Download as PDF, PPTX








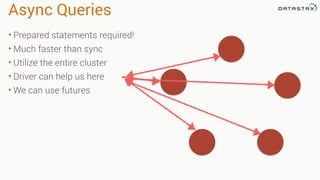

![1 from cassandra.concurrent import execute_concurrent_with_args
2
3 stmt = """SELECT * FROM sensor_data WHERE sensor_id=?
4 ORDER BY created_at DESC LIMIT 1""")
5
6 select_statement = session.prepare(stmt)
7
8 sensor_ids = [["f472d5ff-0c76-404a-8044-038db416685e"],
9 ["940cb741-d5b5-4c5d-82f5-bf1aa61c6d47"],
10 ["497d4b2c-cba2-4d0f-bd80-42de612690fd"],
11 ["1bdeac75-7e12-43ba-80b5-2d38405f9843"]
12
13 result = execute_concurrent_with_args(session, select_statement, sensor_ids)
Async Queries (managed)
prepared statement
automatically manages concurrency](https://image.slidesharecdn.com/pythonandcassandra-150319091009-conversion-gate01/85/Python-and-cassandra-10-320.jpg)















This document discusses integrating the Python driver for Cassandra into Python applications. It covers connecting to Cassandra, executing queries, prepared statements, asynchronous queries, object mapping with cqlengine, and best practices for application development including using virtual environments. The presentation aims to make working with Cassandra from Python straightforward and high performing.






















































































