstname”: “John”,
“lastname”: “Smith”,
“age”: 22,
“favorite_colors”: [“blue”, “black”],
“email”: “john@couchbase.com”
}
add()
get()
Objects Serialized to JSON and Back
©2014 Couchbase, Inc.](https://image.slidesharecdn.com/couchbase101couchbaseconnect15-170727193458/85/Couchbase-101-11-320.jpg)
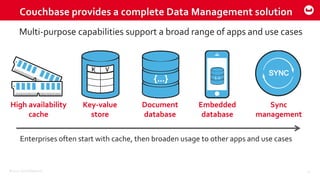
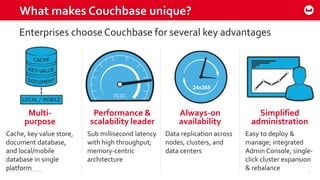
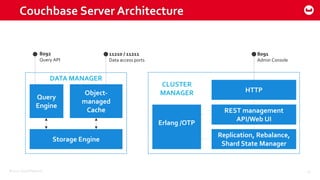
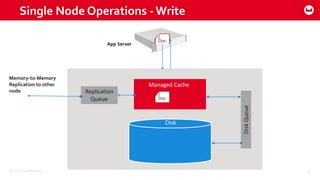
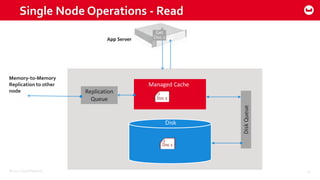
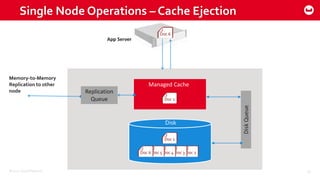
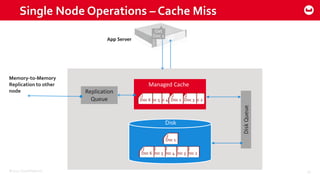


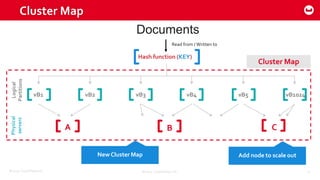
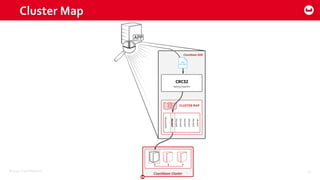
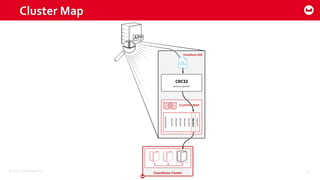
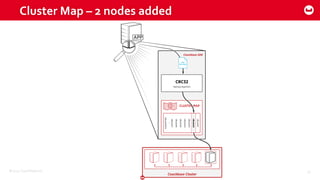
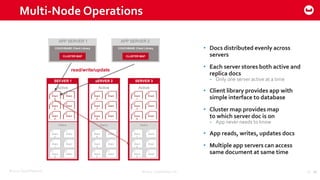
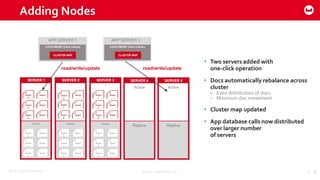
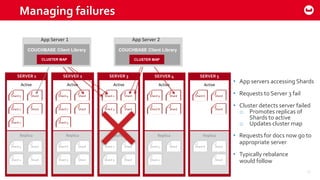


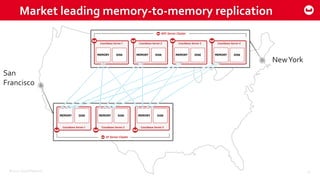
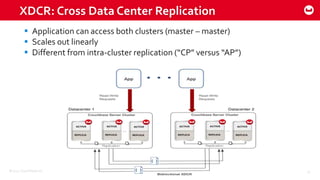
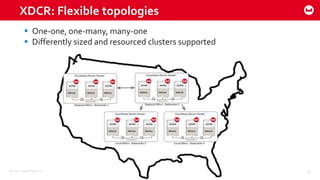
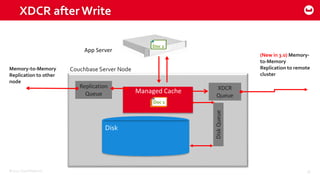

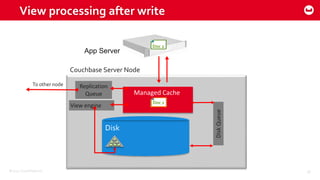
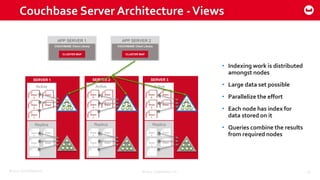
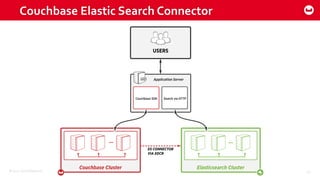
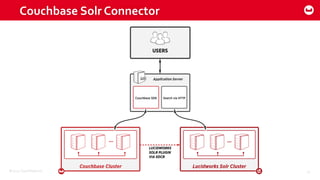




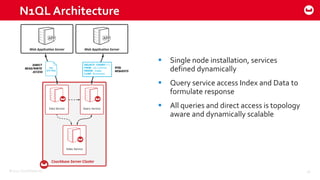




Couchbase 101 provides an overview of Couchbase including: - Key concepts of Couchbase such as its use as a key-value store and document store using JSON documents. - Single node and cluster-wide operations for reading, writing and updating documents. - Cross data center replication (XDCR) to replicate data between geographically distributed clusters. - Indexing and querying features including secondary indexes, views, and the new N1QL query language.




















































































