Download as PDF, PPTX




![Pick the Right Tool for The Job
Scala
Future[T]
Akka
ACTORS
Power
Constraints
Akka
Stream](https://image.slidesharecdn.com/reactivemistakes-scaladayschicago2017-170420225232/75/Reactive-mistakes-ScalaDays-Chicago-2017-5-2048.jpg)
![Pick the Right Tool for The Job
Scala
Future[T]
Akka
ACTORS
Power
Constraints
Akka
TYPED](https://image.slidesharecdn.com/reactivemistakes-scaladayschicago2017-170420225232/75/Reactive-mistakes-ScalaDays-Chicago-2017-6-2048.jpg)
![Pick the Right Tool for The Job
Scala
Future[T] Akka
TYPED
Akka
ACTORS
Power
Constraints
Akka
Stream](https://image.slidesharecdn.com/reactivemistakes-scaladayschicago2017-170420225232/75/Reactive-mistakes-ScalaDays-Chicago-2017-7-2048.jpg)
![Pick the Right Tool for The Job
Scala
Future[T]
Local Abstractions Distribution
Akka
TYPED
Akka
ACTORS
Power
Constraints
Akka
Stream](https://image.slidesharecdn.com/reactivemistakes-scaladayschicago2017-170420225232/75/Reactive-mistakes-ScalaDays-Chicago-2017-8-2048.jpg)
![Future Use Cases
● Local Concurrency
● Simplicity
● Composition
● Typesafety
Scala
Future[T]](https://image.slidesharecdn.com/reactivemistakes-scaladayschicago2017-170420225232/75/Reactive-mistakes-ScalaDays-Chicago-2017-10-2048.jpg)

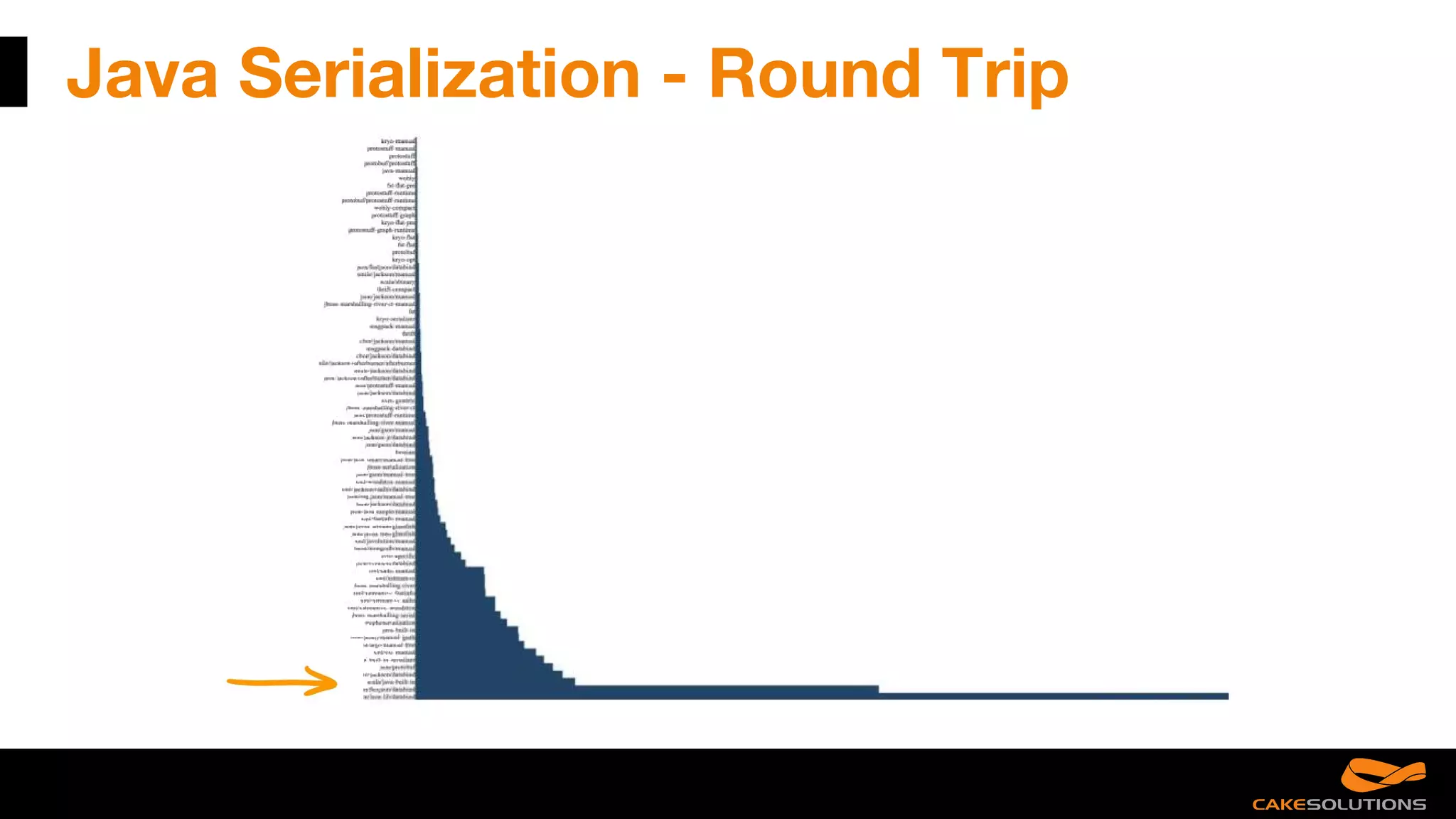
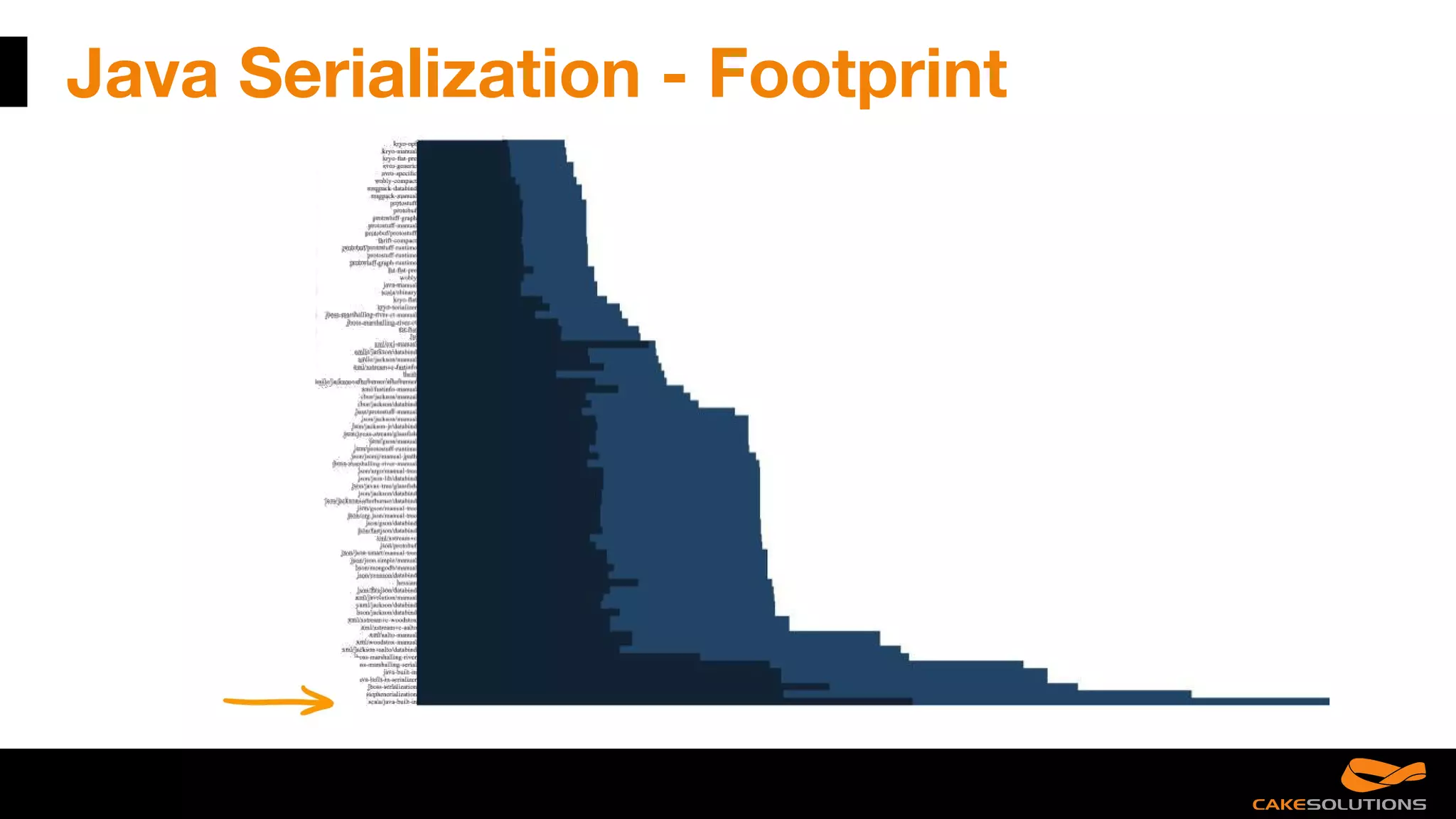
![Java Serialization - Footprint
case class Order (id: Long, description: String, totalCost: BigDecimal, orderLines: ArrayList[OrderLine], customer: Customer)
Java Serialization:
----sr--model.Order----h#-----J--idL--customert--Lmodel/Customer;L--descriptiont--Ljava/lang/String;L--orderLinest--Ljava/util
/List;L--totalCostt--Ljava/math/BigDecimal;xp--------ppsr--java.util.ArrayListx-----a----I--sizexp----w-----sr--model.OrderLine--
&-1-S----I--lineNumberL--costq-~--L--descriptionq-~--L--ordert--Lmodel/Order;xp----sr--java.math.BigDecimalT--W--(O---I--s
caleL--intValt--Ljava/math/BigInteger;xr--java.lang.Number-----------xp----sr--java.math.BigInteger-----;-----I--bitCountI--bitLe
ngthI--firstNonzeroByteNumI--lowestSetBitI--signum[--magnitudet--[Bxq-~----------------------ur--[B------T----xp----xxpq-~--x
q-~--
XML:
<order id="0" totalCost="0"><orderLines lineNumber="1" cost="0"><order>0</order></orderLines></order>
JSON:
{"order":{"id":0,"totalCost":0,"orderLines":[{"lineNumber":1,"cost":0,"order":0}]}}](https://image.slidesharecdn.com/reactivemistakes-scaladayschicago2017-170420225232/75/Reactive-mistakes-ScalaDays-Chicago-2017-16-2048.jpg)



![Binary formats [Schema-less]
● Metadata send together with data
● Advantages:
○ Implementation effort
○ Performance
○ Footprint *
● Disadvantages:
○ No human readability
● Kryo, Binary JSON (MessagePack, BSON, ... )](https://image.slidesharecdn.com/reactivemistakes-scaladayschicago2017-170420225232/75/Reactive-mistakes-ScalaDays-Chicago-2017-20-2048.jpg)
![Binary formats [Schema]
● Schema defined by some kind of DSL
● Advantages:
○ Performance
○ Footprint
○ Schema evolution
● Disadvantages:
○ Implementation effort
○ No human readability
● Protobuf (+ projects like Flatbuffers, Cap’n Proto, etc.), Thrift, Avro](https://image.slidesharecdn.com/reactivemistakes-scaladayschicago2017-170420225232/75/Reactive-mistakes-ScalaDays-Chicago-2017-21-2048.jpg)


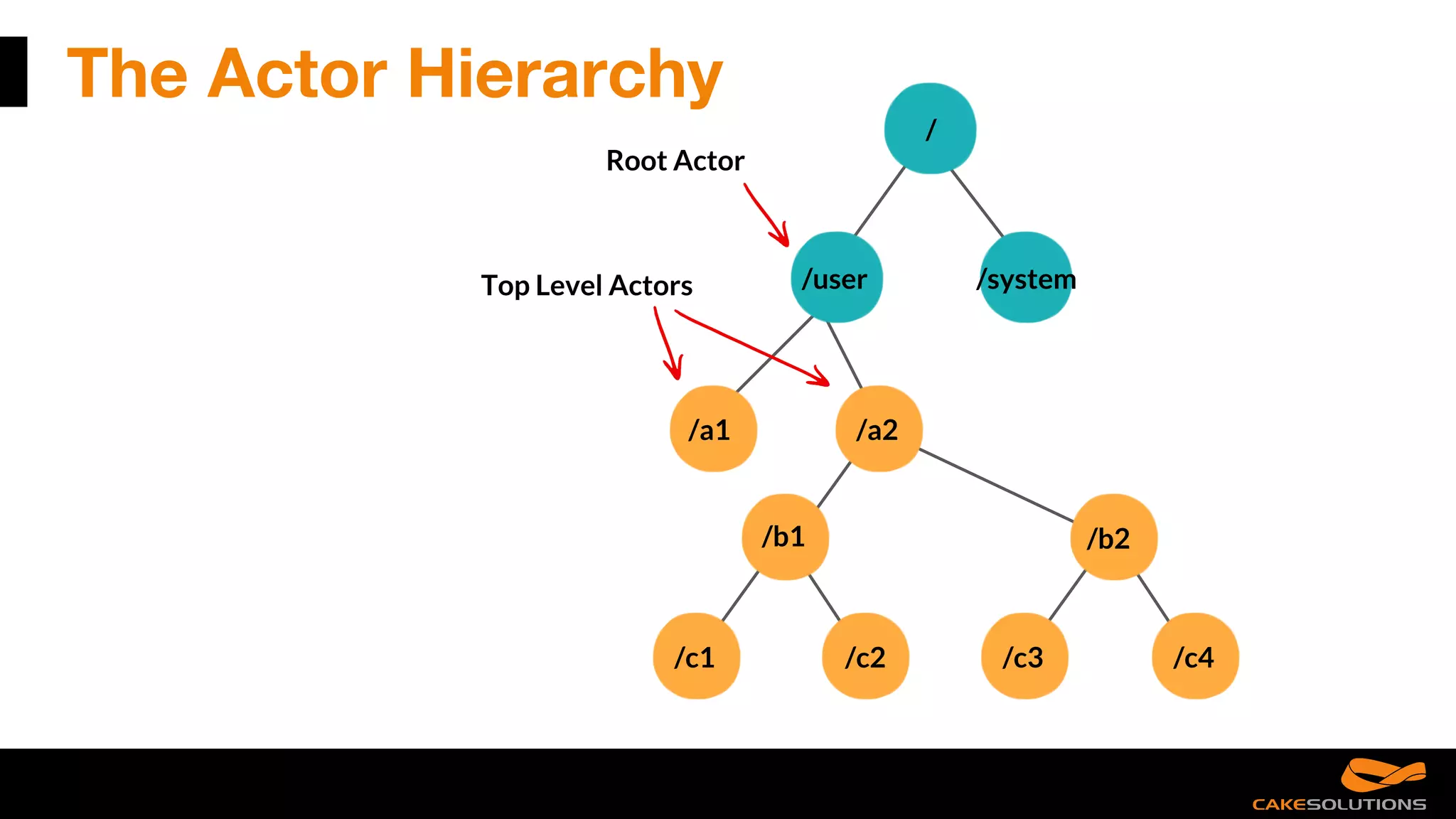


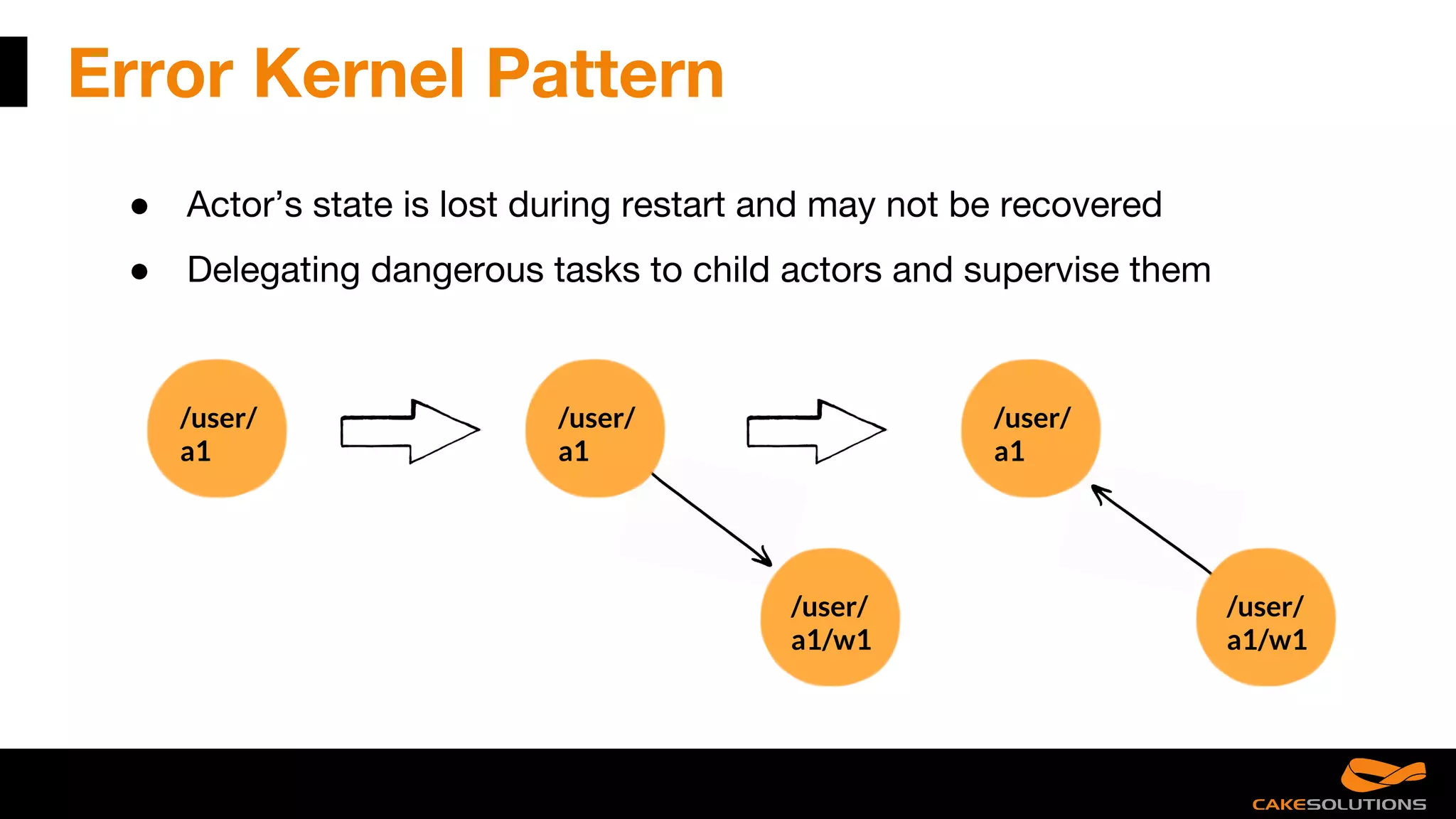







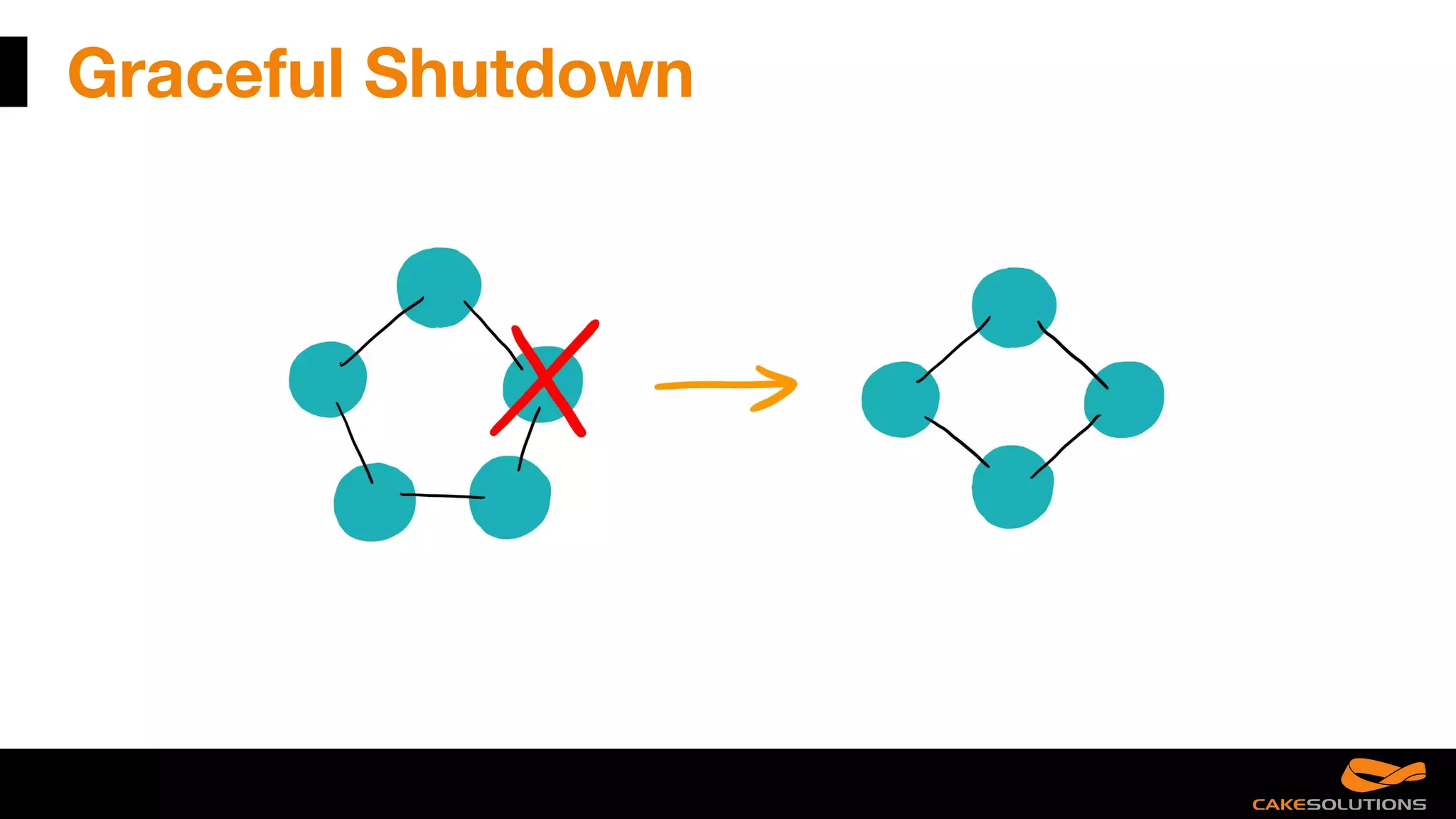











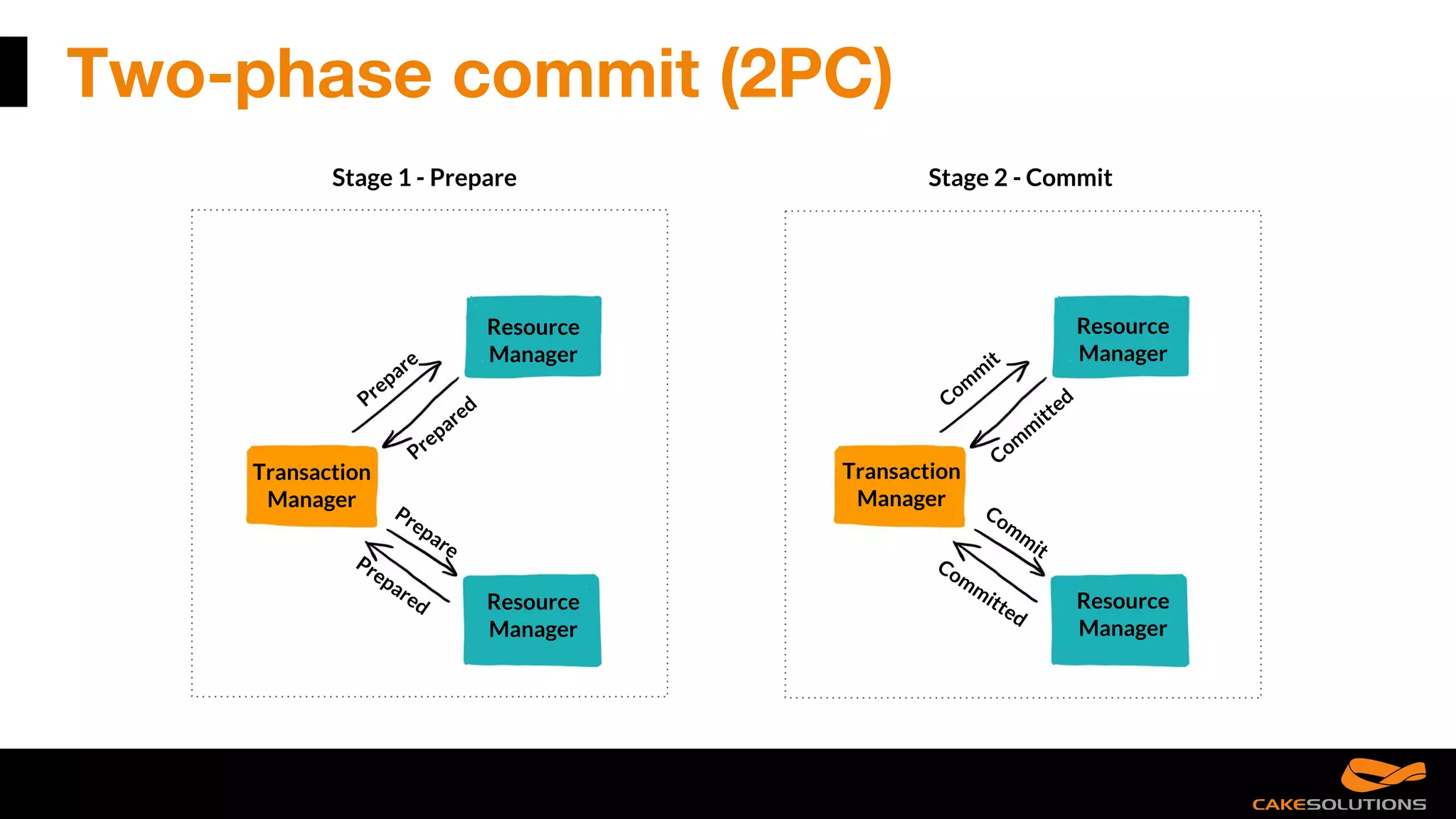







































The document discusses best practices for writing reactive applications using Akka and Scala, including actor models, serialization techniques, and handling concurrency. It covers common mistakes, such as improper serialization and error handling, alongside performance considerations related to distributed transactions and latencies. Additionally, it emphasizes the importance of graceful shutdown procedures and maintaining application resilience.












































































