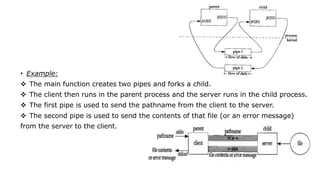
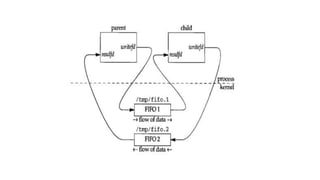
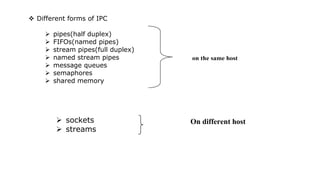
The document provides an overview of inter-process communication (IPC) methods used in operating systems, detailing various forms such as pipes, FIFOs, and shared memory. It explains the limitations of pipes, including their half-duplex nature and the need for a common ancestor between processes, while highlighting FIFOs as a solution for unrelated processes with paths associated. The text also outlines the creation and operational processes for both pipes and FIFOs, emphasizing their functionality in facilitating communication between processes.





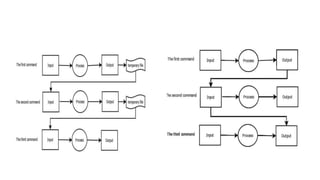
![• When a two-way flow of data is desired, we must create two
pipes and use one for each direction. The actual steps are as
follows:
• 1. create pipe 1 (fd1[0] and fd2[1]), create pipe 2
• (fd2[0] and fd1[1]),
• 2. fork,
• 3. parent closes read end of pipe 1 (fd1[0]),
• 4. parent closes write end of pipe 2 (fd2[1]),
• 5. child doses write end of pipe 1 (fd1[1]),
• 6. child closes read end of pipe 2 (fd2[0]).](https://image.slidesharecdn.com/unitv-240519102123-75e6db5b/85/Process-Communication-IPC-in-LINUX-Environments-7-320.jpg)