Download as PDF, PPTX








![byte[] msgIdBytes = // Some byte
array
MessageId id =
MessageId.fromByteArray(msgIdBytes);
Reader<byte[]> reader =
pulsarClient.newReader()
.topic(topic)
.startMessageId(id)
.create();
Create a reader that will read from some
message between earliest and latest.
Reader
Reader Interface](https://image.slidesharecdn.com/osacon2022-streamingdatamadeeasy-timspanndavidkjerrumgaard-streamnative-221121203335-15e0ac66/85/OSA-Con-2022-Streaming-Data-Made-Easy-Tim-Spann-David-Kjerrumgaard-StreamNative-pdf-17-320.jpg)






![from pulsar import Function
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
import json
class Chat(Function):
def __init__(self):
pass
def process(self, input, context):
fields = json.loads(input)
sid = SentimentIntensityAnalyzer()
ss = sid.polarity_scores(fields["comment"])
row = { }
row['id'] = str(msg_id)
if ss['compound'] < 0.00:
row['sentiment'] = 'Negative'
else:
row['sentiment'] = 'Positive'
row['comment'] = str(fields["comment"])
json_string = json.dumps(row)
return json_string
Entire Function
Pulsar Python NLP Function](https://image.slidesharecdn.com/osacon2022-streamingdatamadeeasy-timspanndavidkjerrumgaard-streamnative-221121203335-15e0ac66/85/OSA-Con-2022-Streaming-Data-Made-Easy-Tim-Spann-David-Kjerrumgaard-StreamNative-pdf-30-320.jpg)


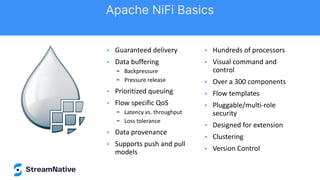
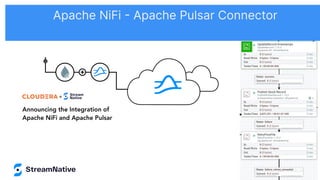
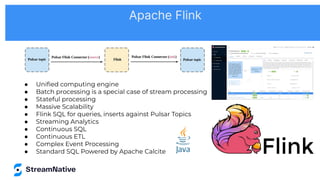


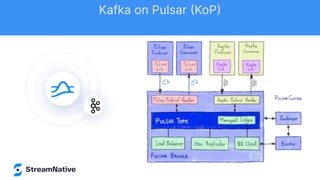
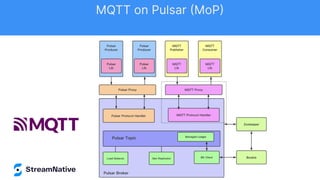
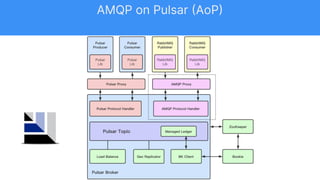






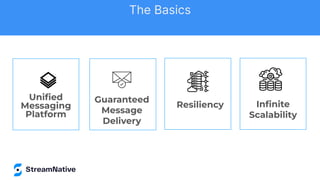
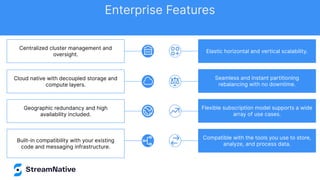
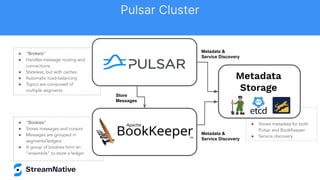
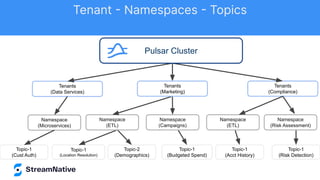
The document discusses the capabilities and architecture of Apache Pulsar, highlighting its robust community, growth, and enterprise features like message delivery and subscription models. It covers various components such as producers, consumers, schema management, and serverless functionalities, while emphasizing Pulsar's integration with other data processing technologies and protocols. Additionally, it outlines use cases and provides sample implementations, positioning Pulsar as a comprehensive solution for streaming data applications.
















![[March sn meetup] apache pulsar + apache nifi for cloud data lake](https://cdn.slidesharecdn.com/ss_thumbnails/marchsnmeetupapachepulsarapachenififorclouddatalake-220311125943-thumbnail.jpg?width=640&height=640&fit=bounds)


















































