Downloaded 15 times
![Building upon the Zemanta API Andraz Tori, CTO [email_address] Twitter: andraz](https://image.slidesharecdn.com/semweb-installfest-091115201559-phpapp02/85/SemWeb-install-fest-presentation-1-320.jpg)
![Building upon the Zemanta API Andraz Tori, CTO [email_address] Twitter: andraz](https://image.slidesharecdn.com/semweb-installfest-091115201559-phpapp02/75/SemWeb-install-fest-presentation-1-2048.jpg)
















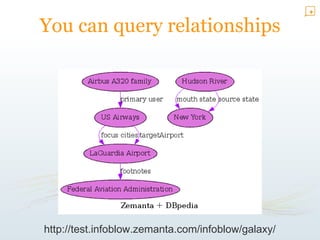
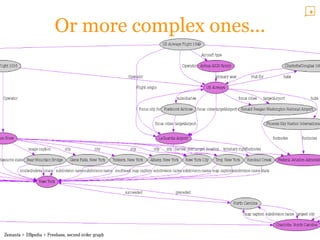



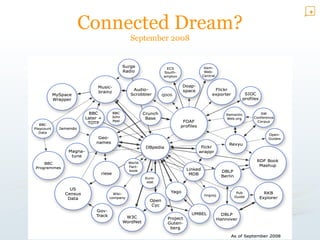













The document provides an overview of the Zemanta API, which processes text to extract semantic information like tags, categories, concepts, entities, and related articles and images. It analyzes natural language to identify meaningful data that can then be linked to external databases. The API aims to bridge human understandable text and computer-processable data through natural language processing and knowledge extraction techniques. It has a variety of uses including content discovery, automatic information delivery, and linking data across information networks.























































