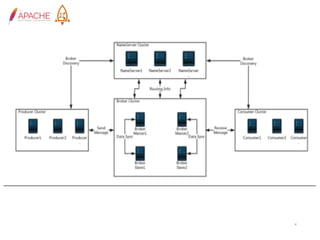
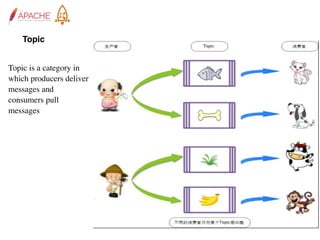
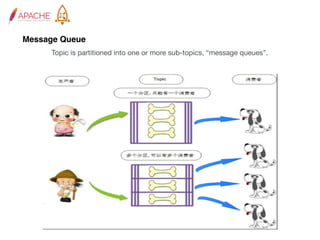
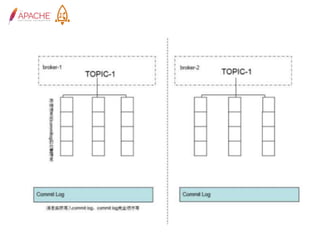
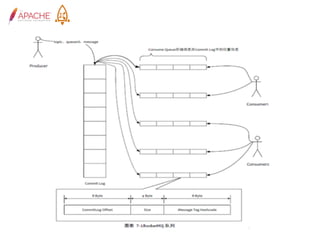
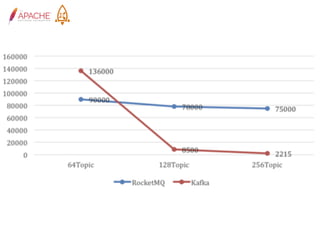
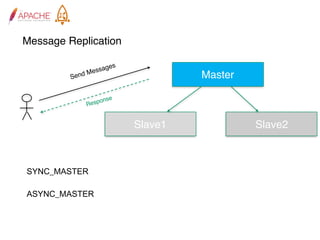
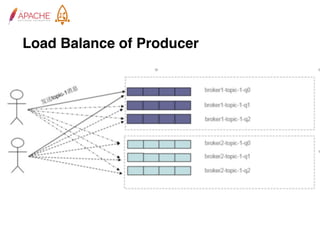
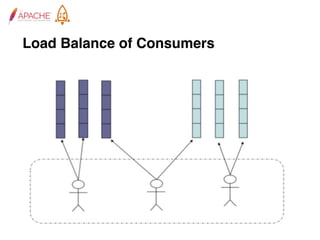
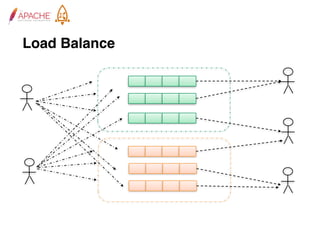
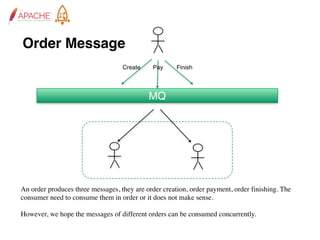
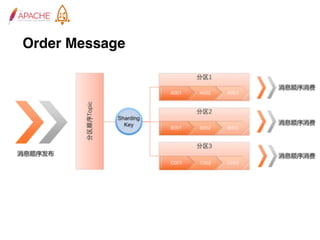
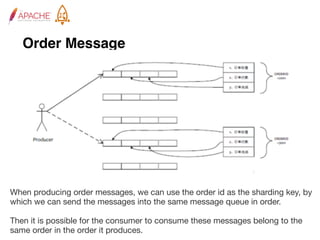
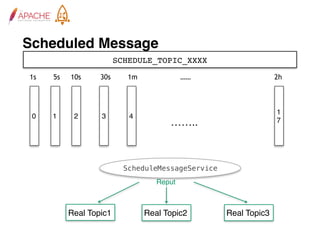
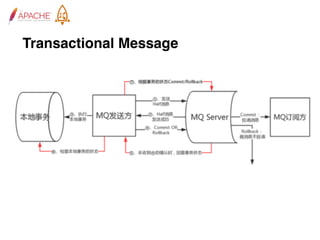
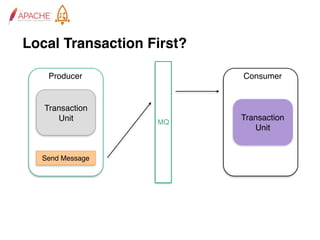
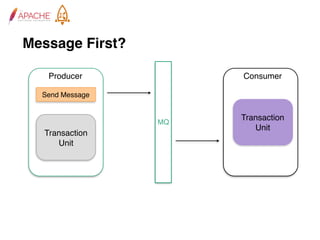
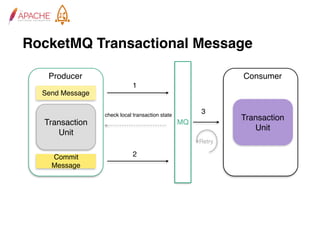
The document provides an overview of Apache RocketMQ, highlighting its core features, such as low latency, high availability, and massive message accumulation capacity. It outlines the roles of major components like name servers, brokers, and consumer groups, as well as message types, including ordered and scheduled messages. Additionally, it discusses transactional messaging, batch processing, and message filtering using SQL-based criteria.










![Log Appender
log4j.appender.mq=org.apache.rocketmq.logappender.log4j.RocketmqLog4jAppender
log4j.appender.mq.Tag=yourTag
log4j.appender.mq.Topic=yourLogTopic
log4j.appender.mq.ProducerGroup=yourLogGroup
log4j.appender.mq.NameServerAddress=yourRocketmqNameserverAddress
log4j.appender.mq.layout=org.apache.log4j.PatternLayout
log4j.appender.mq.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %-4r [%t]
(%F:%L) %-5p - %m%n
RocketMQ logappender provides log4j appender, log4j2 appender and
logback appender for bussiness to use, below are config examples.](https://image.slidesharecdn.com/1-171225114935/85/1-Core-Features-of-Apache-RocketMQ-28-320.jpg)



































![[OSC2016] マイクロサービスを支える MQ を考える](https://cdn.slidesharecdn.com/ss_thumbnails/event-161105054759-thumbnail.jpg?width=640&height=640&fit=bounds)

![[@NaukriEngineering] Messaging Queues](https://cdn.slidesharecdn.com/ss_thumbnails/queueprocessing-161111064335-thumbnail.jpg?width=640&height=640&fit=bounds)


































