Downloaded 33 times





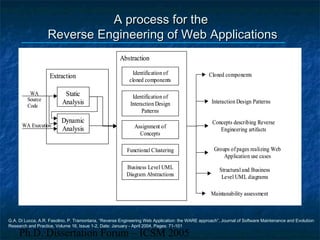

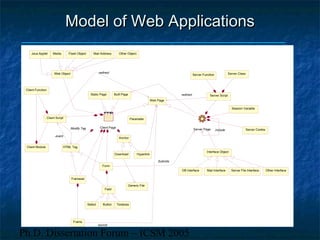
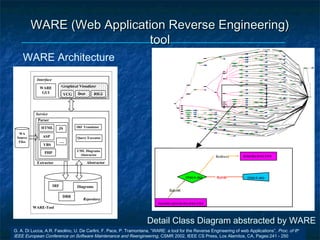




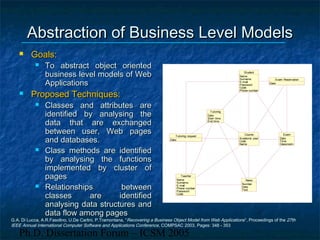




The dissertation focuses on reverse engineering web applications to address maintenance and quality assessment challenges due to the legacy of immature design methodologies. It proposes models, methods, and tools for reverse engineering and comprehension, emphasizing static and dynamic analysis techniques, functional clustering, and concept identification. Future work includes dynamic analysis, accessibility assessments, and migration to web services.





























































































