Download as PDF, PPTX






















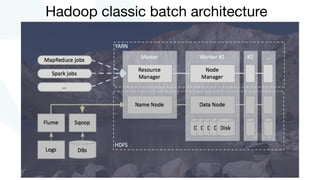
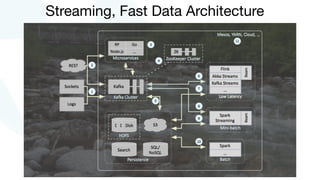
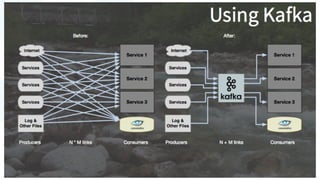






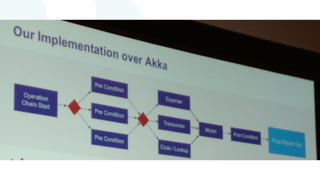
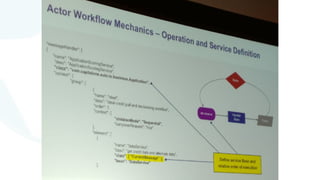






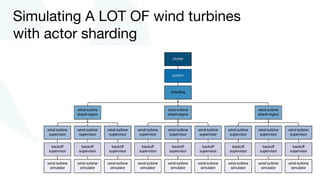
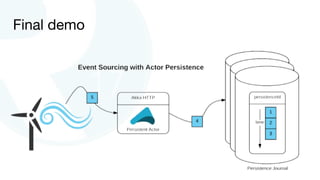



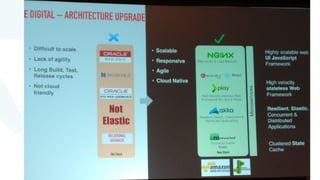






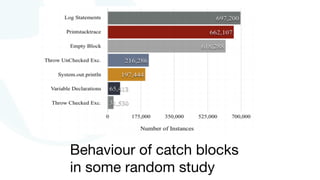






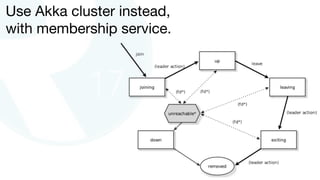






The document discusses advancements in fast data architecture and microservices, highlighting various tools and methodologies, such as Akka and streaming engines, to improve performance in real-time applications like financial services. It details specific case studies, including Capital One and Verizon, illustrating successful transitions from monolithic to microservices architectures. Additionally, the document outlines common anti-patterns in using Akka, focusing on best practices for effective implementation and system performance.








































![Introduction to Akka Streams [Part-I]](https://cdn.slidesharecdn.com/ss_thumbnails/babystepsinakkastreampart-i-171117070802-thumbnail.jpg?width=640&height=640&fit=bounds)






































