Download to read offline










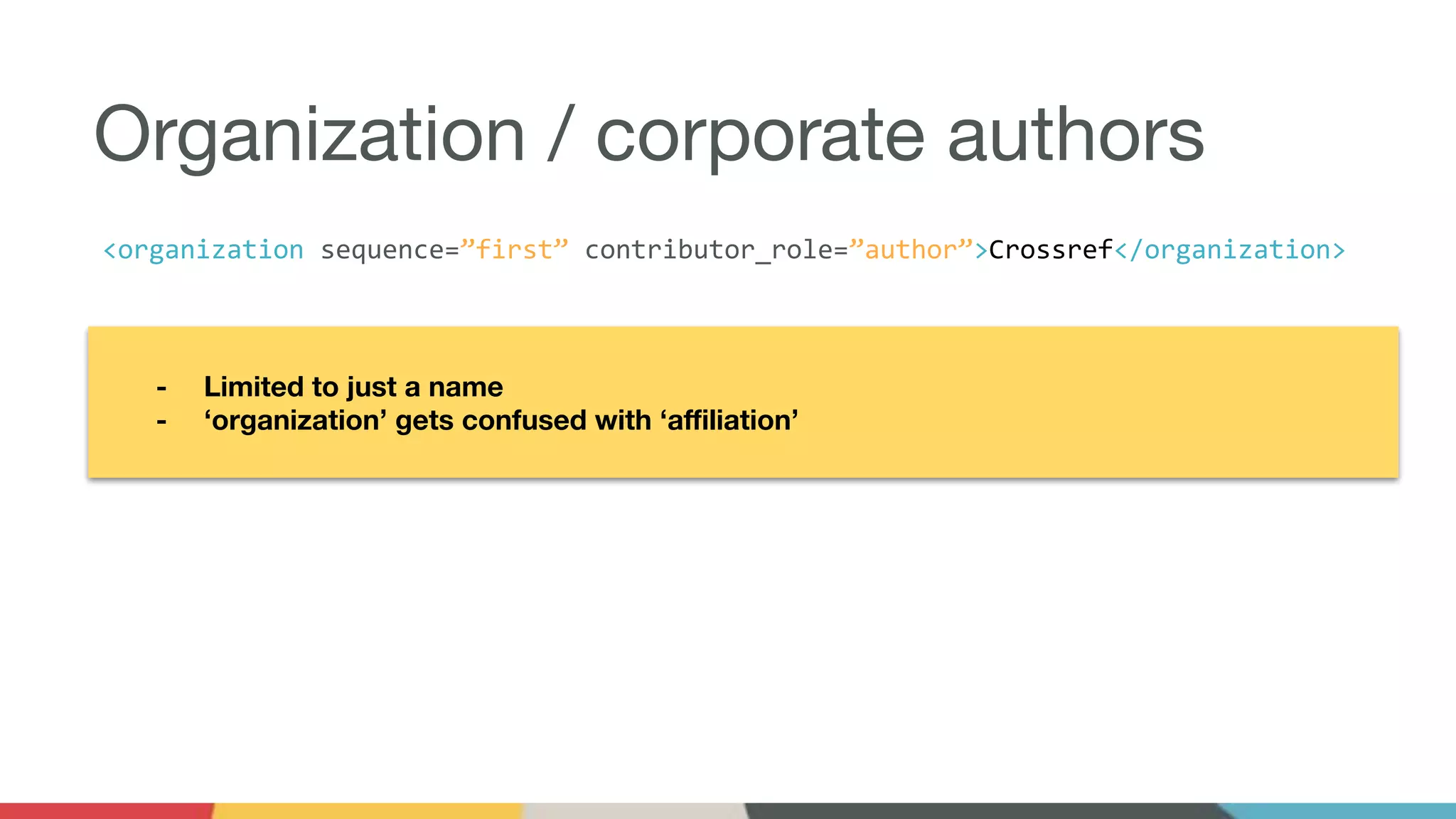









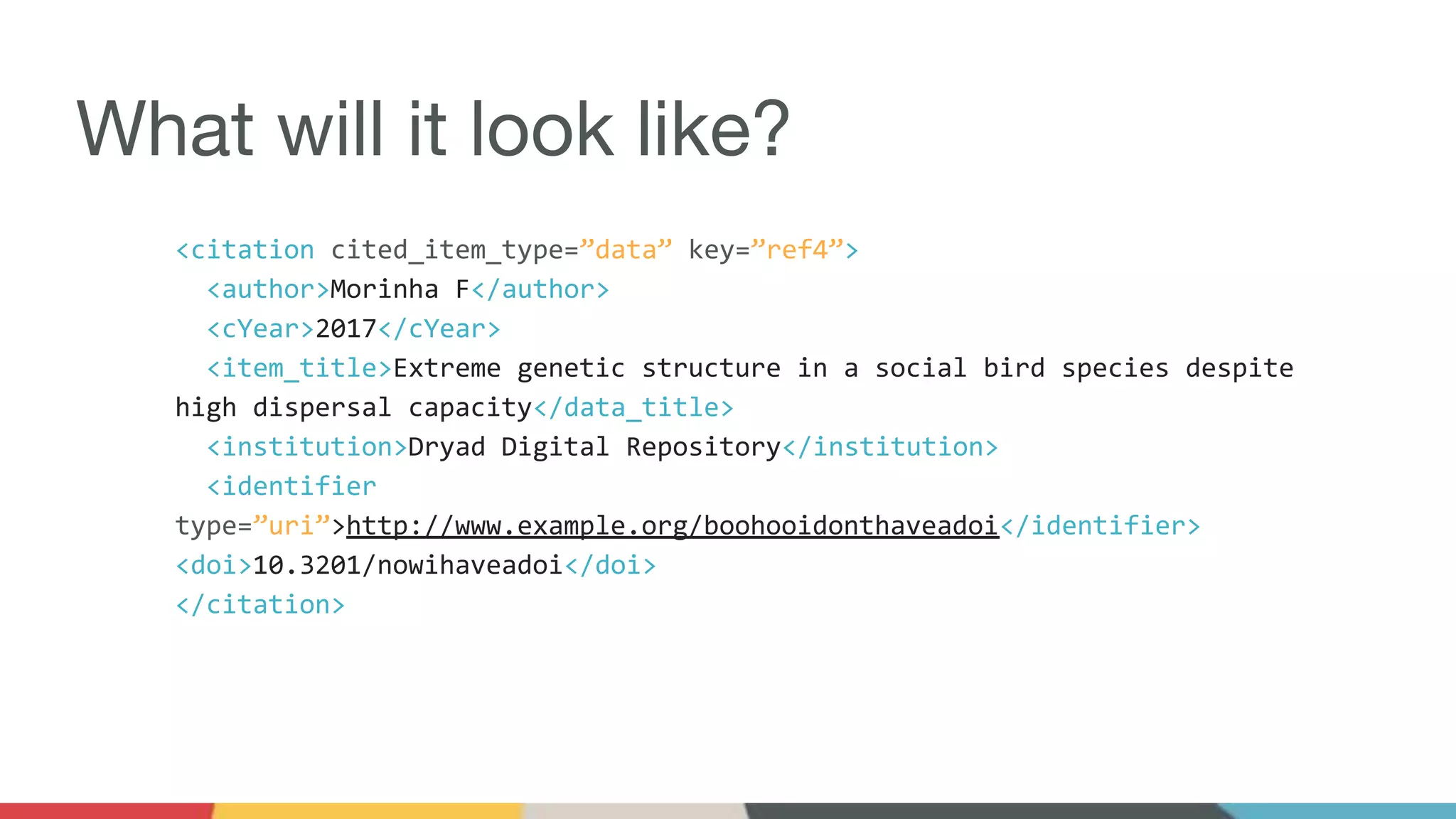










Crossref is soliciting community feedback on proposed schema changes aimed at improving identifier support, contributor attribution, and data citation guidelines. Key changes include enhanced support for various identifiers, the introduction of contributor roles, and expanded affiliation details, all while striving for backwards compatibility. The initiative also plans to introduce new content types and metadata practices, with a focus on collaborative feedback and development leading up to the final implementation.



















































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)



